
Journal of Geo-information Science >
Resource Storage and Management Method of Massive Remote Sensing Data Supported by the Big Data Architecture
Received date: 2015-12-15
Request revised date: 2016-01-11
Online published: 2016-05-10
Copyright
The ability to acquire the remote sensing data is increasing day by day, which directly causes the remote sensing data to become diverse and massive, and the issue that the massive amount of data is being non-affordable to store has become more and more prominent. On the other hand, due to the lack of an effective and efficient method of storage management, the data that theterminal application need is difficult to found in a timely manner, therefore, is stored but useless. This paper focuses on the storage and management problems of the massive, high through put and spatially structured remote sensing data and the basic land information products. We have presented a storage and management method which uses the big data structure and can integrate both the vector and raster data. Based on the MongoDB database, the prototype system is realized and we use the data of PB rangeto test it. Eventually, we have proved that this method meets the demand for the storage and management of the remote sensing vector-raster data in the era of big data. On the basis of the study results and prototype system, the following studies need to be further explored: (1) The organization and management methods for internal data of resources, especially the objective and timely management for the vector data; (2) Real-time interactive visualization methods for different data types and storage modes of resources, achieving dynamic extraction and rendering ability based on in the heterogeneous data model; (3) To construct large data computing architecture on the heterogeneous type storage mode, and to implement multimodal computing framework to meet the needs of the remote sensing applications require.
HU Xiaodong , ZHANG Xin , QU Jingsheng . Resource Storage and Management Method of Massive Remote Sensing Data Supported by the Big Data Architecture[J]. Journal of Geo-information Science, 2016 , 18(5) : 681 -689 . DOI: 10.3724/SP.J.1047.2016.00681
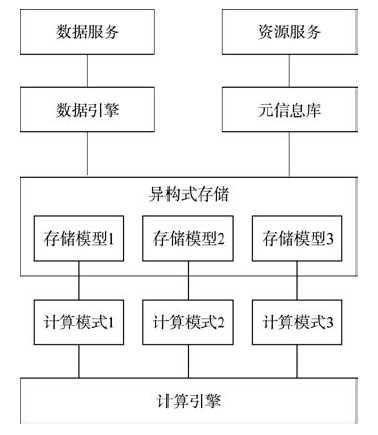
Fig. 1 Storage management model for the remote sensing big data图1 遥感大数据存储管理模式 |
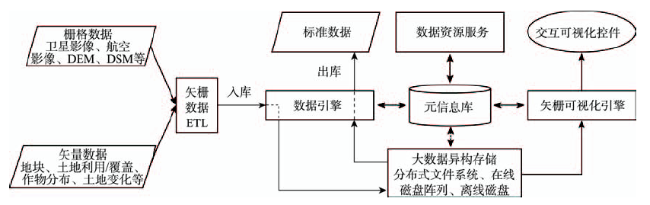
Fig. 2 General framework of the integrated storage management for massive remote sensing data图2 遥感资源存储管理总体框架 |
