
Journal of Geo-information Science >
Mobility Prediction of Suspect Based on Historical Crime Records
Received date: 2018-01-16
Request revised date: 2018-04-16
Online published: 2018-07-13
Supported by
National Natural Science Foundation of China, No.41401524;Guangxi Natural Science Foundation, No.2015GXNSFBA139191;Open Research Program of Key Laboratory of Police Geographic Information Technology, Ministry of Public Security, No.2016LPGIT03;Open Research Program of Key Laboratory of Environment Change and Resources Use in Beibu Gulf (Guangxi Teachers Education University), Ministry of Education, No.2014BGERLXT14;Scientific Project of Guangxi Education Department , No.KY2015YB189, KY2016YB281
Copyright
Suspect mobility prediction enables proactive experiences for location-aware crime investigations and offers essential intelligence to the crime initiative prevention. Recent practical studies and Rational Choice Theory suggest that the crime suspect mobility is predictable. The previous approaches for suspect location prediction focused on the forecasting the spatial likelihood of anchor point (i.e. the residential or future offending place) for a suspect who committed a series of crimes. However, the monitoring data are usually poor in availability for tracking suspects. Thus, the existing methodologies failed to capture the complex social location transition patterns for suspects and lacked the capacity to address the mobility data scarcity issue. Therefore, it is intractable to reflect suspects mobility patterns from sparse monitoring data, which reduces the effectiveness of case analysis and crime risk prediction. To address this challenge, we presented a novel Crime Records enhanced Location Prediction (CReLP) model. By merging the historical crime