
Journal of Geo-information Science >
Analysis on Spatial Distribution Characteristics of Restaurant Based on Network Spatial Point Model
Received date: 2017-12-08
Request revised date: 2018-02-02
Online published: 2018-06-20
Supported by
National Natural Science Foundation of China, No.41771096
Project of Internation as well as Hongkong, Macao&Taiwan Science and Technology Cooperation Innovation Platform in Universities in Guangdong Province, No.2014KGJHZ009
Copyright
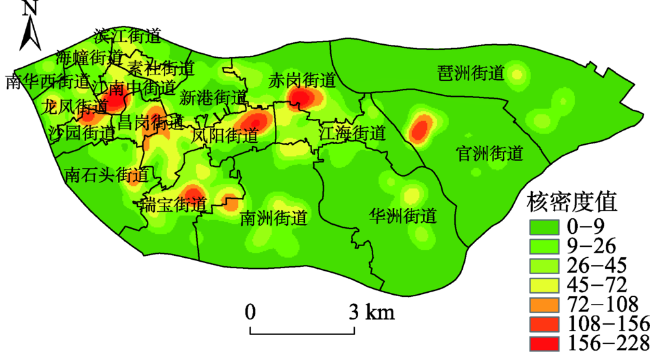
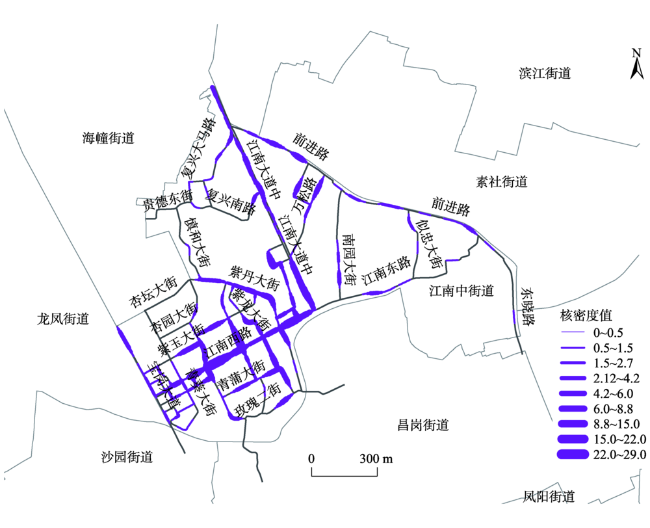
The catering industry has been considered as one of the most important indicators concerning economic development of a city. Using appropriate methods to study catering industry has been playing an important part in research fields such as city planning, business location and economic development. Many restaurants in a city can be abstracted as point objects in the study of geography. It is one of the most commonly used methods to study the spatial layout of facility events by using spatial point patterns. The traditional point pattern analysis methods are basically based on the Euclidean distance and assume that the plane space is a homogeneous and isotropic space. However, many geo-objects are usually distributed on the road network or along the road network, such as restaurants, banks, supermarkets and road traffic accidents. If the traditional method of plane space point analysis is applied to the trend events occurring along the road network, wrong aggregation mode may occur. By using the network spatial point pattern analysis method, the shortest path distance instead of the Euclidean distance can be used to study the distribution characteristics of the event points, and more accurate spatial analysis results can be obtained. Take Haizhu District of Guangzhou city as an example, on the basis of restaurants POI (point of interest) data, Kernel density estimation is adopted to analyze spatial distribution characteristics of restaurants. The network kernel density method is used to investigate the distribution characteristics of the hot roads, and double variable K function method is applied to analyze the relations between distribution of restaurants and bus stations and residential areas. The spatial pattern of Haizhu District restaurants shows much more dense in the West and comparatively sparser in the East. The restaurant hot spots are mainly concentrated along the streets of Jiangnan West and Jiangnan Zhong, and the density of the restaurants decreases with the increase of the distance from the hot spots. The degree of aggregation of restaurants, bus stations and residential areas is also investigated under the road network structure. The results show that restaurants have strong aggregation relations with bus stations, which indicates that the restaurant tends to close to the traffic stations, but have no significant aggregation relationship with the residential areas. As far as the spatial point objects along streets are concerned, better results can be obtained by using network analysis of spatial point pattern.