Fig. 3 The ETL process for remote sensing image data图3 遥感影像ETL过程 |
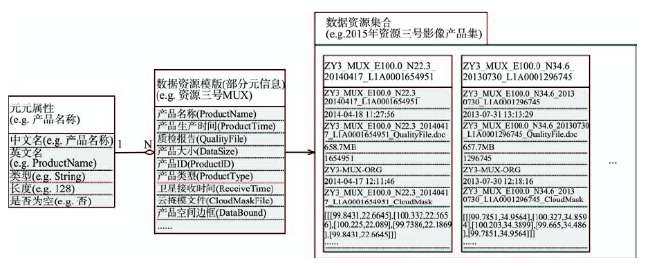
Fig. 4 Organization structure of remote sensing resource meta-information图4 遥感资源元信息组织结构示意图 |
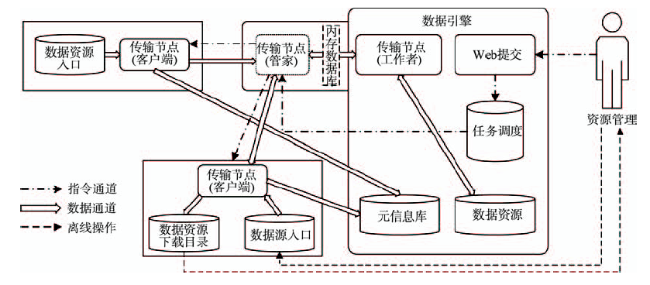
Fig. 5 The workflow of data engine图5 数据引擎工作流程 |
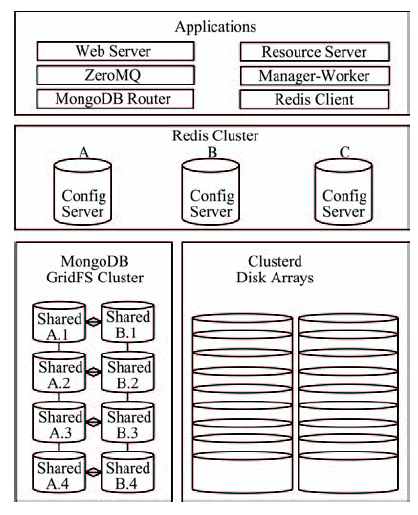
Fig. 6 The deployment diagram of the prototype system图6 原型系统部署图 |
Tab. 1 Remote sensing resource list stored and managed in the prototype system表1 原型系统存储管理的遥感资源清单 |
| 序号 | 资源代号 | 资源类型 | 资源数量/个 | 产品容量/GB |
|---|---|---|---|---|
| 1 | ZY3-MUX-ORG | 资三多光谱原始影像 | 17 896 | 16 132.17 |
| 2 | ZY3-NAD-ORG | 资三全色原始影像 | 17 896 | 29 163.93 |
| 3 | GF1-WFV-ORG | 高分1号16 m原始影像 | 77 568 | 178 889.47 |
| 4 | GF1-PMS-ORG | 高分1号2 m/8 m原始影像 | 42 960 | 100 607.40 |
| 5 | ZY02c-HRC-ORG | 资源02c全色原始影像 | 8058 | 13 754.70 |
| 6 | ZY02c-PMS-ORG | 资源02c多光谱原始影像 | 8058 | 3979.31 |
| 7 | ZY3-MUX-DOM | 资三多光谱正射 | 17 896 | 8854.23 |
| 8 | ZY3-NAD-DOM | 资三全色正射 | 17 896 | 17 620.02 |
| 9 | GF1-WFV-DOM | 高分1号16 m正射 | 77 568 | 245 449.84 |
| 10 | GF1-MSS-DOM | 高分1号8 m多光谱正射 | 42 960 | 71 304.00 |
| 11 | GF1-PAN-DOM | 高分1号2 m全色正射 | 42 960 | 73 307.41 |
| 12 | GF1-DOM-FUS4 | 高分1号4波段融合 | 42 960 | 293 275.54 |
| 13 | ZY3-DOM-FUS4 | 资三4波段融合 | 17 896 | 140 960.18 |
| 14 | Landuse | 基础土地利用 | 14 | 8226.40 |
| 15 | Road | 道路信息 | 14 | 3018.40 |
| 16 | Water | 水系信息 | 14 | 3313.80 |
| 17 | Farmland | 农业应用信息 | 3 | 442.50 |
| 总计 | 432 617 | 1 208 299.30 | ||
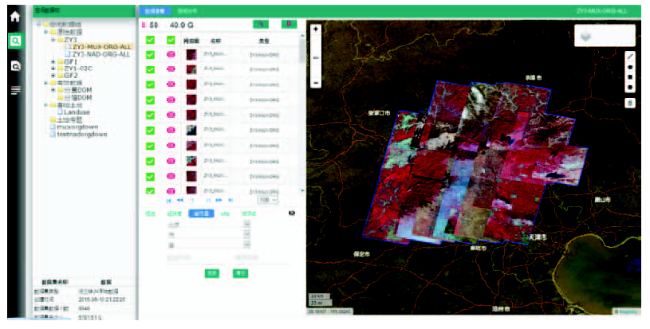
Fig. 7 The query results shown in the prototype system图7 原型系统查询结果显示 |
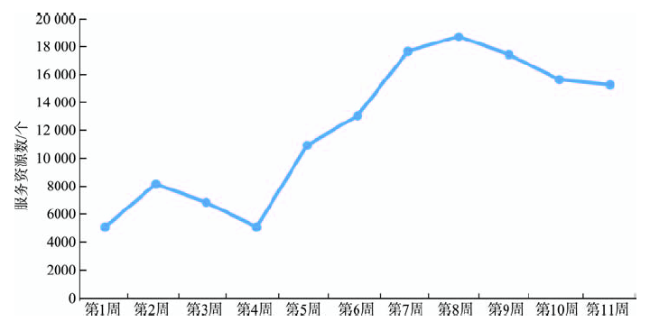
Fig. 8 Statistical chart of the weekly service on remote sensing data resource图8 遥感数据资源周服务量统计图 |
Tab. 2 Comparison betweeen three remote sensing big data storage management methods表2 遥感大数据存储管理方案对比 |
| 方案 | 模式特点 | 极限容量 | 扩展能力 | 空间支持 | 吞吐能力 |
|---|---|---|---|---|---|
| ArcGIS 10.0 | 集中式,存储计算服务功能齐全 | 百TB级 | 弱 | 强 | 弱 |
| Hadoop 0.20.1 | 分布式,存储计算一体化 | PB级 | 强 | 弱 | 强 |
| 本文方案 | 异构式,存储计算服务异构分离 | PB级 | 强 | 一般 | 强 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
|
| [11] |
[
|
| [12] |
|
| [13] |
[
|
| [14] |
|
| [15] |
|
| [16] |
[
|
| [17] |
国家测绘局. CH/T 1007-2001,基础地理信息数字产品元数据[S].北京:国家基础地理信息中心,2001:1-24.
[ State Bureau of Surveying and Mapping. CH/T 1007-2001, metadata for digital products of fundamental geographic information[S]. Beijing: National Geomatics Center of China, 2001:1-24. ]
|
| [18] |
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}