
Journal of Geo-information Science >
Study on the Electrical Devices Detection in UAV Images based on RegionBased Convolutional Neural Networks
Received date: 2016-03-17
Request revised date: 2016-06-21
Online published: 2017-02-17
Copyright
With the wide application of Unmanned Aerial Vehicle (UAV) in the inspection of power transmission line, the demand for objects detection and data mining from images acquired by UAV also grows significantly. Traditional detecting methods use some classical machine learning algorithms, such as support vector machine (SVM), random forest or adaboost etc. and combine the low level features such as gradient, colors or texture to detect electrical devices. These image features must be carefully designed and changed a lot from various object kinds. Thus, they are not suitable for UAV images with complex background and multiple kinds of object. On the other hand, the disadvantages of these methods are that they cannot take advantage of the high quantity and large coverage of UAV acquired images, and cannot get a satisfactory accuracy. The recent developing Deep Learning method brings light to this problem. Convolutional neural network (CNN) performs excellently in object recognition area and outstand many other methods used in the past. Without the need of extracting images’ features, CNN becomes the many state-of-the-art methods in object recognition rapidly. In object detection, Region-based convolutional neural networks (RCNN) retrieves the region that may contain the object from the images to detect and recognize the object. However, the computation is so expensive that it cannot meet the requirement of detecting massive UAV’s images and cannot be used in practical projects. Fast R-CNN and Faster R-CNN solve this problem by changing the way of object retrieval. They use features produced by CNN network layers and apply a region proposal network layer behind to locate the object. After that, fully connected layers and softmax layer follow to classify the features corresponding to object into special kinds. Using this strategy, Fast R-CNN and Faster R-CNN save lots of time to produce region proposal and can perform object detection at nearly real time. The principle and processes of Faster R-CNN and several other object detection methods are described in this paper, and they are tested for electrical devices detection from images of the power transmission line obtained by UAV. We analyzed the influence of several key parameters to the device detection results, such as the dropout ratio, non-maximum suppression (nms) and batch size. Then, we gave some constructive advice of tun ing parameters in Faster R-CNN. We also analyzed the advantages and weakness of three advanced detection algorithms, including Deformable Part Models (DPM) and two deep learning-based methods named Spatial pyramid pooling networks (SPPNet) and Faster R-CNN. Finally, we constructed image datasets of power transmission line inspection obtained by UAV and tested the three methods above. The recall ratio and accuracy ratio of them are compared and the superiority of the Faster R-CNN is validated. Testing results showed that Faster R-CNN method can detect various electrical devices of different categories in one image simultaneously within 80 milliseconds and achieve an accuracy of 92.7% on a standard test set, which is of great significance in real-time power transmission line inspection. These results also showed the advantages of the Faster R-CNN and we apply Faster R-CNN in our practical projects to detect electrical devices.
