
Journal of Geo-information Science >
The Discovery of Spatial Association Patterns of Resource and Environment Information Based on Grid Data
Received date: 2017-06-13
Request revised date: 2017-09-23
Online published: 2018-01-20
Supported by
Foundation item: Public Welfare Profession Project of Ministry of Land and Resources of the People's Republic of China, No.201411007.
Copyright
Spatial association patterns include location patterns of spatial association which emphasize on spatial data and structure patterns of the spatial association, which emphasize on attribute data. However, traditional methods were based on traditional spatial data and used spatial predicates as the logic in the process of mining. This would lead to the following problems: Firstly, it relied on the boundaries of spatial phenomenon and didn’t take account in the area of spatial phenomenon. Secondly, the results were restricted strongly by the table of spatial predicate built before data mining. Based on The Tobler’s First Law of Geography, this research proposed a new method of extracting spatial association patterns without using spatial predicate. According to specific data content and data format, this method converted spatial data into grid data which has the same spatial coordinate and the same size of each grid. Then, the method used a smooth moving-mask to get the transaction database from the grid data. Apriori algorithm without self-connection of attributes was adopted to explore the latent association patterns in transaction database. Finally, an experiment was conducted to verify the accuracy of this method. The experiment data included the data of coal mining area, land use data, water system data and terrain data in Changhe basin of Jincheng City in Shanxi Province. In the experiment, the error of grid transformation of each data layer was controlled within 5% and the accuracy of transaction was verified in co-location pattern. Grid transformation generated 28 434 grids and the size of each grid was 64 