
Journal of Geo-information Science >
SA*: A Multi-thread Path Routing Algorithm
Received date: 2018-01-02
Request revised date: 2018-03-10
Online published: 2018-06-20
Supported by
National Natural Science Foundation of China, No.61432016, 61303047
Guangdong Pre-national project, No.2014GKXM054
Guangdong Province Key Laboratory of Popular High Performance Computers, No.2017B030314073
Copyright
Path routing problem is a fundamental problem in many applications on road networks. The A* algorithm is an efficient method to find the point-to-point path. Road networks with Cartesian coordinates can provide Euclidean distance as a heuristic function to guide the search direction of A*, then A* can simply and intuitively outperforms the classic Dijkstra's algorithm. However, Euclidean distance is a fairly relaxed lower bound of the real distance. It limits the potential of pruning more search space of A* on road networks. Higher performance is needed to fit the real-time requirement in the application on large-scale networks. Parallel computing is an effective approach to accelerate many algorithms. However, there are strong data dependencies between iterations of A*, and each iteration has little potential parallelism because of the low-dimensional property of road network. Thus, it is difficult to efficiently exploit the availability of multiple cores with the standard A* algorithm. In this paper, we propose Segmented A* (SA*) algorithm, which is more adaptable to modern multi-core CPU platform than A*. It selects some waypoints that split the required shortest path into several segments, then it searches on each segment separately and concatenates these segments as an approximate result. SA* performs better than A* on account of two factors. One is that sequential SA* can prune more search space than A*. The other is