Key words: network space point pattern; K function; kernel density; spatial pattern; restaurant
ZENG Xuan , CUI Haishan , LIU Yihua . Analysis on Spatial Distribution Characteristics of Restaurant Based on Network Spatial Point Model[J]. Journal of Geo-information Science, 2018 , 20(6) : 837 -843 . DOI: 10.12082/dqxxkx.2018.170596
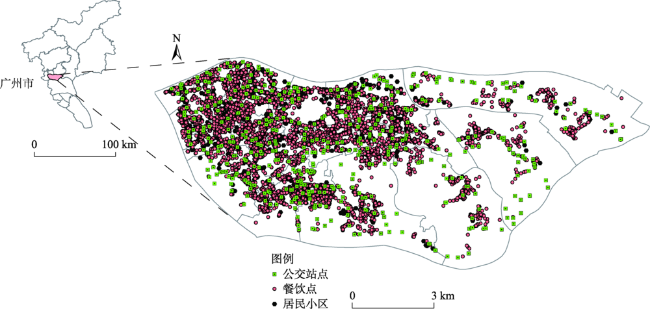
Fig.1 Location map of Haizhu district图1 研究区区位示意图 |
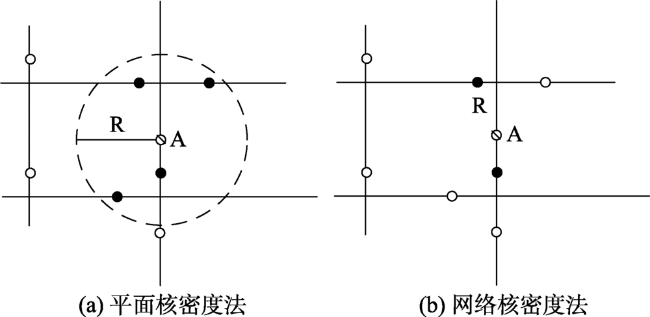
Fig. 2 Comparisons of results between the planar kernel density estimates and the network kernel density estimates图2 平面核密度估计与网络核密度估计结果对比 |
Fig. 3 Hotspot distribution map of restaurants in Haizhu District图3 海珠区餐饮店热点分布图 |
Fig. 4 Restaurants distribution map of the network kernel density estimation in Jiangnanzhong street图4 江南中街道餐饮店网络核密度分布图 |
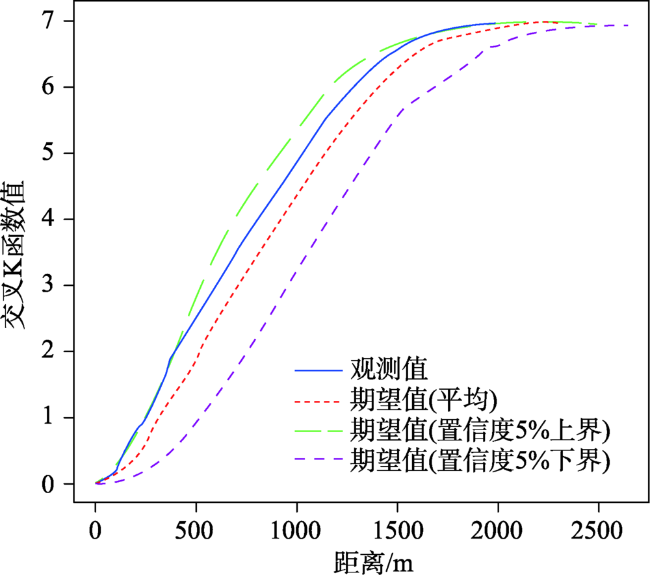
Fig.5 Network cross K-function for restaurant and bus station图5 餐饮店与公交站交叉K函数曲线 |
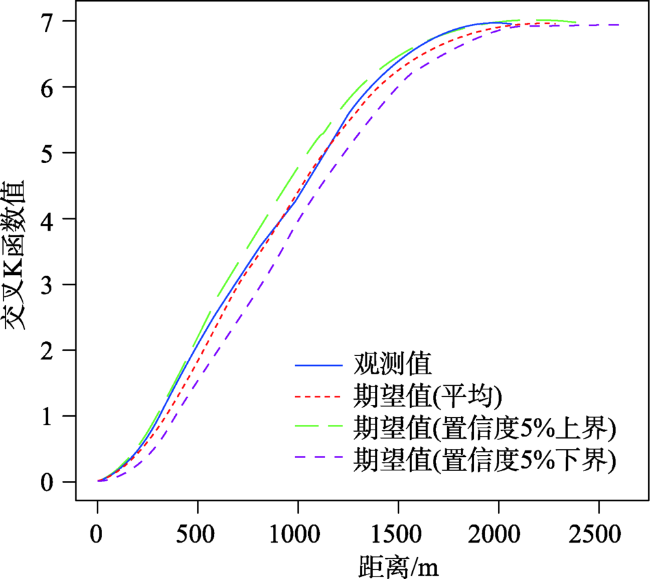
Fig. 6 Network cross K-function for restaurant and residential areas图6 餐饮店与住宅小区交叉K函数曲线 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
海珠年鉴. 广州市海珠区年鉴编纂委员会[M].广州:广东省经济出版社,2016.
[ Haizhu Yearbook.Guangzhou Haizhuqu District Yearbook Compilation Committee[M]. Guang Zhou: Guangdong Economic Press, 2016. ]
|
| [21] |
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}