
Journal of Geo-information Science >
Research Progress and Review of High-Performance GIS
Received date: 2016-08-24
Request revised date: 2017-01-20
Online published: 2017-04-20
Copyright
The development of Internet technology has given birth to the explosive growth of various information in recent years. The traditional data processing method cannot matched with the rapidly improving performance of computer hardware and more efficient methods are needed to process the numerous data. High performance computing technologies, including Parallel cluster computing technology and distributed network technology, bring hints to the solution of these problems. In practice, there are three major distributed computing systems, namely Hadoop, Spark and Storm. Hadoop improves computational performance by introducing MapReduce distributed computing framework, while Spark make full use of computer memory to store data based on Resilient Distributed Datasets(RDD), which has a more rapid reading and writing functions of data . The Storm does not directly collect data. It realizes the data transmission and processing using network nodes. Nowadays, how to take advantage of the improvement of computational performance brought by the development of new hardware architecture to solve the long existing data intensive, computational intensive and communication intensive problems has become a topical issue in the field of GIS studies. In this paper, reviewing current research progress of high performance GIS, we examine and discuss about the algorithm of high performance GIS, parallel GIS computing, memory computing and core computing and give some prospective on the future development of high performance GIS, which provide a reference for the development of high performance GIS system. In addition, the development of the Internet technology and cloud computing is continuously boosting the popularity of GIS cloud computing and big data technology. In this context, domestic and foreign GIS platform vendors have launched their own cloud GIS platform, such as ArcGIS10.4 developed by ESRI and SuperMap 8C by SuperMap, to give support to cross-platform, parallel computing, 64-bit computing, distributed systems and other technologies.
ZUO Yao , WANG Shaohua , ZHONG Ershun , CAI Wenwen . Research Progress and Review of High-Performance GIS[J]. Journal of Geo-information Science, 2017 , 19(4) : 437 -446 . DOI: 10.3724/SP.J.1047.2017.00437
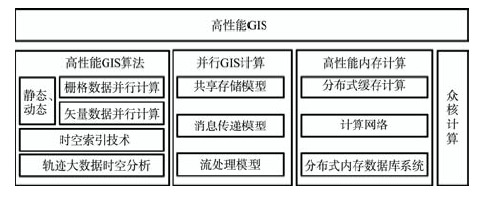
Fig. 1 The architecture diagram of high performance GIS图1 高性能GIS研究内容 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
[
|
| [9] |
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
[
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
[
|
| [26] |
[
|
| [27] |
[
|
| [28] |
|
| [29] |
|
| [30] |
[
|
| [31] |
|
| [32] |
[
|
| [33] |
|
| [34] |
[
|
| [35] |
|
| [36] |
[
|
| [37] |
|
| [38] |
[
|
| [39] |
[
|
| [40] |
|
| [41] |
[
|
| [42] |
[
|
| [43] |
[
|
| [44] |
[
|
| [45] |
[
|
| [46] |
|
| [47] |
[
|
| [48] |
|
| [49] |
|
| [50] |
[
|
| [51] |
[
|
| [52] |
|
| [53] |
[
|
| [54] |
|
| [55] |
|
| [56] |
[
|
| [57] |
[
|
| [58] |
|
| [59] |
[
|
| [60] |
[
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
[
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
[
|
| [71] |
[
|
| [72] |
[
|
| [73] |
[
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
[
|
| [80] |
|
| [81] |
[
|
| [82] |
[
|
| [83] |
[
|
| [84] |
[
|
| [85] |
[
|
| [86] |
[
|
| [87] |
[
|
| [88] |
[
|
| [89] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}