that the searches of SA* on segments can be parallelized, so SA* can make better use of multi-core CPU. The selection of waypoints has a key impact on both calculation performance and the accuracy of path. To exploit the benefit from segmented search and meanwhile reduce the performance overhead from this selection, we consider using some low-cost heuristic strategies to select the waypoints before handling each path routing sub-problem. At first, we rapidly calculate a rough path as a guidance, then select the nodes in this rough path that uniformly split the path to several segments. We can easily guarantee that each segment has the same number of nodes. This split has more possibility to lead to a balanced search space in parallel calculating each segment. In our experiments, using 16 cores, SA* can be 30 times faster than A* on a large-scale real-world road network with a loss of path accuracy less than 10%.
Key words: multi-thread; parallel computing; path routing; heuristic search; road network
SUN Jingwei , SUN Guangzhong , ZHAN Shiyan , MAO Rui , ZHOU Yinghua . SA*: A Multi-thread Path Routing Algorithm[J]. Journal of Geo-information Science, 2018 , 20(6) : 753 -761 . DOI: 10.12082/dqxxkx.2018.180019
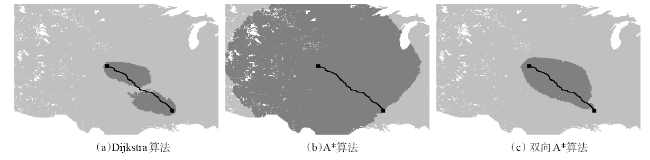
Fig.1 Comparison of search space of different algorithms图1 不同算法的搜索空间比较 |
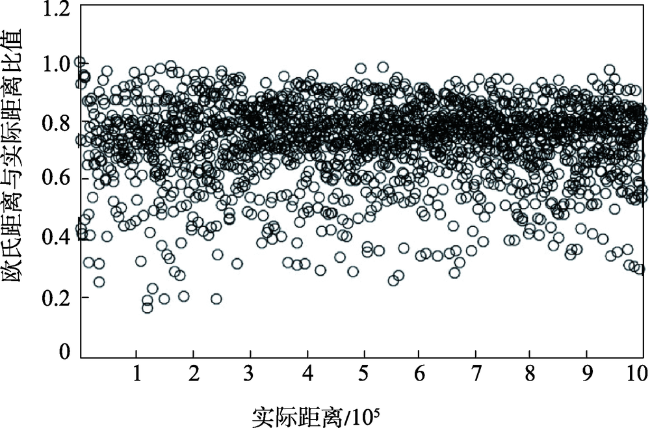
Fig. 2 The estimation accuracy using Euclidean distance图2 使用欧氏距离进行估计的精度 |
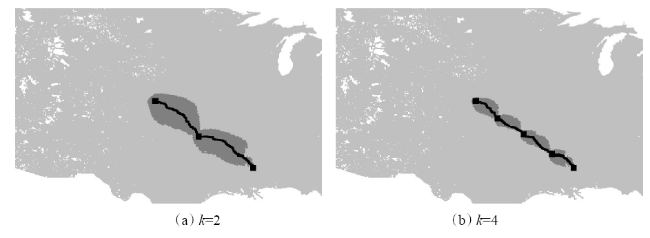
Fig. 3 The search space of SA*图3 SA*的搜索空间示意图 |
Tab. 1 Basic information of dataset used in experiment表1 数据集的基本信息 |
| 数据名 | 结点数 | 边数 |
|---|---|---|
| USA | 23 947 347 | 58 333 344 |
| W | 6 262 104 | 15 248 146 |
| E | 3 598 623 | 8 778 114 |
| CAL | 1 890 815 | 4 657 742 |
| NE | 1 524 453 | 3 897 636 |
| NW | 1 207 945 | 2 840 208 |
