
Journal of Geo-information Science >
Improved Adaptive Spatial Points Clustering Algorithm Based on Minimum Spanning Tree
Received date: 2018-01-30
Request revised date: 2018-04-15
Online published: 2018-07-13
Supported by
National Natural Science Foundation of China, No.41471118, 41771150, 41771188; Youth Project of Hengyang Normal university, No.16A01,17A02
Copyright
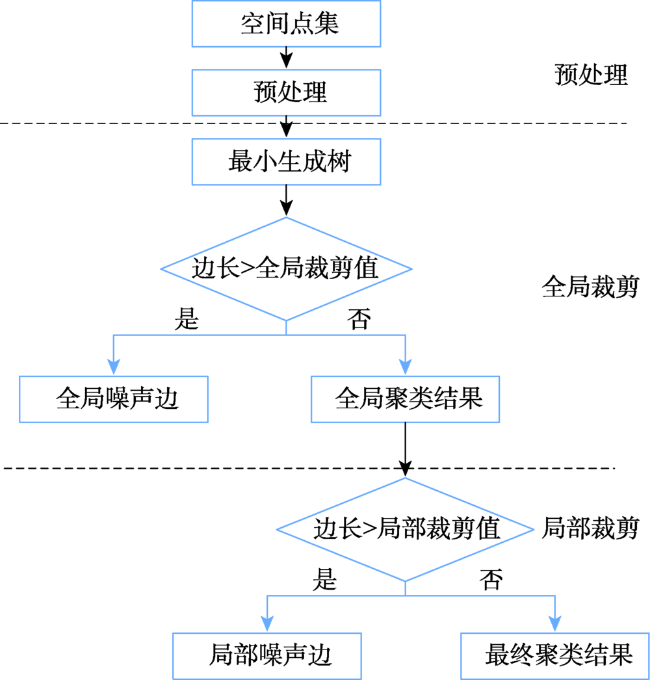
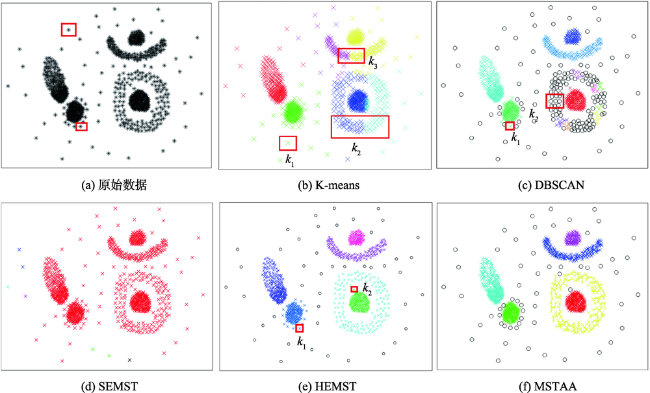
In this paper, we proposed an improved adaptive spatial point clustering algorithm based on minimum spanning tree (MSTAA in abbreviation) to solve the problems existed in the traditional clustering algorithms. The first problem of these classical clustering algorithms is that the noise edges are determined using the global invariant. Another one is that the initial clustering parameters such as edge weight tolerance, edge variation factor, the number of clusters and initial clustering centers are determined by the users empirically. Furthermore, these algorithms can't find the noise edges at the local level. Based on these problems mentioned above, the algorithm put forward in this article aims to overcome the influence of subjective factors by defining two clipping factors. These trimming factors do not need to be determined by the users and can be automatically obtained according to the statistical features of the side length in the minimum spanning tree. The detailed realization process is as follows. In the first place, the pruning operation on the minimum spanning tree from the global level is carried out, which can eliminate the noises in the global environment. After the first round of tailoring, the initial minimum spanning tree becomes sub-tree collections. In the second place, in order to eliminate the noises at the local level, the algorithm performs the second round of pruning operation by setting the adaptive local cutting factor in the light of the side length statistics of each sub-tree. After the above two rounds of cutting, the MSTAA algorithm will get the final clustering result. In order to validate the effectiveness of the algorithm, both a simulated data and a practical application are adopted. By comparing with 4 classical clustering algorithms (k-means, DBSCAN, SEMST, HEMST), we find that the improved algorithm presented in this paper could find clusters of arbitrary shape and density in the environment where no one provides experience parameters. At the same time, not only does the MSTAA algorithm eliminate the obvious global noise points, but also it can distinguish noise points at the local environment so as to ensure a high similarity degree of cluster point set. All of the features of the MSTAA algorithm mentioned above make it possible to automatically mine hidden information behind spatial point data.
