
Journal of Geo-information Science >
A New Multi-level Spatial Index of Scattered Point Cloud Data
Received date: 2015-10-09
Request revised date: 2015-11-06
Online published: 2015-12-20
Copyright
Laser scanning technology has been widely used in cultural relic protection because of its speed, accuracy, non-touch, real-time and automatism. As the product of laser scanning, point cloud data has the following characteristics: a large amount of data (mass), high spatial resolution and no topological relations between the three dimensional points (scattering). Point cloud data must be processed before using. Point cloud data processing includes de-noising, registration, merge, segmentation and so on. Neighborhood searching will be frequently needed during the procedure of point cloud data processing. Therefore, the data must be organized and the spatial index should be constructed to improve the speed of neighborhood searching and query. Currently, the main algorithms of three dimensional spatial indexing for point cloud data are regular grid, quadtree, octree, KD-tree, R-tree and so on. Among these algorithms, the octree and KD-tree are used most frequently. The octree algorithm is easy to be applied and is adaptive to the data with an evenly distributing tendency. But considering the irregular distributing point cloud data in ancient architectures, it is proved to be inefficient. KD-tree is the extension of the binary tree. It divides the space based on the data distribution rather than divides the space into two parts rigidly such as the quad-tree and octree. It is more efficient in neighborhood searching. But taking into a large amount of data, the depth of KD-tree will be too big to conduct neighborhood searching efficiently. Since the single spatial index cannot adapt to all types of data, the multi-level spatial index is a hot spot of current studies. According to the merits and demerits of existing spatial index algorithms, a new composed index of multi-grid and KD-tree was proposed. The algorithm integrates the developing regular grid index and KD-tree index. It is easily applied and very efficient for neighborhood searching. Through an experiment using the Forbidden City data, compared with the KD-tree index and octree index, the newly proposed index was proved to perform better than the KD-Tree index and octree index with respect to neighborhood searching efficiency.
