
Journal of Geo-information Science >
Classification of Urban Rail Transit Stations based on SAX
Received date: 2016-08-04
Request revised date: 2016-10-18
Online published: 2016-12-20
Copyright
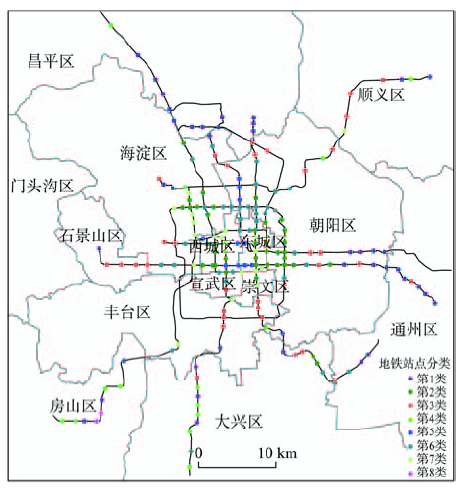
:Urban rail transit stations are the key nodes of the basic urban rail transit network system. The scientific classification of the rail transit stations is significant to understand the urban functional zoning and evaluate the construction of the rail transit infrastructure. The time series data of urban rail transit stations objectively records the important information of observed stations at all-time points. The time series data contains different patterns, which reflect different sequence genesis. Therefore, studying cluster of the time series data is an important means to recognize and understand the essence of time series data formation. It is also a major method to mine higher value of principle and knowledge that implied in time series data. In this paper, we use smart card data of urban rail transit stations in Beijing, and divide the big data into four data sets: weekdays boarding data set (WB), weekdays alighting data set (WA), weekends (rest day) boarding data set (RB) and weekends alighting data set (RA) to describe characteristics of each station’s daily passenger volume. Symbolic Aggregate approXimation (SAX) is firstly introduced to analyze four data sets, which effectively reduces the dimensionality of high-dimensional data and realizes similarity measure between stations. Finally, it is more reasonable to classify the 195 rail transit stations into 8 types according to the DB index by hierarchical clustering method. They are residential stations, work stations, partial residential-based residential and work mixed stations, dislocation stations, tourist attractions and commercial stations, partial work-based residential and work mixed stations, integrated stations and other stations. The performance of SAX is compared with Euclidean distance similarity measure. The results indicate that SAX outperforms Euclidean distance in terms of accuracy and efficiency. The paper analyzes characteristics of daily passenger boarding and alighting volume on four data sets and spatial distribution of each type. It is found that residence and dislocation stations are mostly located in the far end of the subway, while the types of work stations, tourist attractions and commercial stations, partial