cases information by a collaborative filtering process, the CReLP model the estimate the visiting intensity at any arbitrary spatiotemporal node for and individual suspect. Particularly, we first obtained basic spatial and temporal units by partitioning the target areas into 100×100 2D grids and segmenting the daytime into 24 time bins. Second, we built a 3D tensor to model the social mobilities of all suspects with each entry in it representing the visiting intensity at each location and each time bin for each suspect. Meanwhile, this approach employed two matrices to express general movement trends among all suspects. Third, we created a suspect-correlation matrix relying on the spatial and temporal proximities of their historical crime events, as well as the similarities between their personal properties. At last, the missing entries in the 3D tensor were filled through the joint decomposition across all tensors and matrices mentioned above. This way were able to uncover the spatial distribution pattern for each suspect at any time. We evaluated the CReLP model using a real-world suspect mobility dataset collected from 241 suspects over 6 months with about 19 thousand location records. The results showed that our model outperformed three baseline approaches by 32% to 63% at RMSE (Root Mean Square Error) and 14% to 26% in TMSD (Top-k Minimum Search Distance), respectively. Finally, a suspect's visiting spatial distributions of the ground truth and predicting results between 8 to 12 a.m. were illustrated to show the performance of our proposed model.
DUAN Lian , DANG Lanxue , HU Tao , ZHU Xinyan , YE Xinyue . Mobility Prediction of Suspect Based on Historical Crime Records[J]. Journal of Geo-information Science, 2018 , 20(7) : 929 -938 . DOI: 10.12082/dqxxkx.2018.180036
