
Journal of Geo-information Science >
Research on Three Dimensional City Model Data Partitioning and Distributed Storage
Received date: 2014-07-15
Request revised date: 2015-07-26
Online published: 2015-12-20
Copyright
With the rapid development of information acquisition technology, the geographic information data is increasing at the magnitude of terabyte every day. As an important content of 3D GIS, 3D city model data plays an important role in the construction of digital city and smart city. Because the data structure of 3D city model is complex and the data volume is huge, how to efficiently divide and store large amount of 3D city model data in order to meet the long-term management of data, the rapid visualization of data scheduling and the requirement of spatial assistant decision-making of 3D GIS system, has become a research hotspot in recent years. Previous data partitioning methods have caused the changes of zoning frequently in the data scheduling, which makes the update and management of data become more difficult. So, it is necessary to find out a more stable and universal data partitioning method. In this paper, based on the research of the shortcomings for the existing 3D city model data partitioning methods, we proposed the large scale map partition method based on topology relation model, and then we designed a unified name encoding scheme for the 3D models data after splitting. With the help of the powerful massive data organization and efficient multiple concurrent access function of the non-relational database MongoDB, a MongoDB sharded cluster server is constructed. The 3D city model data was used in unit division, and the rules modeling software City Engine was applied to processing the divided units, thus producing the 3D city model. Afterwards, MongoDB was used for data storage experiments. The results show that the large scale map partition method based on topology relation model is capable and sutable for the data partition of 3D city model, and the storage efficiency of the divided data is obviously improved. Moreover, the MongoDB database has a good stability on multiple concurrent access.
Key words: 3DCM; data partition; spatial topological relations; spatial database; MongoDB
