
Journal of Geo-information Science >
Extracting and Analyzing Latent Semantic Characteristics of Locations Using Social Media Data
Received date: 2017-07-04
Request revised date: 2017-09-07
Online published: 2017-11-10
Copyright
Social media data are increasingly perceived as an important channel to record people’s perception by virtue of its large volume, availability and timeliness. Especially, some social media data are location-stamped, associating with the space in the city with human cognition. Thus, we can further manifest the sociocultural signature of places in a semantic way. In this paper, geo-tagged text data on Weibo were utilized to explore the hidden semantic characteristics of locations, with focus on semantic similarities among regions. Specifically, Latent Semantic Analysis (LSA) were introduced to transform the unstructured regional and semantic feature in social media into a cognition-friendly and deep-related vector. Then, spatial analysis method, including factor analysis, spatial correlation analysis and clustering analysis were employed to mining the hidden characteristics of locations. In terms of research results, different latent topics and their distribution across the city were uncovered. Similarity index of tested locations were then obtained by measuring their latent semantic features. Baidu-pedia entries were further used as empirical consensus and spatial autocorrelation analysis was employed to investigate urban functional hot-regions. Besides, spatial clusters were acquired by using K-MEANS method in latent semantic space. Its effectiveness was validated by the diversity of POI density among clusters. This study demonstrates how the semantic meaning of a space can be harvested through the analysis of crowd-generated content in social media, which is useful to capture the unique themes that shape a location and support urban planning.
Key words: location semantics; social media; latent semantic analysis; place sensing
CHEN Yuanyuan , GAO Yong . Extracting and Analyzing Latent Semantic Characteristics of Locations Using Social Media Data[J]. Journal of Geo-information Science, 2017 , 19(11) : 1405 -1414 . DOI: 10.3724/SP.J.1047.2017.01405
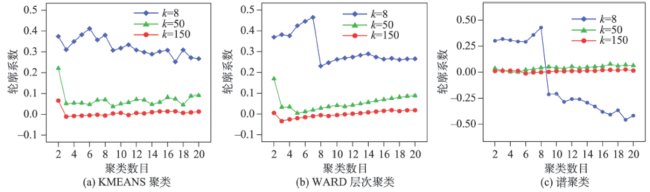
Fig. 1 Silhouettes of clustering in different LSA dimensions图1 不同维度数目下聚类轮廓系数 |
Fig. 2 Word cloud and hot spots of Topic 2-4图2 潜语义空间上的主题词云和热点区域分布 |
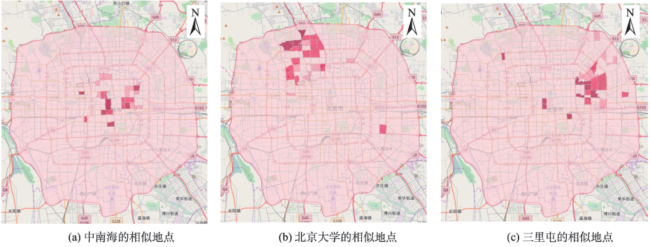
Fig. 3 Similar locations of test regions图3 局部地区的相似地点分布 |
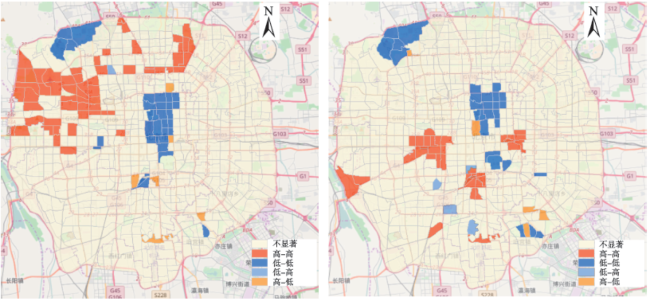
Fig. 4 Hot spots distribution of urban functional regions图4 特定功能类型下的热区分布 |
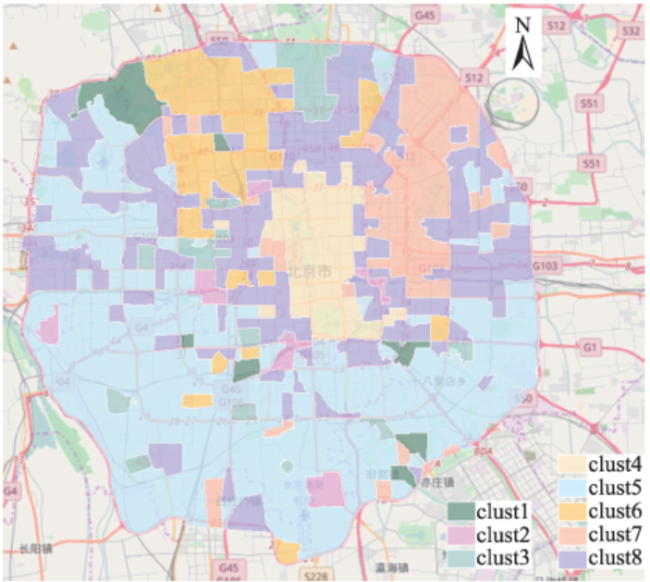
Fig. 5 K-MEANS clustering results of areas within 5th Ring Road Beijing图5 五环区域内的全局聚类结果 |
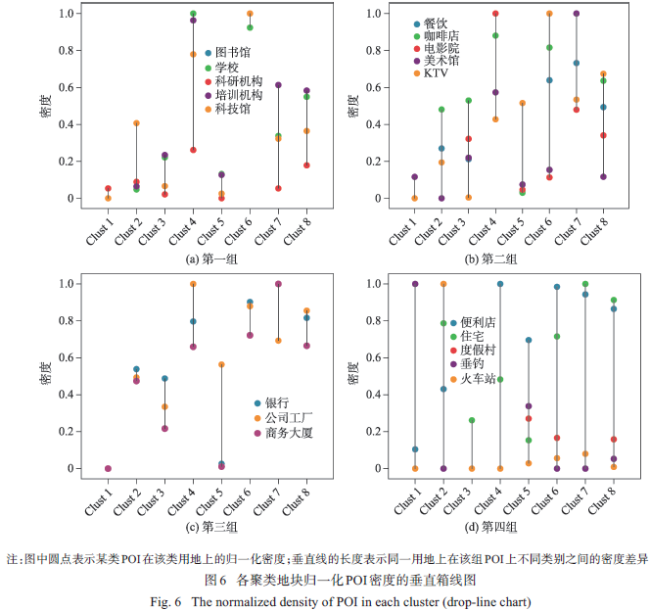
Fig. 6 The normalized density of POI in each cluster (drop-line chart)图6 各聚类地块归一化POI密度的垂直箱线图 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
[
|
| [13] |
[
|
| [14] |
|
| [15] |
|
| [16] |
Farazi, Feroz, Vincenzo, et al. A semantic geo-catalogue for a local administration[J]. Artificial Intelligence Review, 2013,40(2):193-212.
|
| [17] |
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
[
|
| [25] |
[
|
| [26] |
[
|
| [27] |
|
| [28] |
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}