
Journal of Geo-information Science >
Overview and Prospect on Spatial Analysis of Parallel Vectors in Pan-spatial Concept
Received date: 2017-05-12
Request revised date: 2017-08-11
Online published: 2017-10-09
Copyright
The new generation of parallel spatial analysis in pan-spatial information system is challenged by analysis of spatial big data and real-time spatial service. As one of the most important part of GIS, vector spatial analysis has some performance bottlenecks such as load unbalance, less ability of parallel expansion and low I/O efficiency. First, we review the history of the developing process of vector spatial analysis from application requirement and technical progress. Then, we expound the research findings of spatial analysis of parallel vector, summarize the algorithm features and technical bottlenecks, compare the different parallel programming model and present the parallel spatial algorithm of R&D processing. Finally, we predict the spatial data model in the future and the computing method based on spatio-temporal objects of multi-granularity in pan-spatial information system. Also, we present the new techniques which use memory computing to realize the storage-computing integration in vector spatial analysis.
QIU Qiang , QIN Chengzhi , ZHU Xiaomin , ZHAO Xiaofang , FANG Jinyun . Overview and Prospect on Spatial Analysis of Parallel Vectors in Pan-spatial Concept[J]. Journal of Geo-information Science, 2017 , 19(9) : 1217 -1227 . DOI: 10.3724/SP.J.1047.2017.01217
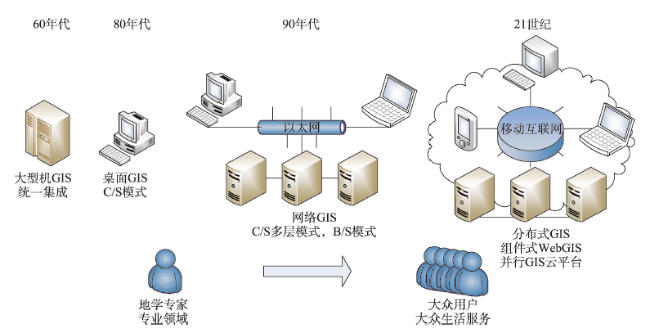
Fig. 1 Development history of GIS图1 GIS发展历程 |
Tab. 1 Research status of parallel GIS表1 并行GIS研究现状 |
| 研究方向 | 代表性研究 | 研究成果 | |
|---|---|---|---|
| 空间数据并行处理 | Richard Healey和Steve Dowers基于文件系统对空间数据条带化处理[21] | 基于MIMD体系结构的原型系统和函数库 | |
| 易法令等提出的空间数据格式转换算法[24] | GRID、TIN格式转换算法和任务调度 | ||
| Hoel和Samet并行空间索引[25] | 基于四叉树、R树和R+树的并行索引 | ||
| HadoopGIS[26]和GeoSpark[27] | 利用Hadoop及Spark等计算架构完成空间数据的并行检索 | ||
| 细粒度算法并行化 | Lanthier[28]等最短路径算法,张丽丽[29]平面扫描算法 | 并行空间分析基础算法 | |
