
Journal of Geo-information Science >
Detecting Individual Stay Areas from Mobile Phone Location Data Based on Moving Windows
Received date: 2018-01-31
Request revised date: 2018-03-09
Online published: 2018-06-20
Supported by
National Natural Science Foundation of China, No.41771441
Basic Research Project of Shenzhen City, No.JCYJ20170307164104491
Natural Science Foundation of Guangdong Province, No.2016A050503035
Copyright
With the development and popularization of mobile phones, mobile phone location data have become an important source of data for analyzing individual mobility characteristics. With these location data, many studies can be performed at a fine spatiotemporal scale in fields such as population management, urban planning, transportation analysis and health intervention. Detection of individual stay areas is an important and basic step in many studies based on mobile phone location data. However, the sparse spatial and temporal resolution of raw mobile phone location data and data noise caused by location oscillation and location drift introduce great challenges in effectively detecting individual stay areas from raw mobile phone location data. Considering the spatiotemporal continuity of individual behavior, this study proposes an incremental clustering algorithm based on a moving window to improve the accuracy of detecting individual stay areas from mobile phone location data. Specifically, the proposed algorithm first sorts the raw records in chronological order. Then, the algorithm consecutively examines the adjacent records with a given distance threshold. Records that satisfy the rule will be added to the current cluster. For each unqualified record, the algorithm extracts a series of records within a moving window and calculates the spatial distance of