meters. After setting cultivated land as main factor, there were 38 310 records in transaction database. Through the study on some association patterns with higher confidence, it showed that the results were consistent with the prior knowledge related to cultivated land in ore-agricultural area. Therefore, this method can effectively extract the meaning association patterns and improve the interestingness of the results. This method improves the degree of freedom of the data mining by setting different sizes of the grid, main factors and mask sizes. Based on grid data instead of traditional spatial data, this method doesn’t rely on the boundaries of spatial phenomenon and takes into account the area factor.
XU Zhen , JING Yaodong , BI Rutian , GAO Yang , WANG Peng . The Discovery of Spatial Association Patterns of Resource and Environment Information Based on Grid Data[J]. Journal of Geo-information Science, 2018 , 20(1) : 28 -36 . DOI: 10.12082/dqxxkx.2018.170266
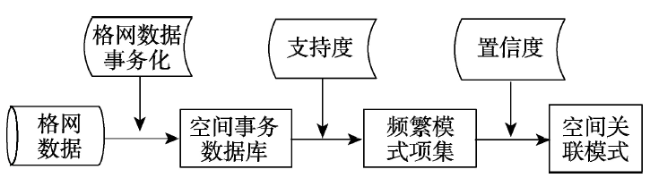
Fig. 1 The method of the discovery of spatial association patterns based on the grid data图1 基于格网数据的空间关联模式发现方法 |
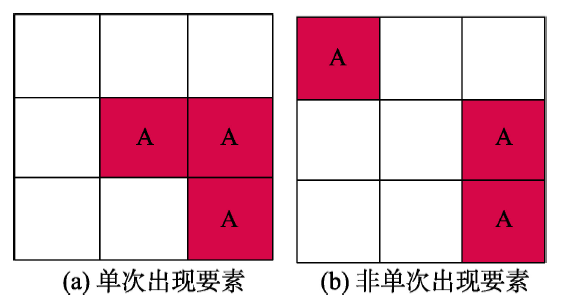
Fig. 2 The consistency test between graphic and attribute of the spatial phenomena图2 空间现象图属一致性检验 |
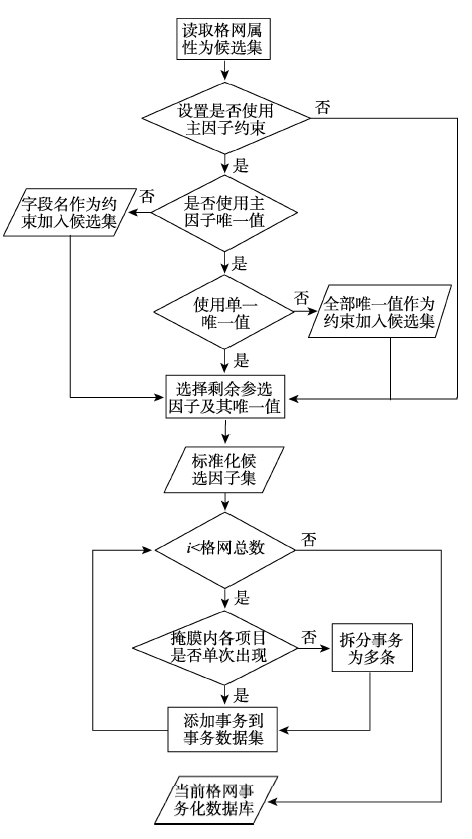
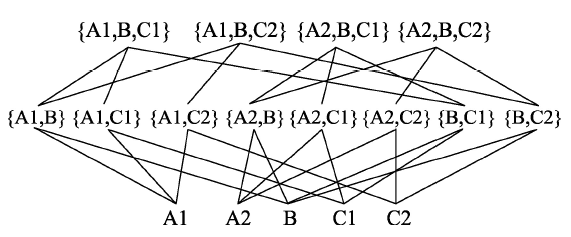
Fig. 3 Flow chart of converting grid data into transaction database图3 格网数据事务化流程 |
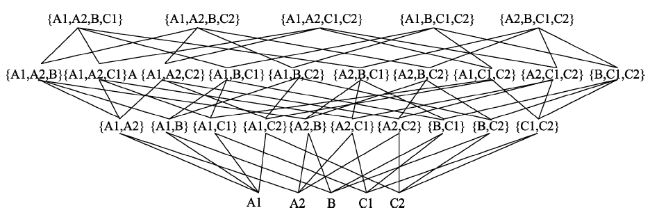
Fig. 4 The condition with self-connection of attribute图4 未去除属性自连接 |
Fig. 5 The condition without self-connection of attribute图5 去除属性自连接 |
Tab. 1 Experiment data表1 实例数据 |
| 数据集 | 数据层 | 数据来源 | 存储格式 | 数据类型 |
|---|---|---|---|---|
| 社会经济数据 | 土地利用类型 | 土地利用规划空间数据库 | Shp | 面 |
| 耕地等级 | 耕地质量评价空间数据库 | Shp | 面 | |
| 自然地理数据 | 高程DEM | STR DEM(精度30 m) | 栅格 | - |
| 坡度 | 坡度分析 | 栅格 | - | |
| 土壤类型 | 土壤普查空间数据库 | Shp | 面 | |
| 专题数据 | 距矿区最小距离 | 与矿界临近分析 | Shp | 面 |
| 采空区 | 矿区图件矢量化 | Shp | 面 | |
| 矿区边界 | 矿区图件矢量化 | Shp | 面 | |
| 距水域最小距离 | 与水系临近分析 | Shp | 面 |
