
Journal of Geo-information Science >
A Precise Description Approach on the Result of Automatic Data Matching for Geo-spatial Model
Received date: 2018-02-23
Request revised date: 2018-04-18
Online published: 2018-06-20
Supported by
National Natural Science Foundation of China, No.41631177, 41771430
National Special Program on Basic Works for Science and Technology of China, No.2013FY110900
Foundation of State Key Laboratory of Resources and Environmental Information System, No.O88RA20CYA
Public and Basic Geological Project of Guizhou Province, China, No.[2014]23, [2016]269
Copyright
With the deep and interdisciplinary development of research on modern geoscience, geo-spatial models are becoming more and more complicated. Consequently, input data required for geo-spatial models are also growing up increasingly. In order to prepare these data quickly and efficiently, a feasible approach is to automatically match shared data from internet for the input requirements of geo-spatial model(MD4GSM). Under this background, in order to automatically convert or transform those incomplete matching data during the process of MD4GSM, this paper conduct the study on the precise description method for the matching result of shared data and geo-spatial model. Firstly, it analyzes the automatic data matching process. On this basis, this paper proposes a precise description structure and its formalization method to represent the matching result. The matching result includes three essential characteristics of data content, spatial information, temporal information, as well as morphological characteristics, such as data type, format, and structure, etc. In addition, each characteristic item is described clearly and precisely by similarity, matching relation and matching extent based on XML (eXtensible Markup Language) to reveal whether the shared data and model’s input data are consistent, where the difference is and how large the difference is. If the similarity of a characteristic is 1 or that of an essential characteristic is 0, it means the characteristic completely or not meets the requirement of geo-spatial model. In this condition, there is no need to precisely describe the matching result further; otherwise the matching result of the characteristic should be described formally and precisely according to the above method. The experiment of soil potential productivity calculation in Hunan province in 2010 shows that the method can be a foundation for automatic combining data processing services and dealing with data in the next, and finally recommending data that fully meet the needs of geo-spatial model.
YANG Jie , ZHU Yunqiang , SONG Jia , LU Feng , SUN Kai , LI Weirong . A Precise Description Approach on the Result of Automatic Data Matching for Geo-spatial Model[J]. Journal of Geo-information Science, 2018 , 20(6) : 744 -752 . DOI: 10.12082/dqxxkx.2018.180113
Tab. 1 Precise description of data matching result of each characteristic表1 各特征项数据匹配结果精准表达 |
| 匹配特征项 | 匹配关系 | 匹配范围 | 相似度 | 备注说明 | ||
|---|---|---|---|---|---|---|
| 内容 | 内容概念 | 内容概念 | 相同 | 不记录 | Si=1 | |
| 上位概念 | TD概念属性项 | 0<Si<1 | ||||
