
Journal of Geo-information Science >
An Approach for Prediction of Web User Behavior and Data Recommendation for Geoscience Data Sharing Portals
Received date: 2016-11-02
Request revised date: 2017-01-22
Online published: 2017-05-20
Copyright
Efficient and precise discovery of geoscience data on data sharing websites has been a challenge for years. This study applied Web mining techniques for National Earth Science Data Sharing Platform to derive user searching and visit behaviors using clustering algorithm. We proposed cluster-based approaches for search recommendation and visit recommendation. At data preprocessing stage, data cleaning, user identification, session identification and search terms extraction were performed. At user behavior mining stage, DBSCAN algorithm was employed for session clustering with Jaccard distance metric, considering the binary nature of session vectors. To mine user search patterns, we regard the collection of search term in each cluster as a document of text, and the collection of the whole historical search terms as corpus. Thereby, TF-IDF value of each search term in each cluster was then generated. In the scenario of online search recommendation, the real-time search term is taken to index the TF-IDF values in the clusters, and return the cluster with highest TF-IDF value. The items with top frequency is generated as recommendation list. As in the scenario of online visit recommendation, real-time visit vector is taken to query the clusters by the distance between the visit vector and cluster centroids. The nearest cluster is selected to generate most frequent items in the cluster as recommendation. Results of the experiment revealed the hot research topics of geoscience in recent years. The proposed search recommendation has a fair precision and recall, and visit recommendation was considerably improved compared to frequency-based approach. It can be concluded that: (1) web users of geoscience data sharing are more professional and predictable compared with normal web users; (2) DBSCAN is density-based clustering algorithm. It is vital to specifically define user behavior and chose a proper distance metric; (3) TF-IDF-based approach to predict users' search needs is feasible. The resulted search recommendation could be complementation to keyword-based searching. The outcome of this study would potentially contribute to the development of National Earth Science Data Sharing Platform, and even other science data sharing platform.