Tab. 2 Comparison of average calculation time cost (in milliseconds) using different methods表2 不同方法的平均计算时间(ms) |
| 方法 | 分段 | NW | NE | CAL | E | W | USA |
|---|---|---|---|---|---|---|---|
| A* | N/A | 105 | 129 | 178 | 318 | 423 | 1524 |
| SA*(line) | k=2 | 44 | 50 | 79 | 131 | 146 | 513 |
| k=4 | 22 | 35 | 39 | 64 | 64 | 200 | |
| k=8 | 14 | 32 | 20 | 42 | 34 | 99 | |
| k=16 | 11 | 33 | 13 | 39 | 24 | 72 | |
| SA*(path) | k=2 | 38 | 50 | 68 | 116 | 137 | 465 |
| k=4 | 15 | 22 | 27 | 46 | 52 | 169 | |
| k=8 | 8 | 14 | 12 | 23 | 24 | 75 | |
| k=16 | 5 | 11 | 6 | 15 | 14 | 47 |
Tab. 3 Comparison of average relative error using different methods表3 不同方法的平均相对误差(%) |
| 方法 | 分段 | NW | NE | CAL | E | W | USA |
|---|---|---|---|---|---|---|---|
| SA*(line) | k=2 | 6.5 | 6.4 | 6.5 | 4.5 | 5.1 | 1.9 |
| k=4 | 17.0 | 13.3 | 17.0 | 12.2 | 13.4 | 5.5 | |
| k=8 | 36.5 | 26.2 | 36.5 | 23.1 | 30.1 | 12.5 | |
| k=16 | 66.8 | 49.1 | 66.7 | 45.5 | 61.2 | 33.1 | |
| SA*(path) | k=2 | 3.2 | 1.4 | 3.1 | 1.7 | 2.5 | 1.8 |
| k=4 | 5.8 | 3.3 | 5.8 | 3.6 | 4.7 | 3.4 | |
| k=8 | 7.7 | 5.2 | 8.2 | 5.5 | 6.9 | 5.3 | |
| k=16 | 9.4 | 7.1 | 10.1 | 7.4 | 8.8 | 7.1 |
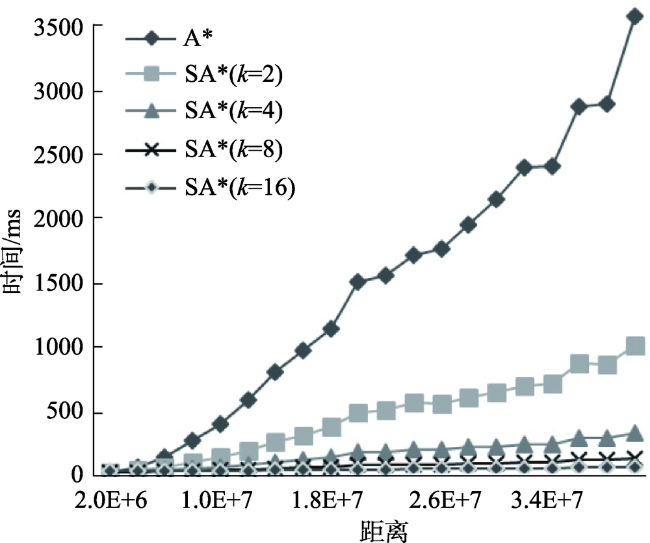
Fig. 4 The trend of time cost with the increase of real distance图4 各种方法的计算时间随结点的距离增长的变化趋势 |
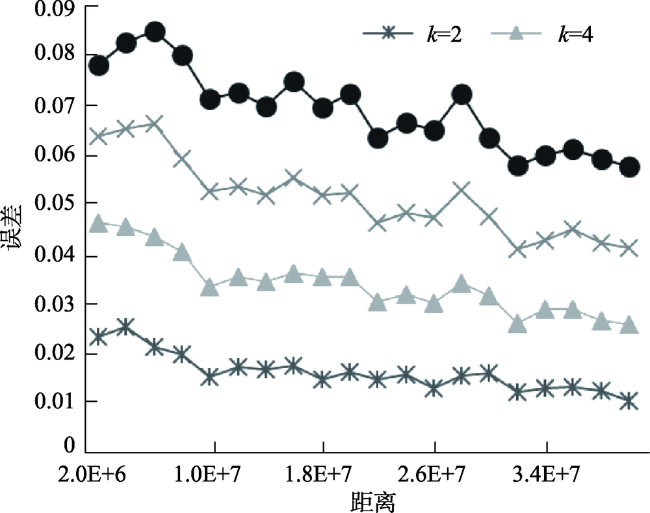
Fig. 5 The trend of related error with the increase of real distance图5 各种方法的相对误差随结点的距离增长的变化趋势 |
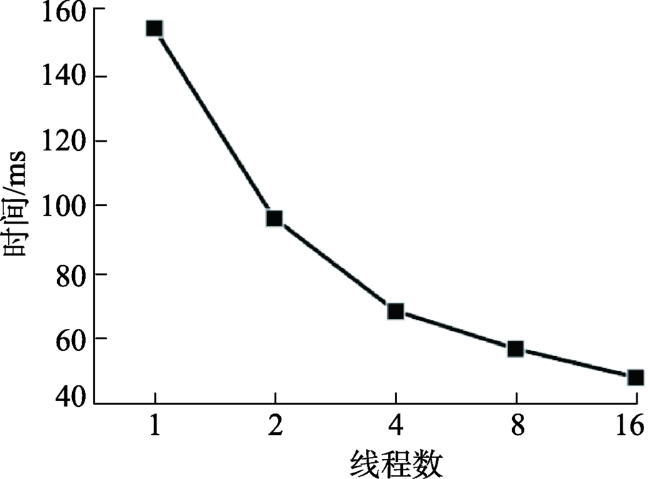
Fig. 6 The time cost of SA*(k=16) in different parallel scale图6 SA*(k=16)在不同线程下的计算时间 |
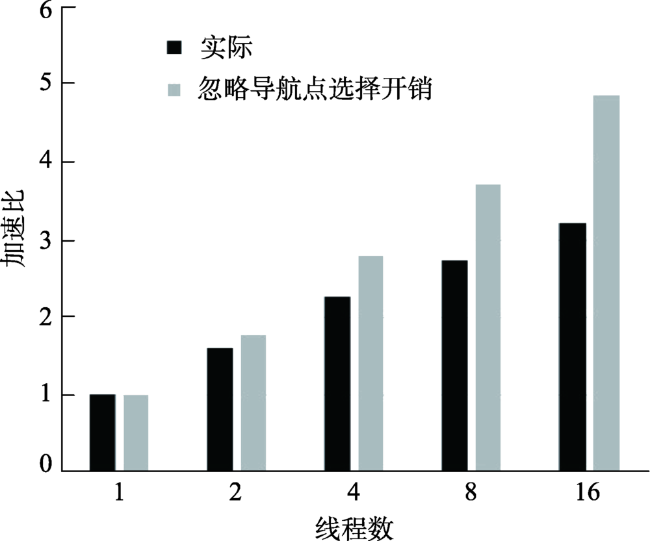
Fig. 7 Speedup ratios of SA*(k=16) with and without navigation point selection overhead图7 SA*(k=16)的实际加速比和忽略导航点选择开销加速比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
[
|
| [26] |
[
|
| [27] |
[
|
| [28] |
[
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}