
Journal of Geo-information Science >
The Credibility and Evaluation of Volunteered Geographic Information
Received date: 2016-04-13
Request revised date: 2016-06-20
Online published: 2016-10-25
Copyright
The volunteered geographic information is mostly derived from volunteers' uploading with no quality guarantee. This has become a major obstacle of the application for the volunteered geographic information. Also, the quality becomes the primary problem which requires to be solved firstly. The quality evaluation is the focus of the present research domain. There are many researches on the quality evaluation of volunteered geographic information but a few research on the quality evaluation without reference data. Since it is very difficult or costly to get the reference data, it is important to study the quality evaluation without the reference data. In order to solve this problem with an unknown quality of the volunteered geographic information and the difficulty of getting the reference data with high quality, we proposed the credibility model. The credibility model could evaluate the VGI quality from the number of the volunteers and their reputation for the data changing trend. Then, we turn the qualitative analysis result into the quantitative expression. On one hand, the volunteer's reputation model was built based on this point, meaning a statistic method which takes the proportion for the preserving points as the volunteer's reputation value. Then, the Linus Law adapts and measures the geographical information collected by volunteers, of which credibility relied on the sum of the volunteer's reputation within the research areas. On the other hand, the information quality is gained from the data-changing tendency and measured by the geographical information credibility through computing the degree of change within the research areas. At last, for verification and analyzing the rationality of the credibility model, the OpenStreetMap, collects previous data adapted for Beijing, Shanghai and other cities which require to be used in experiments. Finally, the navigation data is selected as the reference data for the comparison. The result of calculation for the credibility model has a great coherence for the result based on the reference data.
MA Chao , SUN Qun , XU Qing , WANG Zhijian . The Credibility and Evaluation of Volunteered Geographic Information[J]. Journal of Geo-information Science, 2016 , 18(10) : 1305 -1311 . DOI: 10.3724/SP.J.1047.2016.01305
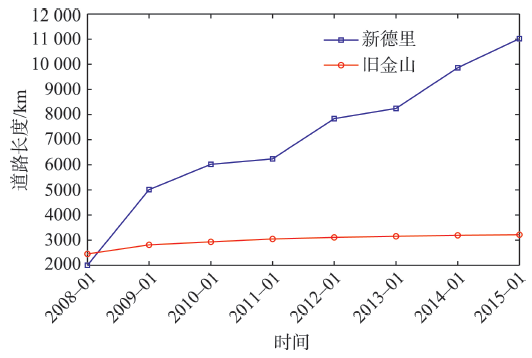
Fig. 1 The statistics of OSM road data图1 OSM道路数据统计 |
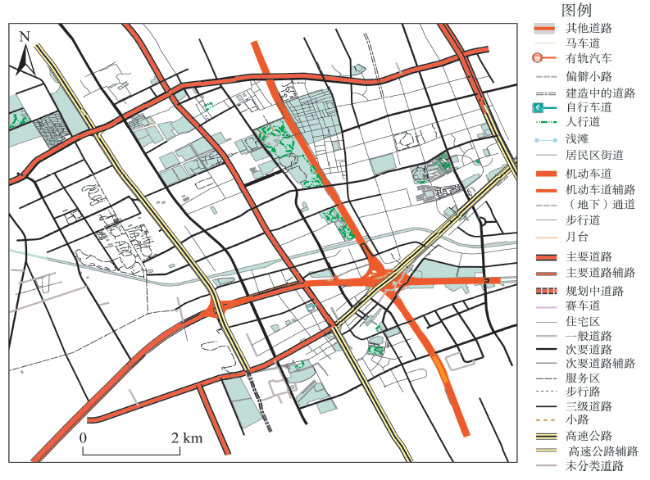
Fig. 2 Map of part of the experimental area图2 部分实验区域图 |
Tab. 1 The statistics of the credibility of experiment area表1 实验区域可信度统计表 |
| 编号 | 信誉度和 | 变化趋势 | 可信度 |
|---|---|---|---|
| 1 | 0.522 | 0.316 | 0.730 |
| 2 | 0.382 | 0.262 | 0.665 |
| 3 | 0.750 | 0.238 | 0.851 |
| 4 | 0.737 | 0.375 | 0.833 |
| 5 | 0.168 | 0.167 | 0.565 |
| 6 | 0.347 | 0.238 | 0.649 |
| 7 | 0.333 | 0.042 | 0.659 |
| 8 | 0.517 | 0.000 | 0.754 |
| 9 | 0.558 | 0.250 | 0.754 |
| … | … | … | … |
| 35 | 0.933 | 0.119 | 0.952 |
| 36 | 0.618 | 0.054 | 0.832 |
Tab. 2 The statistics of the data quality of experiment area表2 实验区域数据质量统计 |
| 编号 | 完整性 | 精度 | 质量 |
|---|---|---|---|
| 1 | 0.83 | 0.56 | 0.695 |
| 2 | 0.79 | 0.62 | 0.705 |
| 3 | 0.92 | 0.73 | 0.825 |
| 4 | 0.69 | 0.66 | 0.675 |
| 5 | 0.87 | 0.59 | 0.730 |
| 6 | 0.84 | 0.82 | 0.830 |
| 7 | 0.93 | 0.89 | 0.910 |
| 8 | 0.74 | 0.71 | 0.725 |
| 9 | 0.62 | 0.56 | 0.590 |
| … | … | … | … |
| 35 | 0.81 | 0.64 | 0.725 |
| 36 | 0.68 | 0.71 | 0.695 |
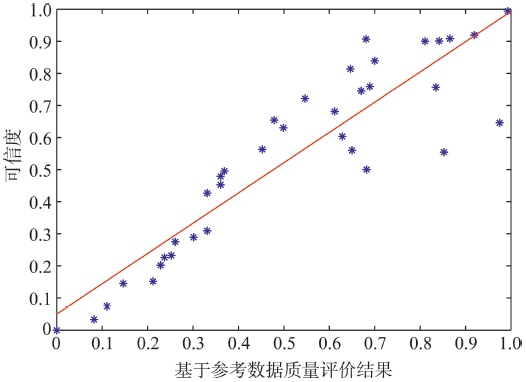
Fig. 3 Comparison of the results of the two evaluation methods图3 2种评价方法结果对比图 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
|
| [3] |
[
|
| [4] |
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
[
|
| [23] |
[
|
| [24] |
[
|
| [25] |
|
| [26] |
[
|
| [27] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}