
Journal of Geo-information Science >
Progress in Information Acquisition of Disaster Events from Web Texts
Received date: 2018-02-25
Request revised date: 2018-03-31
Online published: 2018-08-24
Supported by
China Academy of Engineering Disaster Risk Reduction Knowledge Service System, No.CKCEST-2018-2-8
Chinese Academy of Sciences Strategic Pilot Science and Technology Project, No.XDA19040501
Specific Informatization Scientific Research Science Program of the Chinese Academy of Sciences, No.XXH13503-07.
Copyright
In this era of big data transfer and use, the extraction of disaster event information from huge quantities of network data is important to facilitate research on disaster prevention and reduction. In comparison with traditional disaster information, disaster information based on Web text is dynamic, heterogeneous, and massive, has space-time aspects, and accesses multiple sources. How to extract and visualize the spatio temporal and attribute information of disaster events from Web text, and track dynamic change patterns and trends of such events over space and time, is a growing area of research in geographic and disaster information systems. This study reviews the progress of relevant researchs including network data mining technology frameworks, disaster theme web page crawling, the extraction of disaster event information, the visualization and spatial distribution characteristics analysis of disaster events and the application system for disaster prevention and reduction. By examining the trend of disaster information acquisition for disaster prevention and reduction from the internet, this study analyzed and summarized the appropriate technologies of information extraction from Web text and discussed the development trends in the following three aspects: (1) Focusing on global disaster information acquisition and analysis. The fundamental trend is to realize the automatic acquisition, analysis, and visualization of global disaster event information to ensure disaster prevention and reduction. (2) To realize the United Nations' 2030 Agenda for Sustainable Development and China's "the Belt and Road" strategy, strengthening of the disaster event information analysis research and its application to typical regions is one of the research hotspots in the field of Web disaster information acquisition and application. (3) Establishing a new disaster prevention and reduction knowledge service system supported by big data mining and analysis technologies according to the application level of data, information, and knowledge will be one of the future research trends.
HAN Xuehua , WANG Juanle , BU Kun , WANG Yujie . Progress in Information Acquisition of Disaster Events from Web Texts[J]. Journal of Geo-information Science, 2018 , 20(8) : 1037 -1046 . DOI: 10.12082/dqxxkx.2018.180094
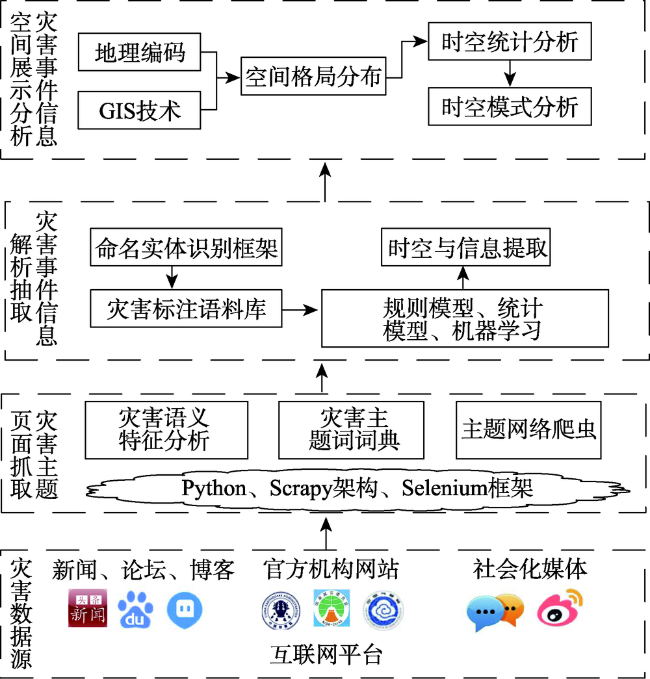
Fig. 1 Structure of information acquisition technology of disaster events from Web texts图1 基于Web文本的灾害事件信息获取技术架构 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
United Nations (UN). Sendai framework for disaster risk reduction 2015-2030[EO/OL]. , 2015-03-18.
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
人民网.大数据解析九寨沟地震72小时舆论场 [EB/OL]. .2018-03-16.
[ People's network. The Big Data Analysis of the Public Opinion 72 Hours after the Jiuzhaigou Earthquake[EB/OL]. .2018-03-16. ]
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
|
| [15] |
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
[
|
| [24] |
[
|
| [25] |
[
|
| [26] |
|
| [27] |
[
|
| [28] |
[
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
[
|
| [34] |
[
|
| [35] |
[
|
| [36] |
[
|
| [37] |
|
| [38] |
[
|
| [39] |
|
| [40] |
[
|
| [41] |
|
| [42] |
[
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
[
|
| [49] |
[
|
| [50] |
|
| [51] |
[
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
[
|
| [59] |
|
| [60] |
|
| [61] |
[
|
| [62] |
|
| [63] |
[
|
| [64] |
UNGA.Transforming our world: The 2030 agenda for sustainable development[R]. 2015
|
| [65] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}