| 粗粒度任务并行 | McKenney[30]等并行扫描线算法 | 为任务级并行空间分析提供了理论基础 | |
| Agarwa[31]等提出了overlay算法并行策略;范俊甫[32-33]用MPI并行方法研究多边形合并及缓冲区算法 | 基于Linux集群的并行overlay算法 | ||
| 空间分析并行框架 | Dowers[34]和Mineter[35]矢量拓扑并行处理框架 | 用开放式GIS服务架构兼容的软件组件,进行并行拓扑构建 | |
| Qin[36]等提出的栅格空间分析并行框架 | 实现不同算法不同并行策略下的并行编程框架 | ||
| 并行空间数据库 | Zhao[37]利用面向对象模型实现空间数据描述; 陈达伦等[38]提出了基于MPP架构的并行空间数据库 | 并行GIS数据库平台 | |
Tab. 2 Comparison of parallel programming models for vector spatial analysis表2 矢量空间分析并行编程模型对比 |
| 并行编程模型 | OpenMP | MPI | MapReduce/Spark | CUDA |
|---|---|---|---|---|
| 并行粒度 | 细粒度 | 粗粒度 | 粗粒度 | 细粒度 |
| 性能优势 | 实现简单,并行效率高 | 适用于集群环境,并行算法扩展性强 | 编程实现简单,容错性好 | 强大的并行浮点计算能力 |
| 缺点 | 只适用SMP等并行环境,扩展性差 | 容错性差 | 中间结果存储造成I/O次数增多 | 空间数据传输效率低,算法普适性低 |
| 适用GIS场景 | 空间分析算法的局部优化 | 高性能并行空间分析算法研发 | 数据密集型空间操作 | 计算密集型空间操作 |
Tab. 3 Characteristic comparison between memory database and vector spatial analysis表3 内存数据库与矢量空间分析特征对比 |
| 内存数据库 | 矢量空间分析算法I/O | |
|---|---|---|
| 读写性能 | 数据常驻内存,读写速度快的key-value数据结构 | 数据密集特征,I/O时间成为制约算法效率的性能瓶颈 |
| 存储容量 | 存储容量存在上限,超过内存限制会大量使用swap,降低性能 | 以矢量数据为存储模型,表达空间对象信息丰富,但数据规模较小 |
| 持久化 | 安全稳定的持久化策略 | 对空间数据存储和系统容错有较高要求 |
| Master-Slave复制 | 适合集群应用环境 | 在集群环境中,通过并行计算技术提高算法效率 |
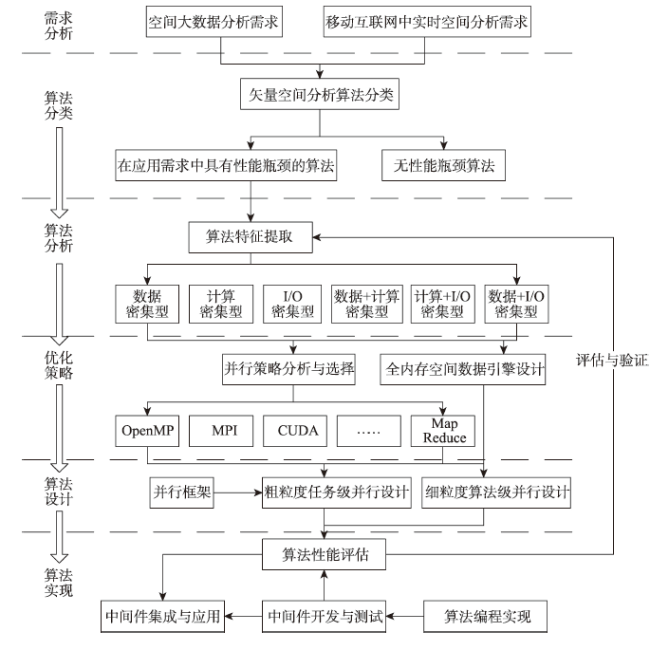
Fig. 2 Research and development process of spatial analysis of parallel vector图2 矢量空间分析并行算法研发流程 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
|
| [4] |
[
|
| [5] |
[
|
| [6] |
|
| [7] |
|
| [8] |
[
|
| [9] |
迟学斌.高性能并行计算[M].2005. https://wenku.baidu.com/view/ 52aa1ba8bb4cf7ec4bfed003. html.
[
|
| [10] |
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
[
|
| [21] |
|
| [22] |
|
| [23] |
[
|
| [24] |
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
[
|
| [30] |
|
| [31] |
|
| [32] |
[
|
| [33] |
[
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
[
|
| [39] |
[
|
| [40] |
|
| [41] |
|
| [42] |
[
|
| [43] |
|
| [44] |
[
|
| [45] |
[
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
[
|
| [51] |
张景云.基于Redis 的矢量数据组织研究[D].南京:南京师范大学,2013.
[
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}