WANG Wanguo , TIAN Bing , LIU Yue , LIU Liang , LI Jianxiang . Study on the Electrical Devices Detection in UAV Images based on RegionBased Convolutional Neural Networks[J]. Journal of Geo-information Science, 2017 , 19(2) : 256 -263 . DOI: 10.3724/SP.J.1047.2017.00256
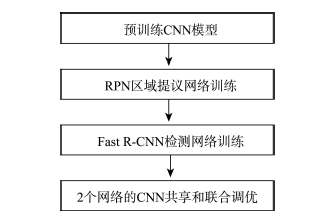
Fig. 1 Flowchart of devices detection in joint network training图1 部件识别的联合网络训练过程 |
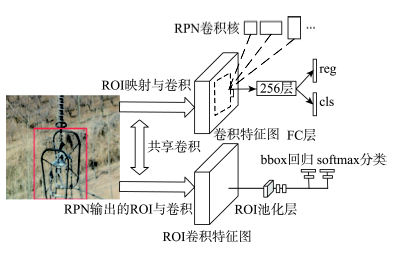
Fig. 2 The schematic diagram of network training图2 网络训练过程示意图 |
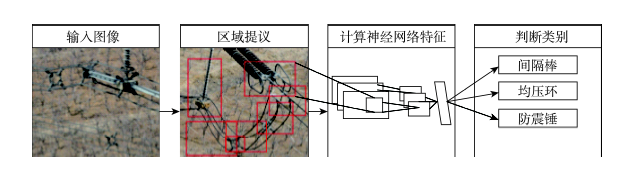
Fig. 3 Detection identification process图3 检测识别过程 |
Fig. 4 The original data and the training sample data图4 原始数据和训练样本数据 |
Tab. 1 Different dropout rate effects on mAP表1 不同dropout比例对mAP影响 |
| dropout比例 | 最大迭代次数 | 区域提议阶段批尺寸 | 检测阶段批尺寸 | nms前候选区域个数 | nms后候选区域个数 | mAP |
|---|---|---|---|---|---|---|
| 0.2 | 8000 | 256 | 128 | 2000 | 300 | 0.827 |
| 0.3 | 8000 | 256 | 128 | 2000 | 300 | 0.811 |
| 0.4 | 8000 | 256 | 128 | 2000 | 300 | 0.817 |
| 0.5 | 8000 | 256 | 128 | 2000 | 300 | 0.791 |
| 0.6 | 8000 | 256 | 128 | 2000 | 300 | 0.829 |
| 0.7 | 8000 | 256 | 128 | 2000 | 300 | 0.781 |
| 0.8 | 8000 | 256 | 128 | 2000 | 300 | 0.775 |
Tab. 2 Different numbers of nms effects on mAP表2 不同nms数目对mAP影响 |
| 最大迭代次数 | 区域提议阶段批尺寸 | 检测阶段批尺寸 | nms前候选区域个数 | nms后候选区域个数 | mAP |
|---|---|---|---|---|---|
| 8000 | 256 | 128 | 2000 | 300 | 0.829 |
| 8000 | 256 | 128 | 1500 | 250 | 0.818 |
| 8000 | 256 | 128 | 1000 | 200 | 0.806 |
| 8000 | 256 | 128 | 500 | 100 | 0.802 |
Tab. 3 Different batch sizes effects on mAP表3 不同的批尺寸对mAP影响 |
| 最大迭代次数 | 区域提议阶段批尺寸 | 检测阶段批尺寸 | nms前候选区域个数 | nms后候选区域个数 | mAP |
|---|---|---|---|---|---|
| 8000 | 256 | 128 | 2000 | 300 | 0.829 |
| 8000 | 128 | 64 | 2000 | 300 | 0.83 |
| 8000 | 64 | 32 | 2000 | 300 | 0.847 |
| 8000 | 32 | 16 | 2000 | 300 | 0.848 |
Tab. 4 Comparison of accuracy identified on the test set表4 在测试集上识别准确的对比 |
| 识别能力/% | 间隔棒 | 均压环 | 防震锤 |
|---|---|---|---|
| Faster R-CNN-正确率 | 91.2 | 92.7 | 84.3 |
| Faster R-CNN-召回率 | 88.5 | 84.3 | 79.3 |
| SPPnet-正确率 | 85.6 | 86.4 | 79.1 |
| SPPnet-召回率 | 80.4 | 78.6 | 73.7 |
| DPM-正确率 | 52.2 | 60.7 | 51.5 |
| DPM-召回率 | 51.9 | 55.2 | 49.8 |
Fig. 5 The results of three methods of spacer recognition图5 3种方法对间隔棒的识别结果 |
Tab. 5 Detection probability of 4 spacerswith regard to DPM、SPPnet and Faster RCNN表5 DPM、SPPnet、Faster RCNN对4个间隔棒的识别概率 |
| 方法 | 间隔棒1 | 间隔棒2 | 间隔棒3 | 间隔棒4 |
|---|---|---|---|---|
| DMP | 0.84 | - | - | 0.89 |
| SPPnet | - | 0.81 | 0.73 | 0.90 |
| Faster RCNN | 0.98 | 0.86 | 0.75 | 0.96 |
Tab. 6 Comparison of computation expense of SPPNet method and DPM method表6 Faster R-CNN和SPPNet、DPM方法计算时间开销对比 |
| 方法 | 平均时间 | 区域提议数量 | 关键步骤计算时间 | 关键步骤计算时间 | 关键步骤时间 |
|---|---|---|---|---|---|
| Faster R-CNN | 77 ms | 平均17 000,取前2000 | 卷积+区域提议时间47 ms | 非最大值抑制+外围框优化时间30 ms | 非最大值抑制 |
| SPPnet | 27.3 s | 3000至15000,取前2000 | Selective Search区域提议24.1s | 卷积特征提取2.5 s | 0.7 s |
| DPM | 224 s | - | - | - | - |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}