LI Chaokui , YAN Wenying , YIN Zhihui , CHEN Guo . Research on Three Dimensional City Model Data Partitioning and Distributed Storage[J]. Journal of Geo-information Science, 2015 , 17(12) : 1442 -1449 . DOI: 10.3724/SP.J.1047.2015.01442
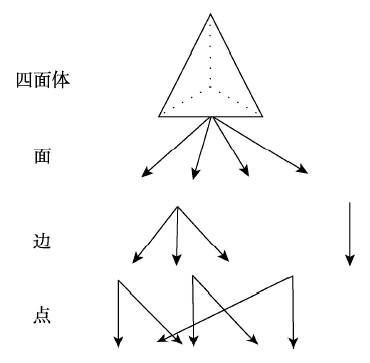
Fig. 1 The hierarchical diagram of B-REP model图1 B-REP模型分级图 |
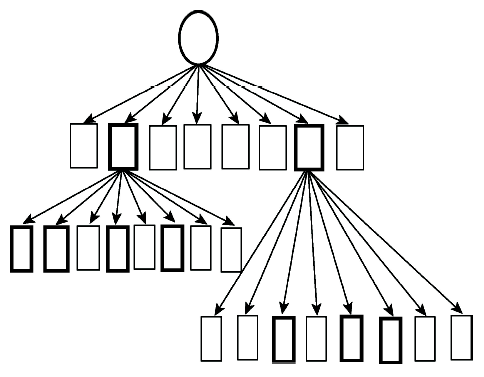
Fig. 2 The Octree model图2 八叉树(Octree)模型 |
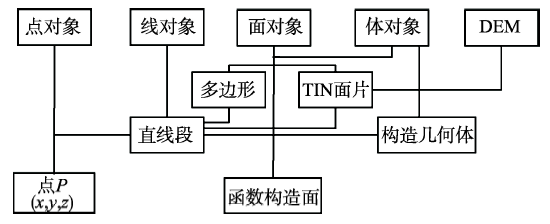
Fig. 3 The geometry spatial data model of 3DCM图3 3DCM几何空间数据模型 |
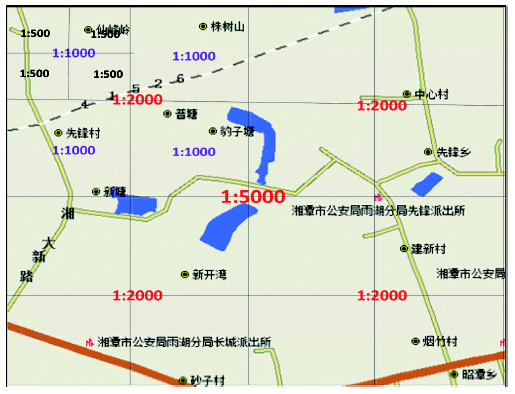
Fig. 4 The modeling unit division based on 2 km×2 km map sheet图4 基于2 km×2 km图幅的建模单元划分 |
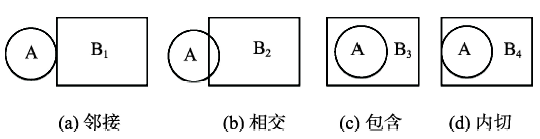
Fig. 5 Four kinds of basic relationship between object and map图5 地物与图幅的4种基本关系 |
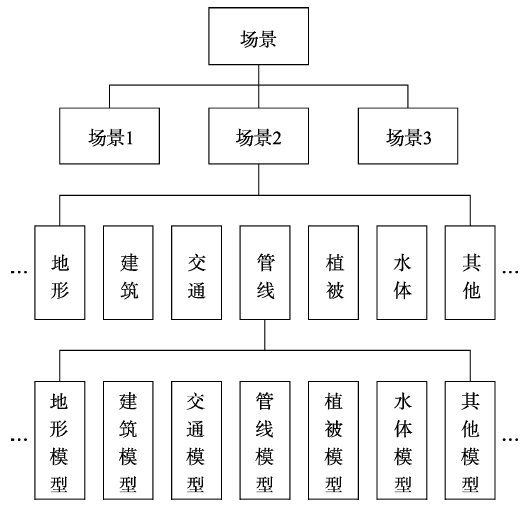
Fig. 6 The organization chart of 3D model图6 三维模型组织结构 |
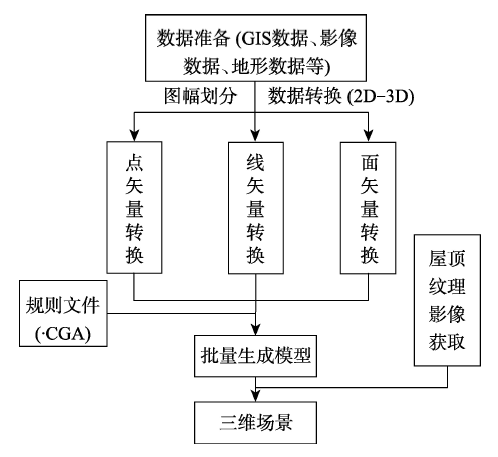
Fig. 7 Rule-based modeling procedure of CityEngine图7 基于规则的CityEngine建模流程 |
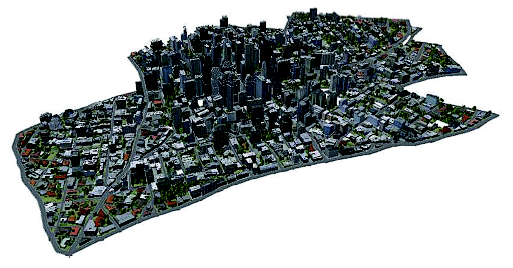
Fig. 8 The construction achievements of 3DCM图8 构建的三维城市模型 |
Tab. 1 The cluster environment of MongoDB表1 MongoDB集群环境 |
| 服务器编号/IP | 路由服务器端口 | 配置服务器端口 | 分片/端口 |
|---|---|---|---|
| 1:192.168.0.1 | Mongos1:10000 | Configdb1:20 000 | Shard1:27 001 Shard2:27 002 |
| 2:192.168.0.2 | Mongos2:10000 | Configdb2:20 000 | Shard1:27 001 Shard2:27 002 |
| 3:192.168.0.3 | Mongos3:10000 | Configdb3:20 000 | Shard1:27 001 Shard2:27 002 |
Tab. 2 The comparison of image data storage time表2 影像数据入库时间对比 |
| 数据量(MB) | 时间(s) | |
|---|---|---|
| Mongo DB | SQL Server 2005 | |
| 500 | 98.231 | 173.962 |
| 2000 | 327.917 | 631.674 |
| 4217 | 745.483 | 1752.790 |
Tab. 3 The data storage time comparison of different methods表3 不同处理方法数据入库时间对比 |
| 模型种类 | 数据大小(GB) | 入库时间(s) |
|---|---|---|
| ① | 11.7 | 1257.695 |
| ② | 12.1 | 1309.553 |
| ③ | 20.5 | 2478.391 |
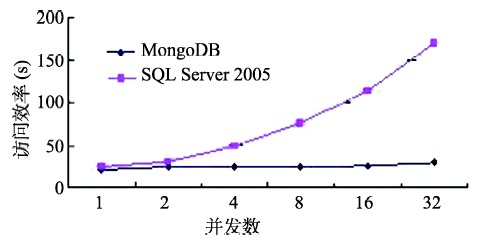
Fig. 9 The time efficiency comparison chart of simulating multiple concurrent access图9 模拟多并发访问时间效率对比 |
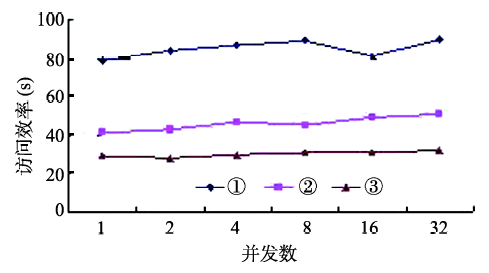
Fig. 10 The comparison of efficiencies for multiple concurrent access with different processing methods图10 不同处理方法的数据多并发访问效率对比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}