these records as a criterion for clustering. The time interval between the unqualified record and the selected records should be less than a given time threshold, which is also the width of the moving window in this proposed algorithm. In this step, the algorithm treats some unqualified records as location drift records or location oscillation records based on the detection rules and aggregates them into the current cluster, and unqualified records that do not fit the detection rules are excluded from the current cluster and the algorithm creates a new cluster for the unqualified records. Finally, the algorithm calculates the location and temporal information of each valid cluster as the parameters of the corresponding stay area and constructs a stay area sequence for each mobile user. We compared the results of the proposed algorithm with those obtained using the ST-DBSCAN and SMoT algorithms. The experiment applied the three algorithms to a mobile phone location dataset in Shenzhen that is a type of Call Detail Records, and the results show that the proposed algorithm significantly improves the accuracy by up to 35% for detecting individual stay areas from sparse mobile phone location data compared to the other two algorithms. Due to privacy issues associated with the government or telecom operators, the temporal resolution of large-scale mobile phone location data used in recent research is usually sparse, and thus the proposed algorithm can be used to improve the effectiveness of detecting individual stay areas and to provide reliable results for many studies based on mobile phone location data.
LIN Nan , YIN Ling , ZHAO Zhiyuan . Detecting Individual Stay Areas from Mobile Phone Location Data Based on Moving Windows[J]. Journal of Geo-information Science, 2018 , 20(6) : 762 -771 . DOI: 10.12082/dqxxkx.2018.180087