WANG Mo , WANG Juanle , HE Yuntao . An Approach for Prediction of Web User Behavior and Data Recommendation for Geoscience Data Sharing Portals[J]. Journal of Geo-information Science, 2017 , 19(5) : 595 -604 . DOI: 10.3724/SP.J.1047.2017.00595
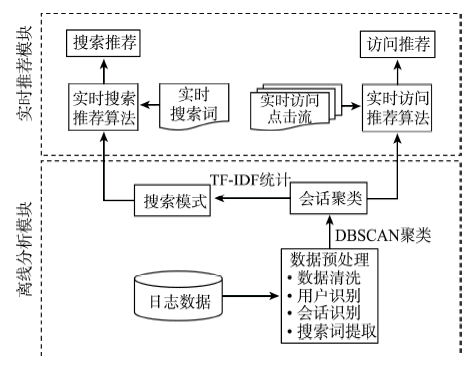
Fig. 1 Workflow for search and visit recommendation图1 搜索和访问推荐技术流程图 |
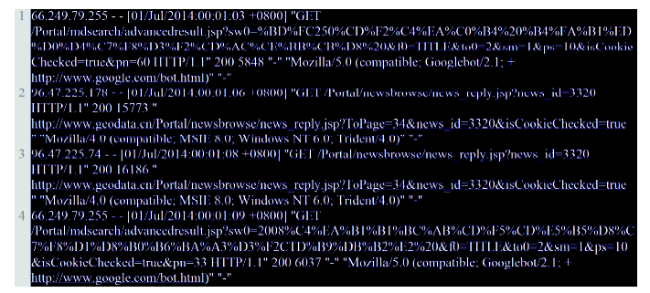
Fig. 2 An example of Web server log entries图2 Web服务器日志数据示例 |
Tab. 1 Contents of a Web server log entry表1 Web服务器日志数据内容 |
| 类别 | 详情 |
|---|---|
| 主机IP | 128.227.49.92 |
| 时间 | 05/Aug/2014:10:26:42 +0800 |
| 方法 | GET |
| URL | /extra/res/libs/kendo/extensions/kendo.extension.ui.js |
| 协议 | HTTP/1.1 |
| 状态 | 200 |
| 文件大小 | 15 072 Byte |
| 访问来源 | http://www.geodata.cn/extra/TopicsWin2/pro3.jsp |
| 客户端 | Mozilla/5.0 (Windows NT 6.3; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0 |
Tab. 2 Example of search word parsing表2 搜索词提取示例 |
| 类别 | 详情 |
|---|---|
| URL | 131.111.250.153,200,HTTP/1.1,-,-,"""-""", 2014.7.1, /Portal/mdsearch/regionresult.jsp?sw=%E5%8C%97%E4%BA%AC&sm=1&ps=10,… |
| 搜索词编码 | %E5%8C%97%E4%BA%AC |
| 编码类型 | utf-8 |
| 解码结果 | 北京 |


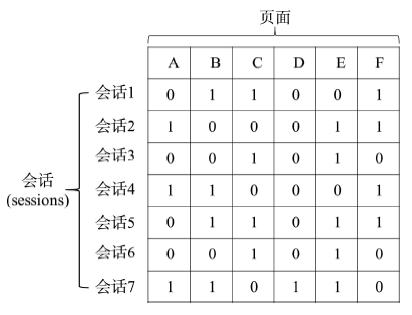
Fig. 3 User session vector图3 用户会话向量 |

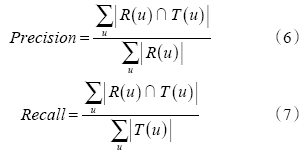
Tab. 3 Statistics for data preprocessing表3 数据预处理结果统计 |
| 年份 | 原始日志记录/条 | 清洗后记录/条 | 用户数/个 | 会话数/个 | 活跃会话/个 | 搜索次数/次 | 搜索词数量/次 |
|---|---|---|---|---|---|---|---|
| 2011 | 10 062 608 | 2 664 473 | 62 557 | 219 918 | 54 121 | 76 793 | 4589 |
| 2012 | 9 546 068 | 2 394 507 | 76 098 | 234 585 | 55 726 | 82 914 | 3883 |
| 2013 | 10 584 125 | 2 708 978 | 82 302 | 264 906 | 58 237 | 110 056 | 5426 |
| 2014 | 11 062 608 | 2 845 150 | 78 111 | 348 495 | 68 562 | 111 913 | 6243 |
| 2015 | 12 236 056 | 2 914 507 | 89 937 | 365 752 | 70 969 | 122 868 | 6761 |
Fig. 4 Word cloud of search terms图4 搜索热点云图 |
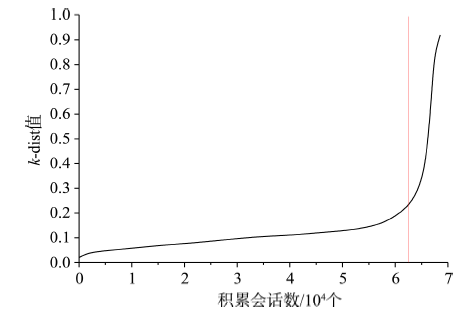
Fig. 5 K-dist plot of sample data (sorted by distance to 10th nearest neighbor)图5 聚类样本的k-dist图(以第10近的样本距离排序) |
Tab. 4 Statistics for cluster theme (top 5)表4 聚类主题统计(前5) |
| 聚类编号 | 聚类会话数量 | 数据主题 | 主题占比/% |
|---|---|---|---|
| 01 | 8355 | 土地覆被及土地利用 | 83.6 |
| 02 | 6712 | 土壤数据 | 78.4 |
| 03 | 6248 | 环境与灾害 | 84.3 |
| 04 | 5471 | 地形地貌 | 74.5 |
| 05 | 4676 | 冰川冻土 | 69.8 |
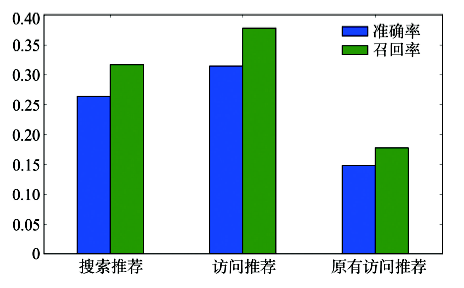
Fig. 6 Comparisons of precision and recall图6 准确率和召回率对比图 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
[
|
| [8] |
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
[
|
| [18] |
[
|
| [19] |
|
| [20] |
|
| [21] |
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}