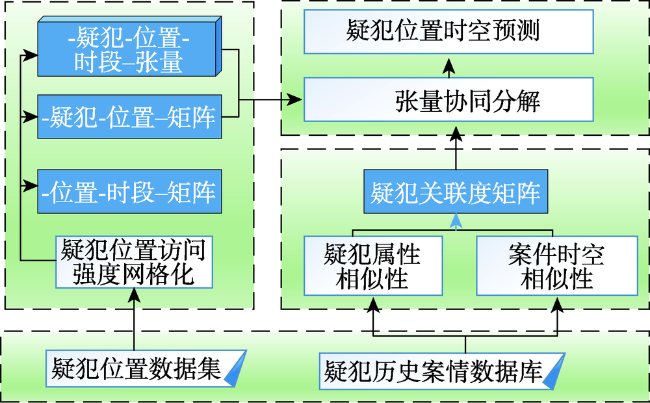
Fig. 1 System Architecture图1 系统流程图 |
Fig. 2 Gridding Map (Colors represent neighborhoods)图2 网格划分(颜色代表街区) |
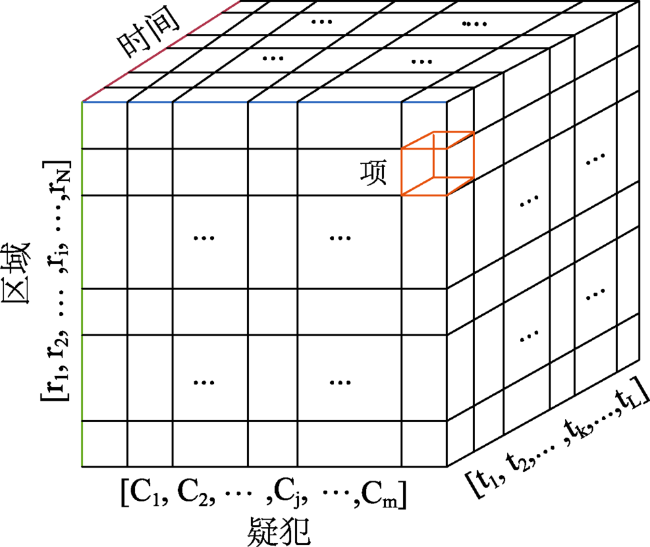
Fig. 3 Suspect-location-time tensor图3 “疑犯-位置-时段”张量 |
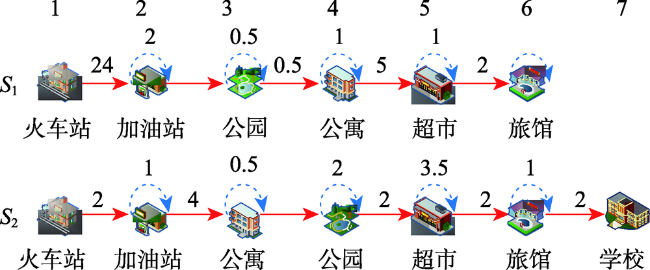
Fig. 4 Historical crime-events trajectories图4 历史犯罪事件轨迹 |
Table 1 POIs categories表1 POI类型 |
| POI大类 | POI中类 | POI小类 |
|---|---|---|
| 餐饮 | 11 | 47 |
| 汽车服务 | 9 | 16 |
| 运动休闲 | 7 | 51 |
| 地产小区 | 3 | 10 |
| 购物 | 18 | 45 |
| 生活服务 | 19 | 32 |
| 医疗卫生 | 10 | 27 |
| 宾馆酒店 | 4 | 9 |
| 旅游景点 | 5 | 18 |
| 政府机构 | 7 | 116 |
| 文化教育 | 8 | 36 |
| 交通设施 | 11 | 27 |
| 金融行业 | 7 | 8 |
| 地名地址 | 5 | 35 |
| 公司企业 | 3 | 18 |
| 公共设施 | 4 | 4 |
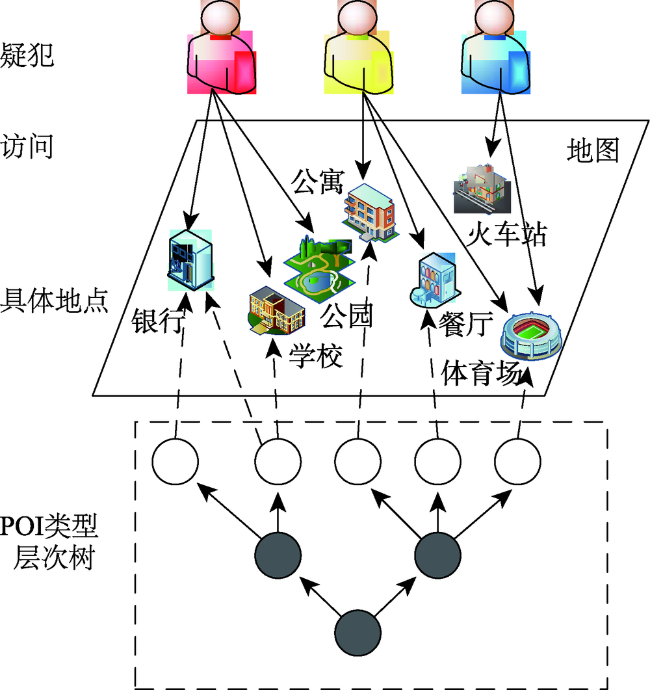
Fig. 5 POI Hierarchy Tree图5 POI类型层次树 |
| 算法1 协同张量分解算法 |
|---|
| Input: ,an error threshold ε Output: Initialize withsmall random values; Set as step size; While losst-losst+1< Foreach or |
注:“”表示Kronecker乘积 |
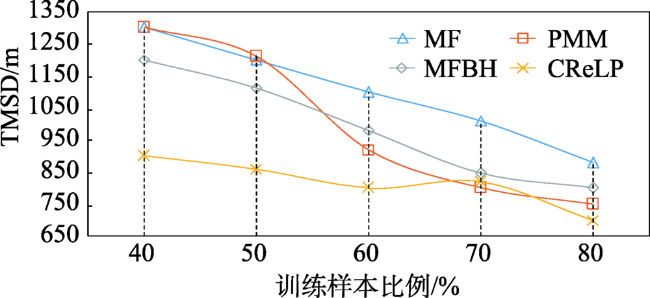
Fig. 6 TMSD changes with increasing training data图6 TMSD随训练样本数量的变化 |
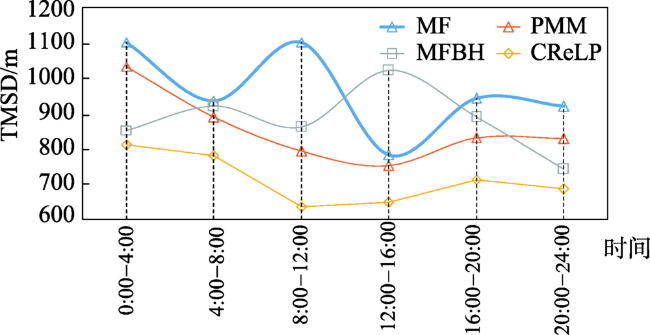
Fig. 7 TMSD changes with changing day time图7 TMSD随时间的变化 |
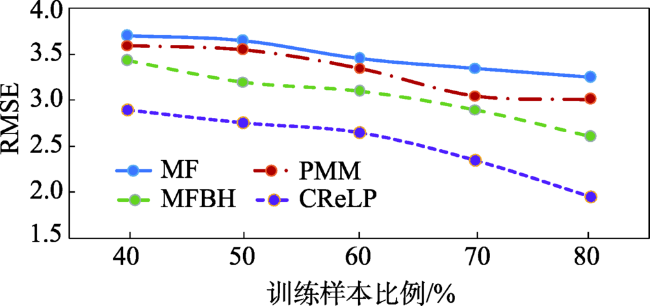
Fig. 8 RMSE with increasing training data图8 RMSE随训练样本数量的变化 |
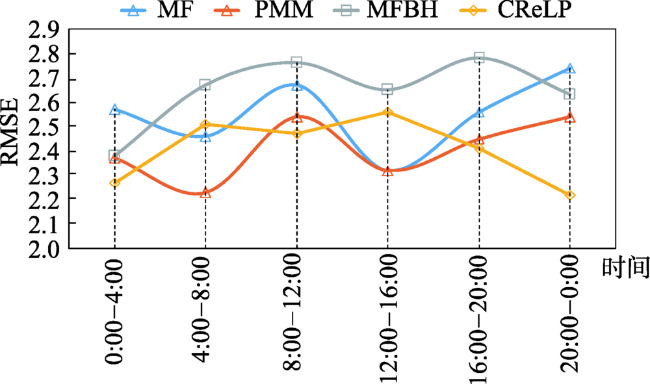
Fig. 9 RMSE with changing day time图9 RMSE随时间的变化 |
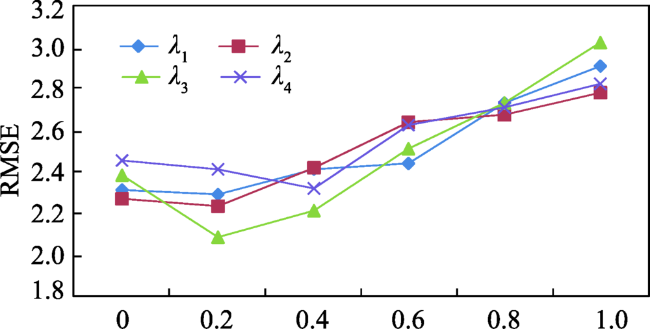
Fig. 10 RMSE with varying λ1~λ4图10 λ1-λ4对RMSE的影响 |
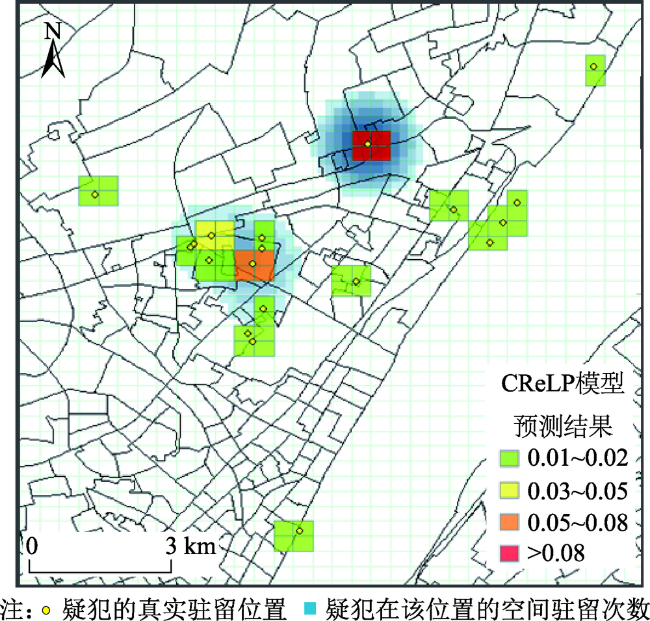
Fig. 11 Visiting spatial distribution for a suspect图11 单个疑犯的空间驻留分布 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
Office of the Privacy Commissioner of Canada [EO/BL]. Available online: / (accessed on 10th Mar, 2016).
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}