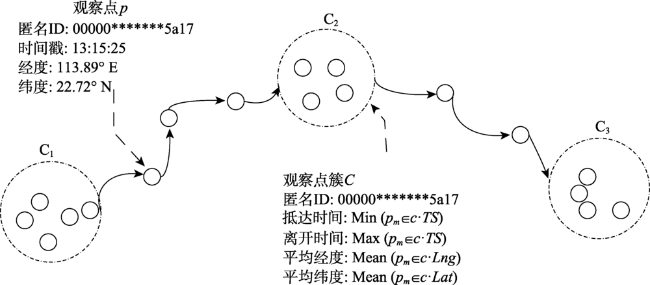
Fig. 1 The sketch of detecting individual stay areas from raw mobile phone location data图1 手机定位数据中的个体停留区域示意图 |
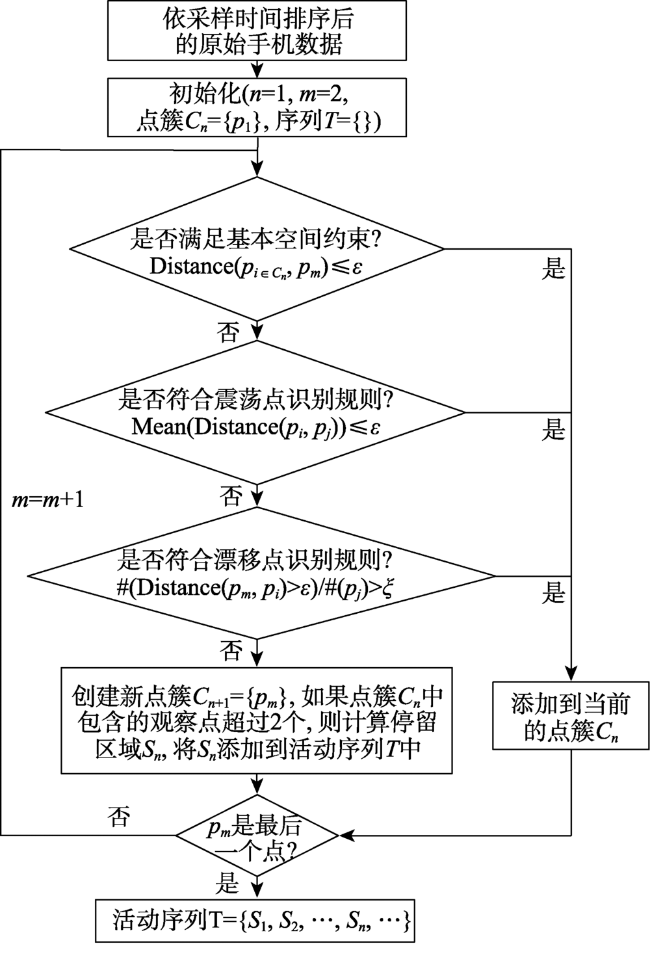
Fig. 2 The flow chart of detecting individual stay areas from raw mobile phone location data图2 个体停留区域识别流程图 |
Tab. 1 Format of the mobile phone location dataset表1 手机定位数据格式 |
| userID | TS | 经度/° | 纬度/° |
|---|---|---|---|
| 460********9251 | 2013-**-**T 0:01:23.000Z | 114.**** | 22.**** |
| 460********2565 | 2013-**-**T 07:07:55.000Z | 114.**** | 22.**** |
| 460********3757 | 2013-**-**T 10:14:11.000Z | 114.**** | 22.**** |
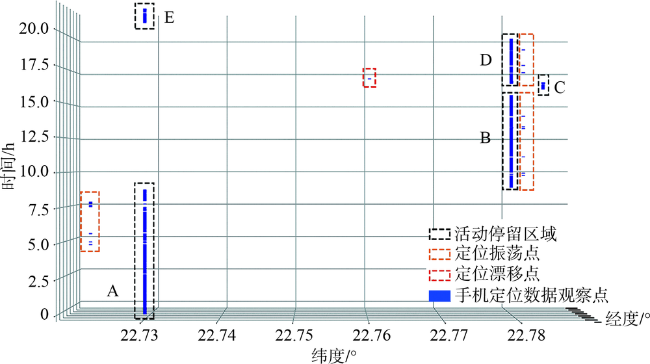
Fig. 3 Manual annotation of individual stay areas based on mobile phone location data图3 基于手机定位数据人工标注个体停留区域的示意图 |
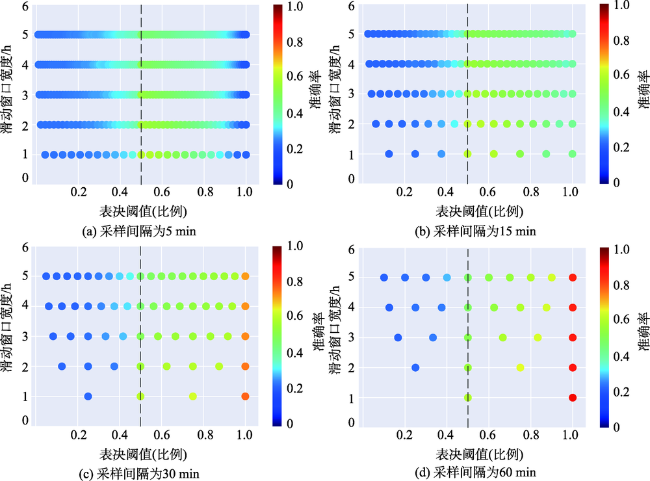
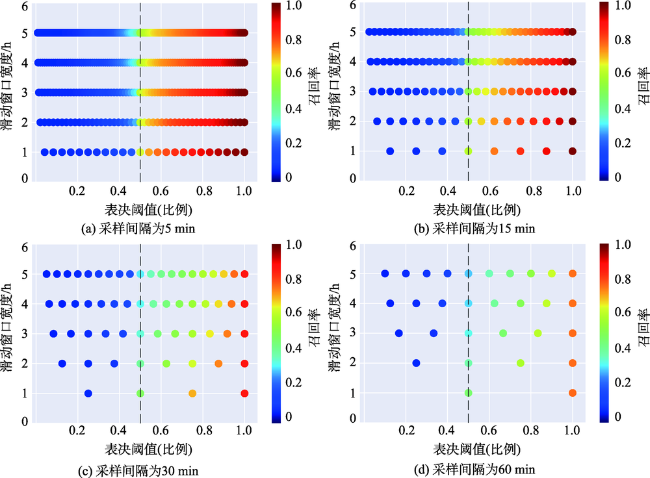
Fig. 4 The accuracy changes of TW-cluster algorithm with different δ and ξ图4 算法准确率随不同滑动窗口宽度及表决阈值的变化情况 |
Fig. 5 The recall changes of TW-cluster algorithm with different δ and ξ图5 算法召回率随不同滑动窗口宽度及表决阈值的变化情况 |
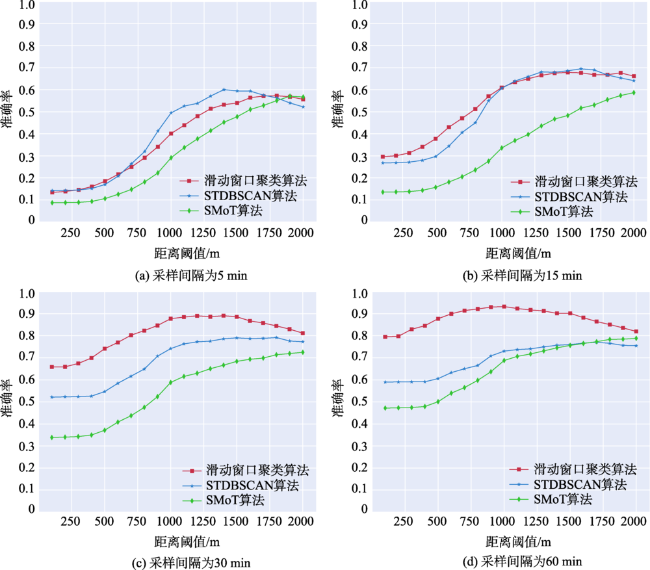
Fig. 6 The accuracy of different clustering algorithms with different sampling intervals图6 不同采样间隔下的算法准确率比较 |
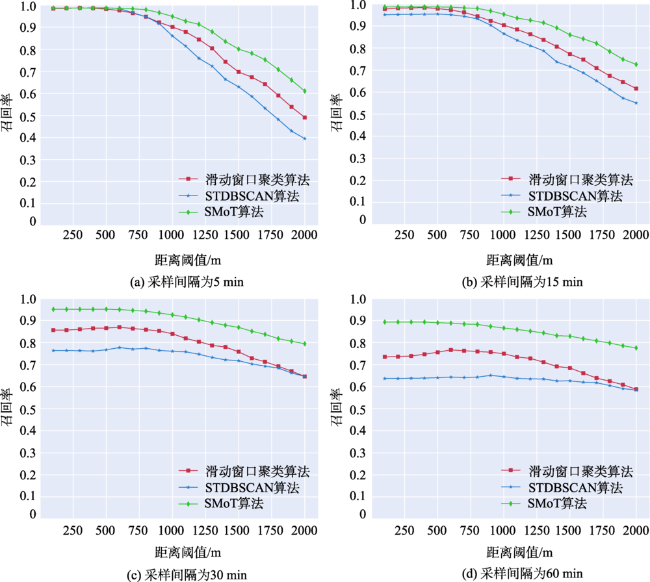
Fig. 7 The recall of different clustering algorithms with different sampling intervals图7 不同采样间隔下的算法召回率比较 |
The authors have declared that no competing interests exist.
| [1] |
[中国工业和信息化部.2017年通信运营业统计公报[EB/OL] .2018-02-02
[ Ministry of Industry and Information Technology of the People’s Republic of China. Statistical bulletin of communications operations in 2017[EB/OL]. 2018-02-02.]
|
| [2] |
|
| [3] |
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
[
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}