
Journal of Geo-information Science >
A MapReduce-based Method for Parallel Calculation of Bus Passenger Origin and Destination from Massive Transit Data
Received date: 2017-08-10
Request revised date: 2018-03-07
Online published: 2018-05-20
Supported by
National Natural Science Foundation of China, No.41471333
The Central Guided Local Development of Science and Technology Project, No.2017L3012.
Copyright
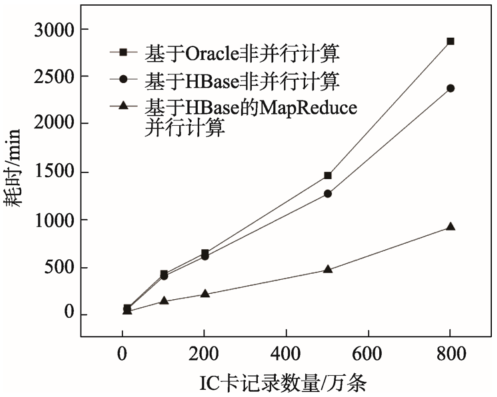
Bus passengers' origin and destinations (OD) can truly reflect travel characteristics and demands of residents, which is an important basic data for bus system evaluation, scheduling and route optimization, with significantly practical value in urban planning. Existing OD estimation methods are mostly applied to a small amount of bus data, which cannot directly and rapidly calculate mass transit passenger OD. In order to solve these problems, a parallel method for calculation of massive transit passengers' origin and destinations based on MapReduce is investigated. Firstly, database migration tool was applied to transfer massive bus data stored in relational database to HBase. Secondly, MapReduce parallel computing framework was introduced to divide the IC card data into multiple Map tasks in the light of region numbers in HBase to calculate origins. The origins are grouped and stored into HDFS by user in the Reduce function. Thirdly, the destinations are estimated by origins in parallel which are divided into multiple Map tasks according to block numbers stored in HDFS. According to the travel record of each passenger, destinations can be accurately calculated by the means of public transit chain method and history similarity. In the end, taking IC card data and GPS bus data in Xiamen from June 13 to 26, 2015 as the example, which has 295 bus lines, 16 879 661 bus records, and 14 410 058 complete OD pairs which accounted for 78.9% of IC card data. Comparing with the traditional method, the computational efficiency has substantially improved. The results illustrate that the parallel method can not only calculate bus passenger OD accurately, but also has higher computational efficiency.
