
Journal of Geo-information Science >
Geospatial Data Provenance-Ontology and Its Application in Data Linking
Received date: 2017-06-12
Request revised date: 2017-08-11
Online published: 2017-10-20
Copyright
Data provenance is an important reference factor of data reliability evaluation and important research content of geospatial data ontology. Taking consideration of provenance, an important research object of geospatial data, we constructed a geospatial data provenance conceptual model based on systemic analysis of the meaning of geospatial data provenance. Based on it, we put forward geospatial data Provenance-Ontology concepts system and the formalization method for constructing geospatial data Provenance-Ontology. Finally, we take the data materials in “special work of the science and technology basic work” as an example. Based on Provenance-Ontology library, using RDF to link geospatial data and D3.js to achieve the data provenance visualization. The result shows that data linking based on Provenance-Ontology can effectively solve the problem of the nonstandardization in the description of data provenance information. It can support geospatial data semantic retrieval, intelligent recommendation and other applications. It also provides new ideas for geodata sharing and data linking.
Key words: geospatial data; provenance; ontology; data linking
LI Weirong , ZHU Yunqiang , SONG Jia , SUN Kai , YANG Jie . Geospatial Data Provenance-Ontology and Its Application in Data Linking[J]. Journal of Geo-information Science, 2017 , 19(10) : 1261 -1269 . DOI: 10.3724/SP.J.1047.2017.01261
Tab. 1 The advantages and disadvantages between provenance models表1 来源模型间的优缺点对比 |
| 模型名称 | 模型描述 | 优点 | 缺点 |
|---|---|---|---|
| W7 | 由7个相互关联的要素组成,即what、where、why、how、which、when、who,详细地描述了它们之间的相互关系 | 来源要素完整 | 通用模型,难以应用于具体领域 |
| PROV | W3C标准,计算机可以读取和处理的来源框架,支持owl、XML等多种格式,定义了如何获取、利用以及验证来源信息 | 完整定义了人、机构以及活动之间的关系 | 通用模型,难以应用于具体领域 |
| OPM | 由Artifact、Process、Agent 3个要素组成,定义某个对象在不同状态时的因果关系 | 完整定义了某个对象在不同状态时的因果关系 | 缺少时间、空间等重要来源要素 |
| Provenior | 一种描述工作流的来源模型,由data,agent,process3个要素组成 | 完整的工作流过程 | 缺少数据间关系的描述 |
