
Journal of Geo-information Science >
Study on Spatial Heuristic Rules for Query Plan Enumeration
Received date: 2016-12-16
Request revised date: 2017-02-20
Online published: 2017-05-20
Copyright
Query plan enumeration and query cost estimation are two important steps in a query optimizer of DBMS. The query plan enumeration is responsible for enumerating some candidate query plans with best or better plan. The query cost estimation is used to choose the best plan for execution. However, if the candidate query plans in the first step are too many, the second step has to spend more time on estimating them. In order to save the cost of estimation time and improve execution efficiency of the system, spatial heuristic rules are used to eliminate some impracticable query plans. This paper firstly explained some basic concepts, i.e. query graph, joined tree, and query plan. Then, we put forward three heuristic rules for spatial equal classes and spatial constrained pairs. The first is that spatial join operators should be established on spatial equal classes or spatial constrained pairs. The second is that the orders of join operators should be equal classes, spatial equal classes, non-Cartesian products of ordinary attributes, spatial constrained pairs and Cartesian products of ordinary attributes. The last one is a recursion rules about spatial equal classes. It means, only the attributes in spatial equal classes of a query plan could be transmitted each other. After that, this paper puts forward two rules for spatial indexing tables. The first is that it's better to replace a spatial table with its spatial indexing, when there is a spatial predicate on some spatial attributes. The second is the spatial indexing table must be on the top of its original table in a query plan and there should be a TID join between spatial index table and its original table. In the following sections, we explains the rules mentioned above and analyses how to improve query efficiency by using low cost operation as soon as possible and how to filter out candidate data as few as possible. At last, we present a sample to show how to eliminate some impracticable query plans by those spatial heuristic rules. Those rules are not only for query optimizer, but also for SQL programmer.
CHENG Changxiu , SHEN Shi , YANG Shanli . Study on Spatial Heuristic Rules for Query Plan Enumeration[J]. Journal of Geo-information Science, 2017 , 19(5) : 581 -586 . DOI: 10.3724/SP.J.1047.2017.00581
Fig. 1 Demonstration of query graph图1 查询图的形状示意 |
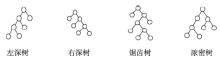
Fig. 2 Different types of join tree图2 连接树的类型 |
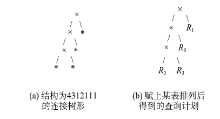
Fig. 3 An example of join tree shape and one of its query plan图3 连接树形与查询计划 |
Fig. 4 Legal location of I1图4 合法的I1位置 |
Fig. 5 Distribution of outliers detected by combined method图5 联合校验异常点分布 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
|
| [6] |
[
|
| [7] |
[
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
[
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
/
| 〈 |
|
〉 |

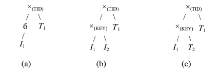
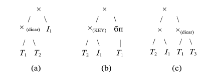

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}