Key words: Minimum Spanning Tree; global clipping; local clipping; adaptive; clustering
YAN Jinbiao , ZHENG Wenwu , DUAN Xiaoqi , DENG Yunyuan , GUO Yuanjun , HU Zui . Improved Adaptive Spatial Points Clustering Algorithm Based on Minimum Spanning Tree[J]. Journal of Geo-information Science, 2018 , 20(7) : 887 -894 . DOI: 10.12082/dqxxkx.2018.180081
Fig. 1 The flow chart of MSTAA algorithm图1 MSTAA算法流程图 |
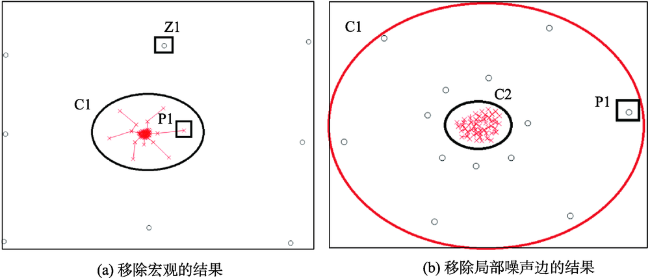
Fig. 2 Remove the noises in the minimum spanning tree图2 剔除最小生成树中的噪声边 |
Fig. 3 Clustering results图3 算法聚类结果 |
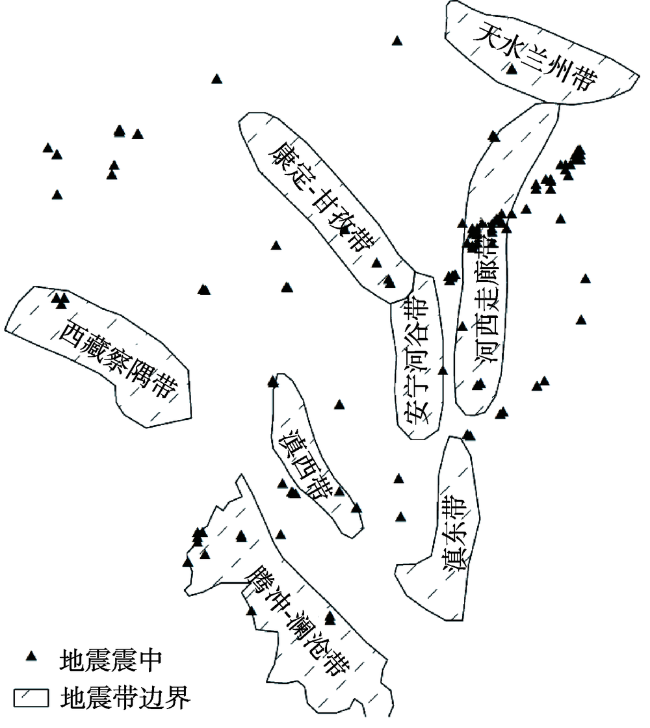
Fig. 4 The epicenter of the earthquake图4 地震震中位置 |
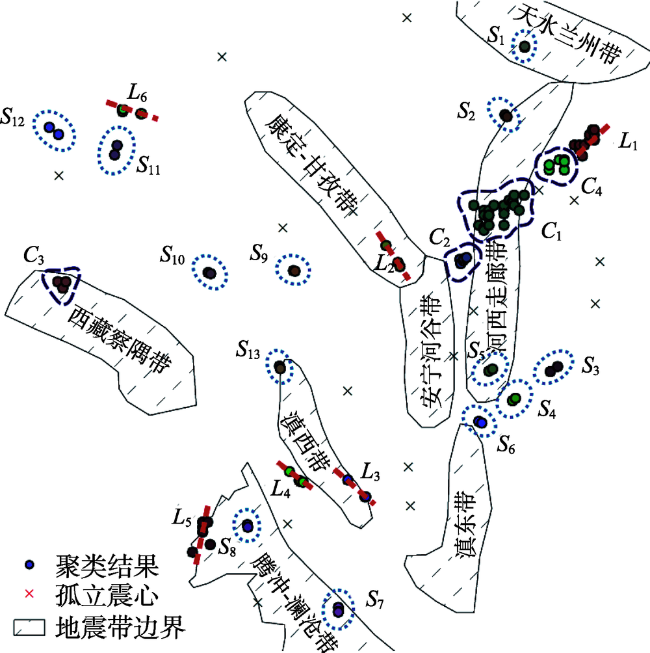
Fig. 5 Spatial clustering results on seismic data by MSTAA图5 MSTAA对地震数据的聚类结果 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
[
|
| [7] |
|
| [8] |
|
| [9] |
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
[
|
| [14] |
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
|
| [21] |
|
| [22] |
[
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}