
Journal of Geo-information Science >
Plot-level Forest Height Inversion Using Airborne LiDAR Data Based on the Random Forest
Received date: 2015-10-26
Request revised date: 2016-02-23
Online published: 2016-08-10
Copyright
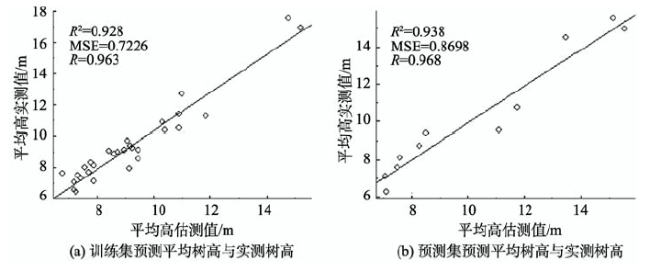
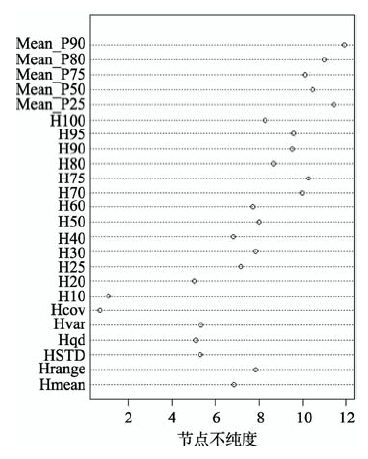
It has been a hot study field to extract forest structure parameter using Airborne LiDAR. This paper evaluated the validity of random forests technique (RF) in the estimation of forest height, based on both of the physical and statistical features of airborne LiDAR data with the utilization of a new detection method to find the crown height. The study area was selected to be the Zhuxi river basin of Changting county in Fujian Province. At first, the ground point dataset, vegetation and elevation normalized vegetation point dataset of stands were generated by using the progressive TIN filter algorithm. Then, 24 independent variables, such as the percentile of heights and the statistical metrics of points, were derived from the normalized vegetation point dataset. Based on the 24 laser-derived features and the field data, the estimation model for the random forest regression of the mean canopy height in the study area was established. 29 of the samples were used to construct the prediction model, and the remaining 11 samples were used to verify the accuracy of the model. Finally, we compared the average value of the estimated tree heights in each plot with the measured values. The result showed that they were highly correlated with each other, the regression coefficient between them was 0.938, and the correlation coefficient was 0.968. The accuracies of all plots were higher than 87% and the total average accuracy was 93.17%. Moreover, the importance of each variable was calculated in this paper to evaluate the accuracy of model estimation closely. And a conclusion was drawn that the importance of the variable sand the model estimation accuracy were positive correlated, which implies that the greater the importance of the variables, the greater their impact on the accuracy of the model estimation. Among all variables, the Mean_P90 and the percentiles between 70%~95% were representatively having a great influence on the accuracy of model estimation. According to the results, it was concluded that the estimation model of forest height based on random forest technique (RF) with multi-factor was proved to be feasible and efficient.