Tab. 2 Principle and error in gridding process of each layer表2 各图层格网化原则及误差 |
| 存储 格式 | 数据层 | 属性确定原则 | 属性取舍 阈值/% | 误差/% |
|---|---|---|---|---|
| Shp | 土地利用类型 | 优先耕地的基础上 面积占优 | 34 | 4.6 |
| 农业机械普及率 | 面积占优 | 35 | 4.7 | |
| 耕地产量分级 | 面积占优 | 34 | 4.6 | |
| 距矿区最小距离 | 无损赋值 | 0 | - | |
| 采空区 | 面积占优 | 38 | 3.5 | |
| 距水域最小距离 | 无损赋值 | 0 | - | |
| 土类 | 无损赋值 | 0 | - | |
| 栅格 | 高程DEM | 无损赋值 | 0 | - |
| 坡度 | 面积占优法 | 50 | 3.8 |
Tab. 3 The settings of each factor in transaction process表3 事务化过程各因子条件设置 |
| 因子类型 | 属性字段 | 唯一值 |
|---|---|---|
| 主因子 | 土地利用类型 | 耕地 |
| 候选因子 | 产量分级 | 高产田、障碍层类型、贫瘠肥培型、干旱灌溉型、坡地梯改型 |
| 土类 | 褐土、红粘土、粗骨土 | |
| 距水系最小 距离/m | <350、 350~1086、 1086~2000、2000~3500、>3500 | |
| 距矿区最小 距离/m | <324、 324~684、 684~1700、 1700~3547、>3547 | |
| 采空区 | 无 | |
| 坡度分级/° | <16、 16-32、 32~48、 >48 |
Tab. 4 Partially frequent association patterns表4 部分频繁关联模式 |
| N项集 | 编号 | 前置项 | 后置项 | 支持度/% | 置信度/% |
|---|---|---|---|---|---|
| 2项集 | 1 | 耕地 | 坡度0~16° | 99.24 | 99.24 |
| 2 | 高产田 | 坡度0~16° | 32.07 | 96.93 | |
| 3 | 高产田 | 褐土 | 71.16 | 91.12 | |
| 4 | 瘠薄肥培型 | 距矿区<324 m | 11.21 | 47.55 | |
| 5 | 瘠薄肥培型 | 距矿区>3500 m | 5.36 | 42.67 | |
| 6 | 高产田 | 距水系<1086 m | 75.40 | 85.28 | |
| 7 | 高产田 | 距矿区324~684 m | 42.90 | 68.12 | |
| 3项集 | 8 | 褐土、坡度0~16° | 高产田 | 60.87 | 88.47 |
| 9 | 距矿区>3500 m、坡度16~32° | 瘠薄肥培型 | 4.86 | 60.56 | |
| 10 | 采空区 | 距矿区<324 m、距水系<1086 m | 15.20 | 78.69 | |
| 11 | 采空区、距矿区<324 m | 干旱灌溉型 | 9.34 | 55.12 | |
| 4项集 | 12 | 距水系<1086 m、坡度0~16°,褐土 | 高产田 | 68.63 | 89.54 |
| 13 | 距矿区<684 m、坡度0~16°,褐土 | 高产田 | 48.51 | 91.92 | |
| 14 | 坡度16~32°,矿区距离>3500 m,红粘土 | 瘠薄肥培型 | 4.30 | 50.23 |
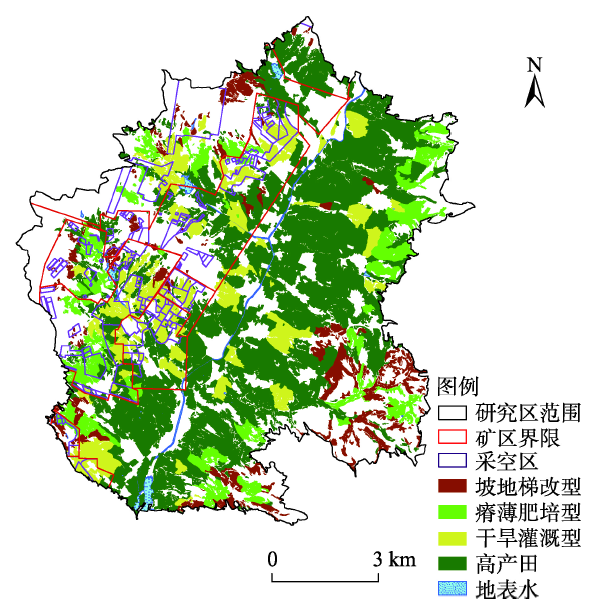
Fig. 6 Distribution of various farmland, mining area, river systems and learies图6 各类耕地与矿区、水系、采空区分布图 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
[
|
| [4] |
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
|
| [14] |
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
|
| [21] |
[
|
| [22] |
[
|
| [23] |
[
|
| [24] |
[
|
| [25] |
[
|
| [26] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}