Key words: point cloud data; spatial index; neighborhood search; KD-tree; octree
ZHAO Jianghong , WANG Jiwei , WANG Yanmin , GUO Ming . A New Multi-level Spatial Index of Scattered Point Cloud Data[J]. Journal of Geo-information Science, 2015 , 17(12) : 1450 -1455 . DOI: 10.3724/SP.J.1047.2015.01450
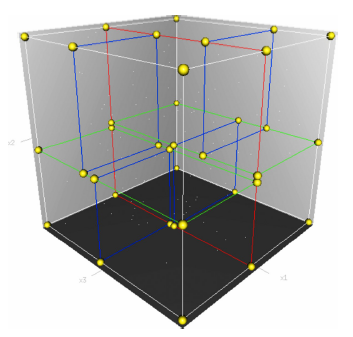
Fig. 1 K-D tree construction of 3D point cloud data图1 三维点云的KD树构建过程 |
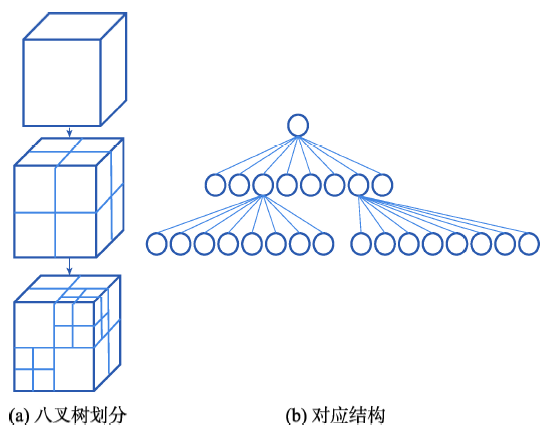
Fig. 2 Octree space divisionand the structural representation of the octree图2 八叉树划分其对应结构示意图 |
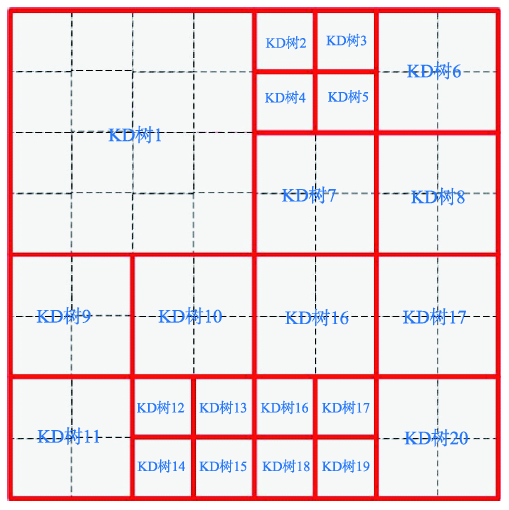
Fig. 3 Relationship between grid, reign and KD-tree图3 格网、区域及KD树的关系 |
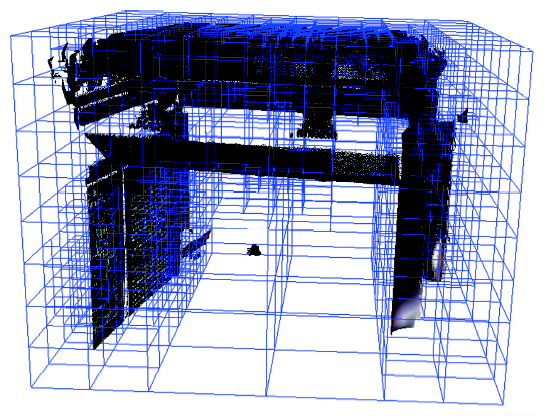
Fig. 4 A memorial archway of Taihe Palace图4 太和殿外南面牌坊 |
Fig. 5 The gate of Supreme Harmony图5 太和门内房屋 |
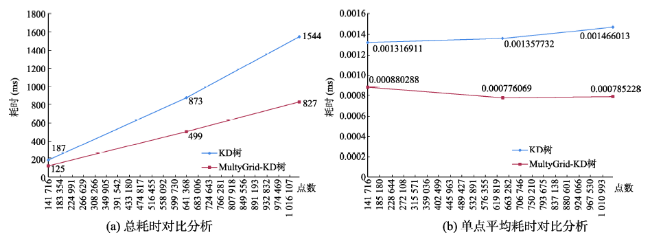
Tab. 1 Time cost of the index location (ms)表1 索引定位的耗时(ms) |
| 点数 | KD树 | MultiGrid-KD树 | |||||
|---|---|---|---|---|---|---|---|
| 总耗时 | 平均单点耗时 | 一级索引耗时 | KD树索引耗时 | 总耗时 | 平均单点耗时 | ||
| 141 999 | 187 | 0.00131691 | 16 | 109 | 125 | 0.000880288 | |
| 642 984 | 873 | 0.00135773 | 47 | 452 | 499 | 0.000776069 | |
| 1 053 197 | 1544 | 0.00146601 | 93 | 734 | 827 | 0.000785228 | |
Fig. 6 Analysis of index location time cost图6 索引定位的耗时分析 |
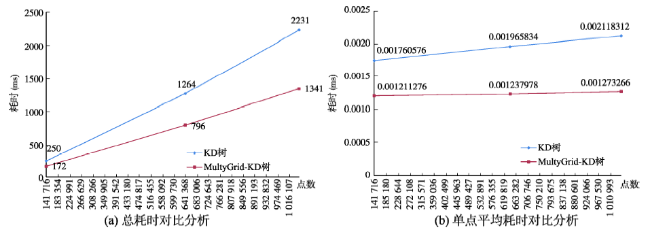
Fig. 7 Analysis of the nearest distance inquiry图7 最近距离点查询分析 |
Tab. 2 Time cost of the nearest distance inquiry (ms)表2 最近距离查询耗时(ms) |
| 点数 | KD树 | MultiGrid-KD树 | |||
|---|---|---|---|---|---|
| 总耗时 | 平均单点耗时 | 总耗时 | 平均单点耗时 | ||
| 141 999 | 250 | 0.001760576 | 172 | 0.001211276 | |
| 642 984 | 1264 | 0.001965834 | 796 | 0.001237978 | |
| 1 053 197 | 2231 | 0.002118312 | 1341 | 0.001273266 | |
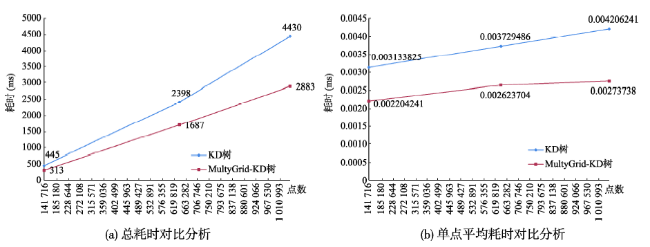
Tab. 3 Time cost of the four nearest neighborhoods inquiry (ms)表3 四邻域查询耗时(ms) |
| 点数 | KD树 | MultiGrid-KD树 | |||
|---|---|---|---|---|---|
| 总耗时 | 平均单点耗时 | 总耗时 | 平均单点耗时 | ||
| 141 999 | 445 | 0.003133825 | 313 | 0.002204241 | |
| 642 984 | 2398 | 0.003729486 | 1687 | 0.002623704 | |
| 1 053 197 | 4430 | 0.004206241 | 2883 | 0.002737380 | |
Fig. 8 Analyze of Four Neighborhood Distance Inquiry图8 四邻域查询分析 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}