work-based residential and work mixed stations, and integrated stations are concentrated in the urban areas. Partial residential-based residential and work mixed stations scatter around the city center. The results can help to interpret the different functional zoning of the city and the characteristics of residents' travel behavior, which provides a basis for understanding the urban spatial pattern and its evolution process, and also provides some objective reference for planning, design and management services of rail transit stations.
ZHANG Liying , MENG Bin , YIN Qin . Classification of Urban Rail Transit Stations based on SAX[J]. Journal of Geo-information Science, 2016 , 18(12) : 1597 -1607 . DOI: 10.3724/SP.J.1047.2016.01597
Tab. 1 Smart card data of some subway stations in Beijing on March 1st, 2013表1 北京市部分地铁站点2013年3月1日刷卡数据 |
| ID | 进站名称 | 进站刷卡时间 | 出站名称 | 出站刷卡时间 |
|---|---|---|---|---|
| 10007510*****6142 | 长椿街 | 8:03:00 | 复兴门 | 8:10:26 |
| 10007510*****5723 | 苹果园 | 8:12:00 | 玉泉路 | 8:29:08 |
| 10007510*****2821 | 通州北苑 | 8:28:00 | 军事博物馆 | 9:25:23 |
| 10007510*****6032 | 和平门 | 9:36:00 | 五棵松 | 10:07:08 |
| 10007510*****5779 | 古城路 | 11:10:00 | 王府井 | 11:58:26 |
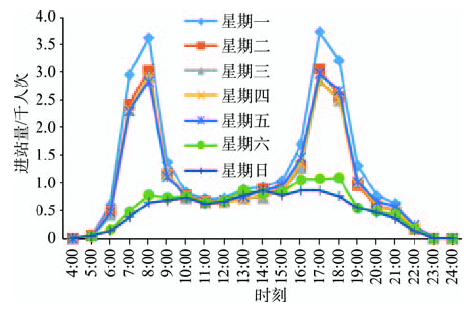
Fig. 1 Distribution of daily passenger boarding volume at AN DING MEN on weekdays and weekends图1 安定门工作日休息日进站日客流量分布 |
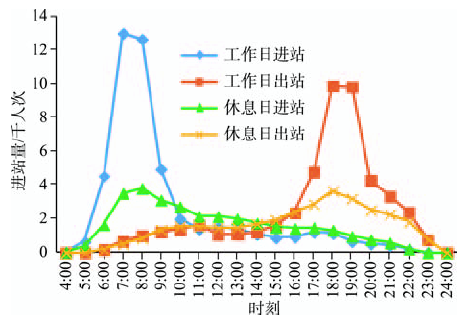
Fig. 2 Distribution of daily passenger boarding and alighting volume at TIAN TONG YUAN on weekdays and weekends图2 天通苑工作日休息日进出站日客流量分布 |
Tab. 2 DB index of two clustering methods表2 2种方法聚类的DB指数表[40] |
| 方法 | 分类个数 | ||||
|---|---|---|---|---|---|
| 6 | 7 | 8 | 9 | 10 | |
| SAX | 1.27 | 1.30 | 1.26 | 1.26 | 1.29 |
| 欧式距离 | 1.39 | 1.50 | 1.38 | 1.37 | 1.36 |
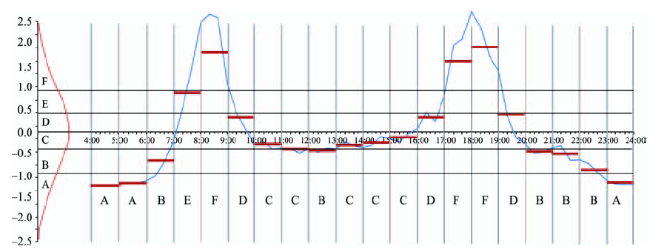
Fig. 3 SAX representation of distribution of passenger boarding volume at AN DING MEN on weekdays图3 安定门工作日进站客流量时间序列的SAX表示 |
Tab. 3 The time distribution features of eight types of subway stations表3 8类轨道站点的曲线特征 |
| 类别 | 工作日曲线特征 | 休息日曲线特征 | ||||||
|---|---|---|---|---|---|---|---|---|
| 进站 | 出站 | 进站 | 出站 | |||||
| 峰值及时间 | 峰值个数 | 峰值及时间 | 峰值个数 | 峰值及时间 | 峰值个数 | 峰值及时间 | 峰值个数 | |
| 1 | 4.53 7:00 | 1 | 3.33 18:00 | 1 | 0.74 8:00 | 1 | 0.82 18:00 | 1 |
| 2 | 3.04 18:00 | 1 | 5.45 8:00 | 1 | 0.26 17:00 | 1 | 0.31 8:00 | 1 |
| 3 | 4.27 7:00 0.96 17:00 | 2 | 1.26 8:00 3.20 18:00 | 2 | 0.58 8:00 0.13 17:00 | 2 | -0.12 8:00 0.68 18:00 | 2 |
| 4 | 3.82 8:00 0.68 18:00 | 2 | 0.58 8:00 2.90 18:00 | 2 | 0.74 9:00 0.65 16:00 | 2 | 0.47 11:00 1.15 17:00 | 2 |