LU Lin , ZHOU Xiaocheng , YU Zhizhong , HAN Shang , WANG Xiaoqin . Plot-level Forest Height Inversion Using Airborne LiDAR Data Based on the Random Forest[J]. Journal of Geo-information Science, 2016 , 18(8) : 1133 -1140 . DOI: 10.3724/SP.J.1047.2016.01133
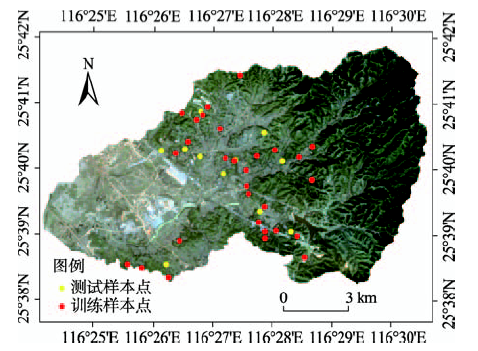
Fig.1 Distribution of the study plots图1 样地分布图 |
Tab.1 Independent variable metrics extracted from the LiDAR points.表1 从植被点云中获取的自变量指标 |
| 点云变量 | 变量描述 |
|---|---|
| Hmean | 点云高度的均值 |
| Hrange | 点云高度分布范围,计算公式为: |
| HSTD | 点云高度标准差,计算公式: |
| Hqd | 点云四分位高度偏差,计算公式: |
| Hvar | 点云高度方差,计算公式: |
| Hcov | 点云高度的变化系数,计算公式: |
| H100 | 点云高度最大值 |
| H10、H20、···、H95 | 点云的百分位高度值,即所有点云10%、20%、25%、30%、40%、···、95%处对应的高度值 |
| Mean_P25、···、Mean_P90 | 点云各百分位高度处对应点云高度的均值,如Mean_P25表示为所有大于H25的点云的平均值 |
注:n为每个样地对应归一化植被点云的个数;为每个植被点对应的高度值;为点云高度均值;为样地内点云高度的上四分位数;为样地内点云高度的较小四分位数 |
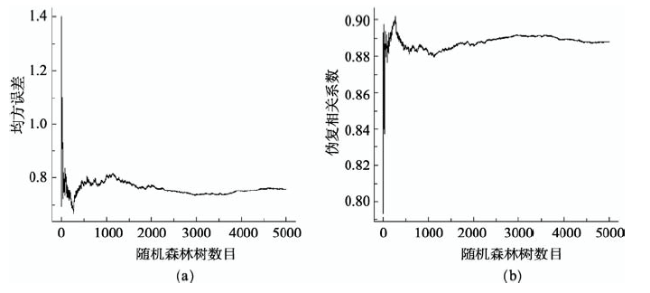
Fig.2 Relationship between the model error and the ntree number图2 随机森林决策树数目与模型误差关系图 |
Fig.3 Comparison of forest height between the ground measured values and the model estimations图3 模型估测平均树高与实测树高对比图 |
Tab.2 The inversion results of forest height compared with the ground measured results for the control plots表2 检验样地的树高反演结果与实测对比 |
| 样地编号 | 实测平均树高/m | 估测平均树高/m | 树高差值/m | 精度/(%) |
|---|---|---|---|---|
| 30 | 9.37 | 8.51 | -0.86 | 90.82 |
| 31 | 7.11 | 7.06 | -0.05 | 99.29 |
| 32 | 15.54 | 15.16 | -0.38 | 97.55 |
| 33 | 8.07 | 7.58 | -0.49 | 93.92 |
| 34 | 14.94 | 15.57 | 0.63 | 95.78 |
| 35 | 6.26 | 7.09 | 0.83 | 86.74 |
| 36 | 10.74 | 11.77 | 1.03 | 90.41 |
| 37 | 9.57 | 11.12 | 1.55 | 83.80 |
| 38 | 8.73 | 8.28 | -0.45 | 94.84 |
| 39 | 7.57 | 7.48 | -0.09 | 98.81 |
| 40 | 14.52 | 13.50 | -1.02 | 92.97 |
Fig. 4 Influence evaluation of the independent variables for the random forest approach图4 随机森林自变量影响力评价 |
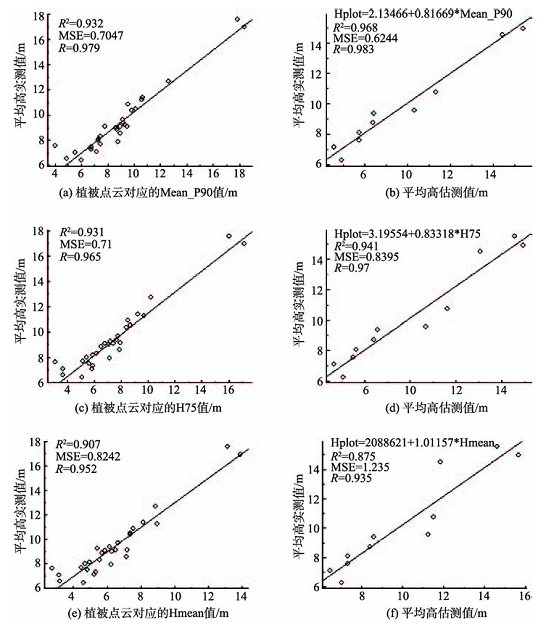
Fig.5 The influences of Mean_P90, H75 and Hmean variables on the estimation accuracy of the model图5 Mean_P90、H75和Hmean变量对模型估测精度的影响 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
[
|
| [22] |
[
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
[
|
| [28] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}