WU Qunyong , SU Keyun , ZOU Zhijie . A MapReduce-based Method for Parallel Calculation of Bus Passenger Origin and Destination from Massive Transit Data[J]. Journal of Geo-information Science, 2018 , 20(5) : 647 -655 . DOI: 10.12082/dqxxkx.2018.170374
Tab. 1 Data structure of IC card表1 IC卡数据结构 |
| 行键 | 列簇 | ||||
|---|---|---|---|---|---|
| IC卡编号:刷卡时间 | IC卡编号 | 刷卡时间 | 线路编号 | 公交车辆编号 | |
Tab. 2 Data structure of bus GPS表2 公交车辆GPS数据结构 |
| 行键 | 列簇 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| GPS设备编号:GPS时间 | GPS设 备编号 | 线路 编号 | 行驶 方向 | GPS 时间 | 进出站标志 | 站点编号 | 经度 | 纬度 | |
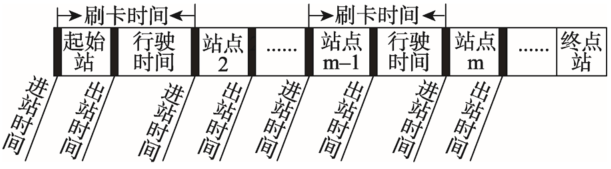
Fig. 1 The relationship between boarding time and arrival-departure time图1 乘客刷卡时间与车辆进出站时间关系示意图 |
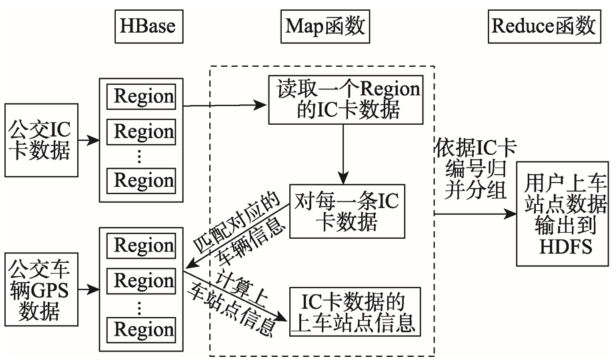
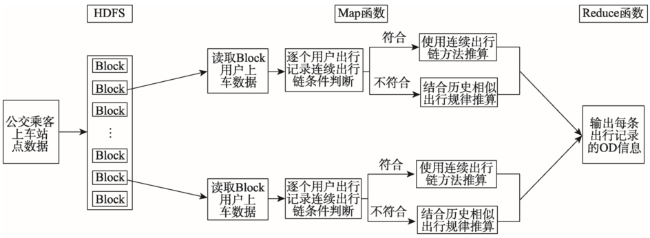
Fig. 2 The parrallel estimating flow of bus passengers boarding station图2 上车站点并行推算流程 |
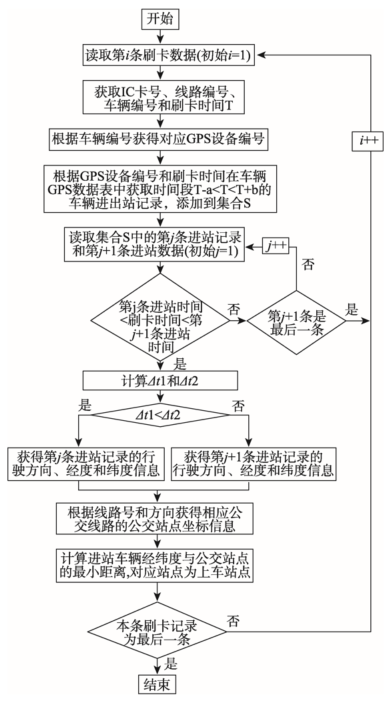
Fig. 3 The estimating flow in Map function of bus passengers boarding station图3 Map函数中推算上车站点流程 |
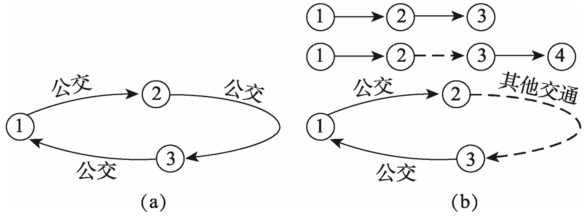
Fig. 4 Public transit trip chain图4 公交出行链示意图 |
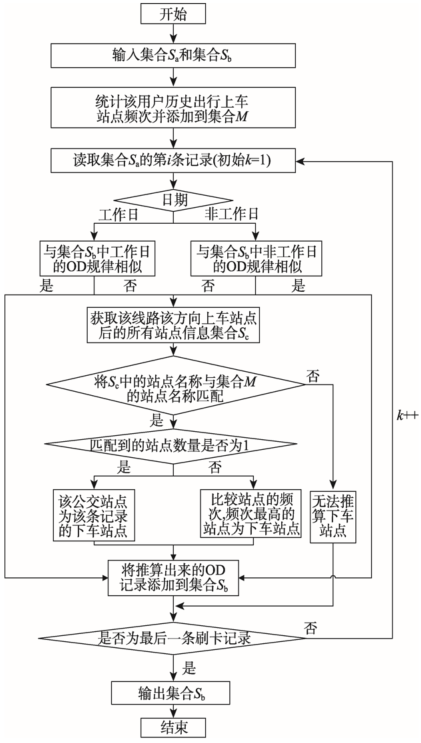
Fig. 5 The parrallel estimating flow of bus passengers destination station图5 公交乘客下车站点并行推算过程 |
Fig. 6 The destination station inference flow for continuous public transit trip chain in Map function图6 Map函数中基于连续性公交出行链下车站点推算流程 |
Fig. 7 The destination station inference flow for discontinuous public transit trip chain in Map function图7 Map函数中非连续性公交出行链下车站点推算流程 |
Tab. 3 Sample of IC card data in Xiamen表3 厦门市公交IC卡数据示例 |
| IC卡编号 | 刷卡时间 | 线路编号 | 公交车辆编号 |
|---|---|---|---|