| 下位概念 | SD概念属性项 | |||||
| 交叉概念 | 交叉部分概念属性项 | |||||
| 完全不同 | 不记录 | Si =0, St=0 | 当属性值不存在分类体系时,不考虑此匹配项 | |||
| 内容语义 | 分类体系 (可选) | 一致 | 不记录 | Si =1 | ||
| 不一致 | SD、TD分类标准代码 | 0<Si<1 | ||||
| 数值单位 (可选) | 一致 | 不记录 | Si =1 | 当属性值无量纲时,不考虑此匹配项 | ||
| 不一致 | SD、TD数值单位 | 0<Si<1 | ||||
| 空间 | 空间范围 | 空间拓扑 | 相同 | 不记录 | Si =1 | |
| 包含 | TD空间范围 | 0<Si<1 | 采用坐标或TD要求的行政区粒度进行对空间范围表达 | |||
| 被包含 | SD空间范围 | |||||
| 相交 | 相交部分空间范围 | |||||
| 相邻 | 不记录 | Si =0, St=0 | ||||
| 相离 | 不记录 | Si =0, St=0 | ||||
| 空间尺度 | 比例尺/分辨率 | 一致 | 不记录 | Si =1 | 矢量数据记录比例尺分母,栅格数据记录分辨率。通过空间降或升尺度实现数据的转换 | |
| 高精度 | SD、TD比例尺分母或分辨率 | 0<Si<1 | ||||
| 低精度 | ||||||
| 空间基准 | 投影 (可选) | 一致 | 不记录 | Si =1 | 当空间数据是球面坐标系时,不考虑投影匹配项 | |
| 不一致 | SD、TD投影名称及参数 | 0<Si<1 | ||||
| 坐标系 | 一致 | 不记录 | Si =1 | |||
| 不一致 | SD、TD坐标系名称及参数 | 0<Si<1 | ||||
| 时间 | 时间范围 | 时间拓扑 | 相同 | 不记录 | Si =1 | |
| 包含 | TD时间范围 | 0<Si<1 | 以TD要求的时间分辨率记录时间范围 | |||
| 被包含 | SD时间范围 | |||||
| 相交 | 相交部分时间范围 | |||||
| 邻近 | 不记录 | Si =0, St=0 | ||||
| 相离 | 不记录 | Si =0, St=0 | ||||
| 时间尺度 | 时间尺度 | 一致 | 不记录 | Si =1 | ||
| 粗粒度 | SD、TD时间尺度 | 0<Si<1 | 通过时间降或升尺度实现数据的转换 | |||
| 细粒度 | ||||||
| 形态 | 数据类型 | 数据类型 | 相同类型 | 不记录 | Si =1 | |
| 不同类型 | 0<Si<1 | |||||
| 数据格式 | 数据格式 | 相同格式 | 不记录 | Si =1 | ||
| 同家族格式 | SD、TD数据格式及版本 | 0<Si<1 | 同家族格式是指同厂商的格式,转换相对容易,如ArcGIS家族格式 | |||
| 不同格式 | ||||||
| 数据结构 (可选) | 数据结构 (可选) | 相同结构 | 不记录 | Si =1 | 当SD、TD的数据格式不是标准格式或者不公开,或是过于灵活(如TXT),则需要进一步描述数据结构 | |
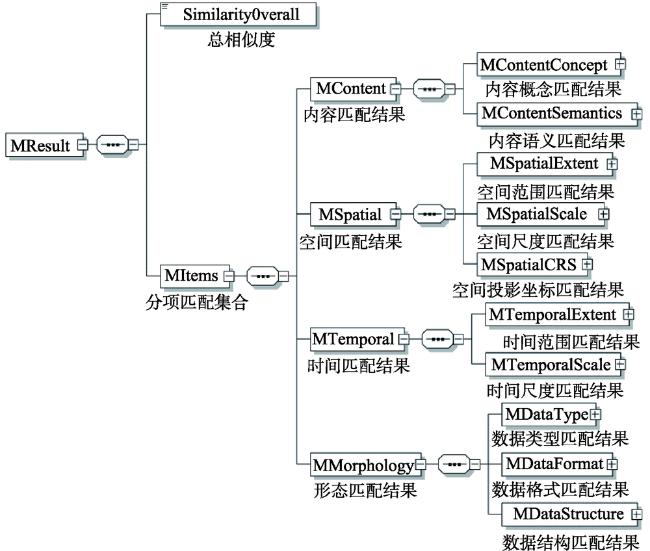
Fig. 1 XML schema of automatic data matching result for geo-spatial models图1 地理空间模型自动数据匹配结果XML模式图 |
Fig. 2 XML schema text of automatic data matching result for geo-spatial models图2 地理空间模型自动数据匹配结果XML模式文本(XML Text) |
Tab. 2 Characteristics of TD and SD表2 目标输入数据与共享源数据特征描述 |
| 特征项 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | 内容 | 空间 | 时间 | 形态 | ||||||
| 内容概念 | 内容语义 | 空间范围 | 空间尺度 | 空间基准 | 时间范围 | 时间尺度 | 数据类型 | 数据格式 | 数据结构 | |
| 模型应用需要的输入数据 | ||||||||||
| 年均降雨量(TD1) | 降雨量 | 数值单位:mm | 湖南省 | 1 km | WGS84坐标系,Albers投影 | 2010年 | 年平均 | 栅格 | Geotiff | - |
| Geodata.CN共享数据 | ||||||||||
| 中国1 km栅格逐年平均降雨数据(SD11) | 降雨量 | 数值单位:mm | 中国 | 1 km | WGS84坐标系,Albers投影 | 2000-2010年 | 年平均 | 栅格 | Geotiff | - |
| 中国多年500 m分辨率平均降雨分布图(SD12) | 降雨量 | 数值单位:mm | 中国 | 500 m | WGS84坐标系,Albers投影 | 建站-1996年 | 多年 平均 | 栅格 | ArcGIS Coverage | - |
| 中国30 m分辨率的降雨侵蚀力图(SD13) | 降雨 侵蚀力 | 数值单位:MJ·mm/ha·h·a | 中国 | 30 m | WGS84坐标系,Albers投影 | 1981-2010年 | 多年 平均 | 栅格 | ESRI Grid | - |
| 中原经济区近百年逐月降雨数据库(SD14) | 降雨量 | 数值单位:mm | 中原 城市群 | 2 km | 西安80坐标系,Albers投影 | 2000-2012年 | 逐月 | 栅格 | ESRI Grid | - |
| …… | ||||||||||
Fig. 3 Precise representation of the matching result of TD1-SD11 based on XML图3 基于XML的TD1-SD11匹配结果精准表达 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
|
| [4] |
[
|
| [5] |
[
|
| [6] |
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
[
|
| [11] |
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
[
|
| [21] |
[
|
| [22] |
[
|
| [23] |
[
|
| [24] |
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
[
|
| [32] |
|
| [33] |
Open Grid Forum. Data Format Description Language (DFDL) v1.0 Specification.2011, .
|
| [34] |
[
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}