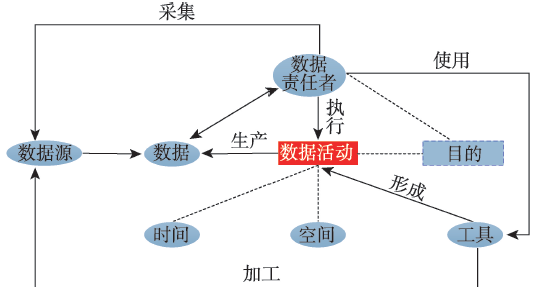
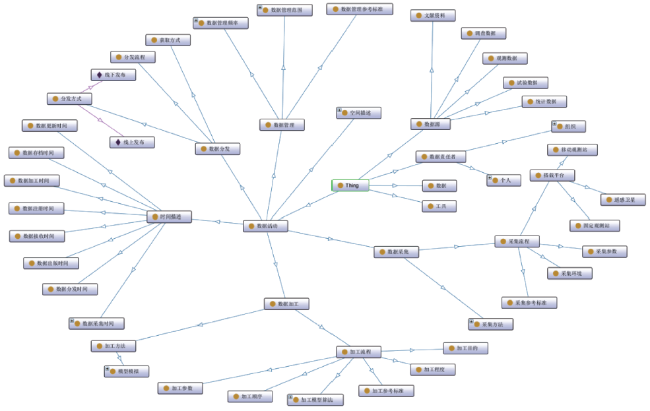
Fig. 1 The model of provenance-ontology of geospatial data图1 地理空间数据来源本体模型 |
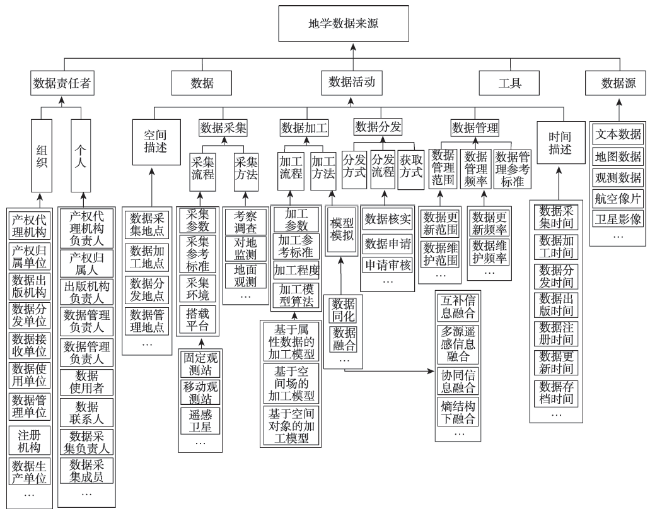
Fig. 2 The concept system of geospatial data provenance图2 地理空间数据来源概念体系 |
Tab. 2 The core relations between provenance entities表2 来源本体概念间的核心关系 |
| 关系 | 关系简述 | 图示 |
|---|---|---|
| 引用 | 多个数据源合并成一个新数据,侧重于数据的复制,新的数据中存在旧的数据源 | 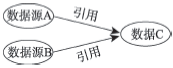 |
| 更新 | 在已有数据上添加新的信息 |  |
| 融合 | 多个数据源合成一个新数据,新数据中不存在旧的数据源 | 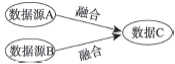 |
| 修订 | 修复数据中的某些错误 |  |
| 衍生 | 单个数据经过加工后生产新的数据,侧重于数据一对一的形成 |  |
| 使用 | 利用已有数据源进行数据活动,利用数据前,数据活动不会被数据源所影响 |  |
| 生成 | 通过数据活动完成新数据的生产,生产之前不存在,生产之后可供使用,主要针对原始数据的产生 |  |
| 共生 | 数据生产过程中,涉及多个数据活动,相互之间缺一不可 |  |
| 授权 | 数据责任者A委托数据责任者B进行数据活动 |  |
| 属于 | 数据责任者对数据具有所有权 |  |
| 负责 | 数据责任者在数据活动中承担任务或者责任 |  |
| 贡献 | 数据责任者参与数据活动,对数据的生成起有利作用 |  |
Tab. 3 The core properties of provenance ontology表3 来源本体中的核心属性示例 |
| 实体名 | 属性类名 | 属性名 |
|---|---|---|
| 工具 | 采集仪器 | 型号唯一标识 |
| 标称精度 | ||
| 应用领域 工作范围 采集对象 | ||
| 加工工具 | 运行环境 | |
| 工具版本 | ||
| 加工精度 | ||
| 模型提出者 模型提出时间 | ||
| 模型版本 | ||
| 数据责任者 | 个人 | 职务入职时间 |
| 联系方式 | ||
| 联系地址 员工编号 所在部门 | ||
| 机构 | 单位法人 | |
| 成立时间 | ||
| 单位类型 | ||
| 单位规模 | ||
| 业务范围 | ||
| 服务时间 |
Fig. 3 Geospatial data provenance-ontology visualization图3 地理空间数据来源本体可视化 |
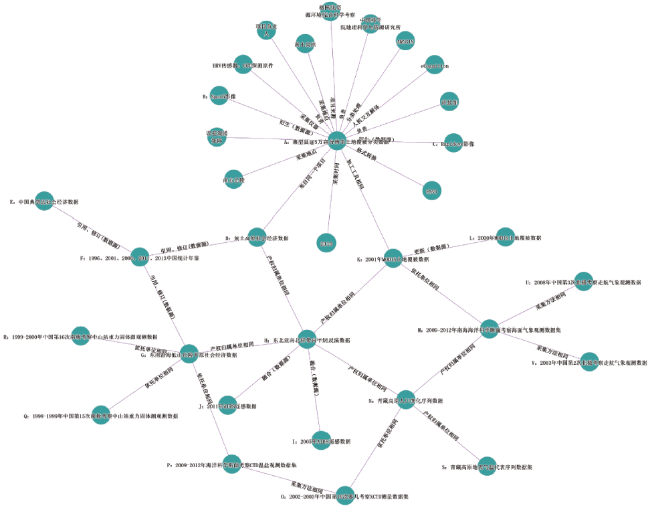
Fig. 4 Geospatial data linking network based on provenance information图4 基于来源信息的地理空间数据关联网络 |
Tab. 4 Data linking rules表4 数据关联规则 |
| 数据 | 关联的数据 | 关联规则 |
|---|---|---|
| A | B、C | B、C是A的数据源 |
| F | D、E、G | F是D、E、G的数据源 |
| H | I、J | I、J是H的数据源 |
| K | L | K是L的数据源 |
| A | K | 同一加工工具 |
| A | D | 来自同一个项目 |
| H | D、N、G、K | 产权归属单位相同 |
| N | S、M | 产权归属单位相同 |
| G | P、Q、R | 依托单位相同 |
| K | M | 依托单位相同 |
| N | O | 依托单位相同 |
| P | Q | P和Q的采集方法相同 |
| M | U、V | M和U、V的采集方法相同 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
ISO19115-2-2009,
|
| [3] |
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
[
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
[
|
| [21] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}