| 5238111601 0878416539 | 2015-06-13 00:01:42 2015-06-12 18:18:52 | 000099 000129 | 8986 9318 |
Tab. 4 Sample of GPS bus data in Xiamen表4 厦门市公交车辆GPS数据示例 |
| GPS设备编号 | GPS时间 | 纬度/° | 经度/° | 行驶方向 | 进出站标志 | 站点编号 | 线路编号 |
|---|---|---|---|---|---|---|---|
| 550001313902 | 2015-06-12 18:18:52 | 24.489145 | 118.072485 | 4 | 1 | 12 | 122 |
Tab. 5 The result of origin and destination inference表5 OD推算结果 |
| IC卡编号 | 刷卡时间 | 线路编号 | 线路方向 | 上车站点 | 下车站点 | 推算依据 |
|---|---|---|---|---|---|---|
| 4078181794 | 2015-06-13 16:07:31 | 24 | 4 | 中医院 | 岳阳小区 | 历史站点频次 |
| 4078181794 | 2015-06-15 07:24:23 | 31 | 4 | 岳阳小区 | 江头市场 | 连续出行链 |
| 4078181794 | 2015-06-15 16:23:44 | 31 | 5 | 江头市场 | 岳阳小区 | 连续出行链 |
| 4078181794 | 2015-06-17 07:43:44 | 859 | 5 | 岳阳小区 | 莲花路口东 | 相似出行规律 |
| 4078181794 | 2015-06-17 07:43:46 | 859 | 5 | 岳阳小区 | 莲花路口东 | 连续出行链 |
| 4078181794 | 2015-06-17 15:39:32 | 42 | 4 | 莲花路口东 | 市行政中心 | 相似出行规律 |
| 4078181794 | 2015-06-17 15:39:33 | 42 | 4 | 莲花路口东 | 市行政中心 | 连续出行链 |
| 4078181794 | 2015-06-17 17:00:12 | 18 | 4 | 市行政中心 | 枋湖车站 | 相似出行规律 |
| 4078181794 | 2015-06-17 17:00:14 | 18 | 4 | 市行政中心 | 枋湖车站 | 连续出行链 |
| 4078181794 | 2015-06-17 17:11:25 | 45 | 5 | 枋湖车站 | 岳阳小区 | 相似出行规律 |
| 4078181794 | 2015-06-17 17:11:26 | 45 | 5 | 枋湖车站 | 岳阳小区 | 连续出行链 |
| 4078181794 | 2015-06-18 09:04:16 | 15 | 4 | 岳阳小区 | 叉车厂 | 连续出行链 |
| 4078181794 | 2015-06-18 09:25:52 | 86 | 4 | 禾山路 | 未推算出 | 无 |
Fig. 8 The comparison of computation efficiency of calculating boarding station图8 上车站点计算效率对比图 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
戴霄.基于公交IC信息的公交数据分析方法研究[D].南京:东南大学,2006.
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
[
|
| [15] |
[
|
| [16] |
[ Hu Y C, Liang J R, Liang F M. A way to get bus regional OD matrix based on mining IC card information[J].Journal of Transport Information and Safety, 2012,30(4):66-70. ]
|
| [17] |
[
|
| [18] |
|
| [19] |
|
| [20] |
[
|
| [21] |
[
|
| [22] |
[
|
| [23] |
[
|
| [24] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}