| 5 | 1.49 17:00 -0.11 21:00 | 2 | 1.93 8:00 0.07 13:00 0.23 18:00 | 3 | 2.34 16:00 | 1 | 2.05 10:00 1.66 14:00 | 2 |
| 6 | 2.27 8:00 2.56 17:00 | 2 | 4.43 8:00 2.07 18:00 | 2 | 0.14 9:00 0.30 15:00 | 2 | 0.22 8:00 0.34 17:00 | 2 |
| 7 | 1.42 8:00 2.47 17:00 | 2 | 3.60 8:00 1.65 18:00 | 2 | 0.08 10:00 0.95 16:00 | 2 | 0.80 8:00 0.37 13:00 0.49 17:00 | 3 |
| 8 | 0.10 7:00 -0.33 10:00 0.31 12:00 0.50 15:00 | 4 | 0.88 8:00 -0.15 11:00 -0.22 13:00 -0.16 15:00 0.41 18:00 | 5 | 1.20 9:00 0.78 12:00 1.11 17:00 | 3 | 0.68 11:00 2.66 17:00 | 2 |
Tab. 4 Eight clusters of hierarchical clustering表4 层次聚类8类结果类 |
| 类别 | 站点数量 | 站点名称 |
|---|---|---|
| 1 | 41 | 八里桥 北宫门 草房 常营 传媒大学 次渠 次渠南 褡裢坡 稻田 俸伯 巩华城 管庄 广阳城 果园 黄村火车站 黄渠 回龙观 回龙观东大街 霍营 旧宫 梨园 良乡大学城西 临河里 龙泽 苹果园 沙河 沙河高教园 生命科学园 石门 天通苑 天通苑北 天通苑南 通州北苑 土桥 西红门 西苑 小红门 新宫 育新 枣园 朱辛庄 |
| 2 | 39 | 白石桥南 朝阳门 车公庄 车公庄西 磁器口 大望路 大钟寺 灯市口 东大桥 东单 东四十条 阜成门 复兴门 高碑店 国贸 海淀黄庄 呼家楼 惠新西街北口 建国门 金台夕照 亮马桥 灵镜胡同 柳芳 木樨地 南礼士路 荣京东街 三元桥 苏州街 团结湖 万源街 五道口 西二旗 西土城 宣武门 雍和宫 永安里 张自忠路 知春里 中关村 |
| 3 | 34 | 安和桥北 八宝山 八角游乐园 北苑 慈寿寺 崔各庄 高米店北 公益西桥 古城路 海淀五路居 后沙峪 花梨坎 角门西 劲松 九棵树 立水桥 立水桥南 林萃桥 刘家窑 马家堡 南法信 蒲黄榆 青年路 十里堡 双桥 四惠东 宋家庄 孙河 陶然亭 同济南路 亦庄桥 亦庄文化园 永泰庄 玉泉路 |
| 4 | 14 | 高米店南 黄村西大街 篱笆房 良乡南关 马泉营 南邵 清源路 顺义 苏庄 天宫院 肖村 义和庄 圆明园 长阳 |
| 5 | 10 | 奥林匹克公园 奥体中心 北海北 动物园 南锣鼓巷 森林公园南门 天安门东 天安门西 王府井 西单 |
| 6 | 33 | 安定门 安华桥 安贞门 北土城 北苑路北 菜市口 大葆台 大屯路东 鼓楼大街 光熙门 和平里北街 和平门 和平西桥 花园桥 惠新西街南口 健德门 金台路 经海路 牡丹园 荣昌东街 上地 芍药居 生物医药基地 双井 四惠 太阳宫 万寿路 望京 望京西 五棵松 西小口 长椿街 知春路 |
| 7 | 22 | 巴沟 北京大学东门 北京南站 北京站 北新桥 崇文门 东四 东直门 郭公庄 国家图书馆 国展 积水潭 军事博物馆 农业展览馆 平安里 前门 人民大学 天坛东门 魏公村 西四 西直门 新街口 |
| 8 | 2 | 良乡大学城 良乡大学城北 |
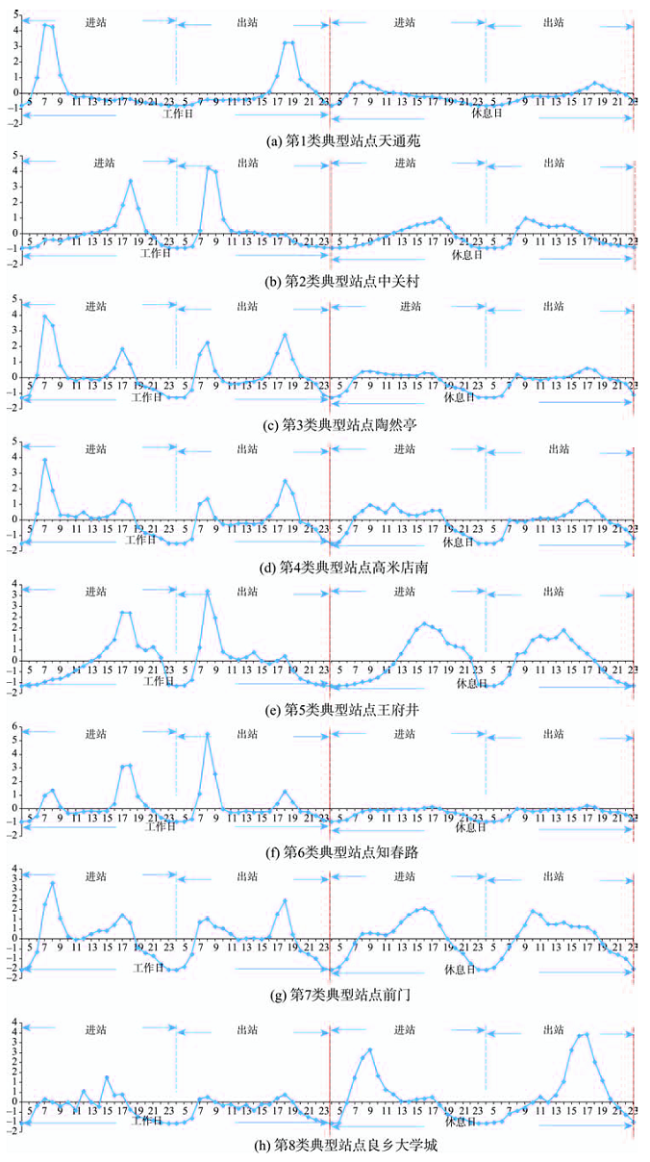
Fig. 4 Time distribution of passenger boarding and alighting volume of eight types of stations on weekdays and weekends图4 8类典型站点工作日休息日进出站分时段客流量分布 |
Fig. 5 Space distribution of subway stations types图5 轨道站点类型空间分布图 |
The authors have declared that no competing interests exist.
| [1] |
北京交通发展研究中心.2013年北京市交通发展年度报告[R].北京:北京交通发展研究中心,2013.
[ Beijing Transportation Research Center. Beijing transportation annual report 2013[R]. Beijing: Beijing Transportation Research Center, 2013 ]
|
| [2] |
[
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
[
|
| [23] |
[
|
| [24] |
[
|
| [25] |
[
|
| [26] |
[
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
[
|
| [36] |
[
|
| [37] |
[
|
| [38] |
[
|
| [39] |
[
|
| [40] |
|
| [41] |
|
| [42] |
[
|
| [43] |
[
|
| [44] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}