
Journal of Geo-information Science >
Public Security Event Themed Web Text Structuring
Received date: 2018-12-01
Request revised date: 2018-12-24
Online published: 2019-01-20
Supported by
National Natural Science Foundation of China, No.41525004,41421001
Copyright
The information of public security event contained in text can be the data source of the evaluation and the relief if it can be structured into a relational database. Although previous research can extract the information of events into different attributes, the determination on the attribution of the attribute information to specific event remains unsolved. To solve the problem, this paper proposes a theoretical frame of public security event themed web text structuring, which is composed of three parts. First, an event semantic model is used to construct the seismic event semantic framework which defines abstract elements of event and their semantic relationships. Taking seismicity as an example, spatial element, time element, attribute element, source element are defined as basic elements. Spatial element includes earthquake latitude, longitude, depth and location. Attribute element is further subdivided into four sub-elements: Cause, result, behavior and influence element. Next, an annotation system is applied to typical event materials to label semantic elements, e.g. the place name where an earthquake took place, that is, instantiation of the abstract elements. The key to this step is labeling the relations between elements and specific event. Finally, the event text is structured into event type, event name, event time, event location and other attributes by using the text information extraction algorithm. The algorithm used the labeled materials in the last step as training data to optimize parameters, which can incorporate linked information. The extracted event text (e.g. words, phrases) finally is normalized to structured information for further analysis. An event information mining platform following the whole frame is developed, which includes the modules of webpage searching, text cleaning, event information extraction, visualization and analyzing. The platform processed the whole Chinese webpages of 2014 and found 85 506 seismicity reports. Taking Yunnanludian earthquake as an example, we display the structuring process and result of related web text, which can be the important reference for the relief of the disaster and the analysis of public concern. With the platform, we can demonstrate the seismic text structuring result and its social concern across China, which can be a new tool of event information mining and analyzing.
PEI Tao , GUO Sihui , YUAN Yecheng , ZHANG Xueying , YUAN Wen , GAO Ang , ZHAO Zhiyuan , XUE Cunjin . Public Security Event Themed Web Text Structuring[J]. Journal of Geo-information Science, 2019 , 21(1) : 2 -13 . DOI: 10.12082/dqxxkx.2019.180680
Tab. 1 Tasks of Chinese text mining and their corresponding methods表1 中文信息挖掘的任务及对应方法 |
| 主题分类及提取 | 时间与地名提取 | 属性信息抽取 | 空间关系提取 | |
|---|---|---|---|---|
| 基于规则的方法 | Rafea等[5] 、Petkos等[6] | 谭红叶等[7]、肖计划[8] | 丁效[9]、吴家皋等[10] | 马林兵等[11]、乐小虬等[12]、乐小虬等[13]、蒋文明[14] |
| 最大熵模型 | Li等[15]、李荣陆等[15]、 肖雪[17] | 王江伟[18]、王胜等[19]、钱晶等[20] | - | Kambhatla等[21] |
| 支持向量机 | Kumar等[22]、冯永等[23]、 王金华等[24] | 李丽双等[25]、李丽双等[26] 、唐晋韬[27] | 周凡坤[28] | Wang等[29]、Jiang等[30]、Bunescu等[31]、ZHOU等[32]、项乐安[33] |
| 马尔科夫模型 | 张春元[34]、梁吉光等[35] 、史庆伟等[36] | 马龙[37]、高国洋等[38]、邬伦等[39] | Scheffer等[40]、Ojokoh等[41]、梁吉光等[35]、Zhou等[42]、吴家皋等[10] | 董静等[43]、张春菊[44] |
| 贝叶斯分类 | Sankaranarayanan等[45] ,路金泉等[46]、武建军等[47]、 | 刘杰[48] | - | 顾雪峰 [49] |
| 神经网络 | 杨俊等[50]、吕淑宝等[51] 、郭东亮等[52] | 欧嘉致等[53] | 李帅等[54]、吕国英等[55]、叶开[56] | - |
| 最邻近方法KNN | Jiang等[57]、周庆平等[58]、戚后林等[59] | - | - | - |
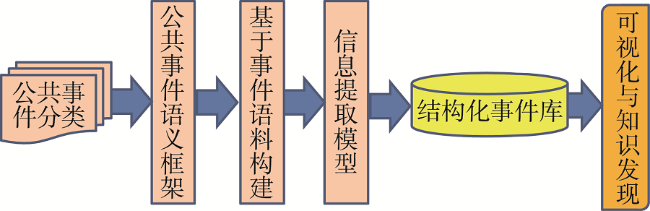
Fig. 1 Semantic frame based text iInformation structuring图1 基于事件语义框架的文本信息结构化思路 |
Tab. 2 Classification of public security events表2 公共安全事件分类[60] |
| 代码 | 名称 | 代码 | 名称 | 代码 | 名称 | 代码 | 名称 |
|---|---|---|---|---|---|---|---|
| 0100 | 自然灾害 | 0200 | 事故灾难 | 0300 | 公共卫生事件 | 0400 | 社会安全事件 |
| 0101 | 水旱灾害 | 0201 | 战争和暴力 | 0301 | 传染病疫情 | 0401 | 恐怖袭击事件 |
| 0102 | 气象灾害 | 0202 | 工矿商贸安全事故 | 0302 | 群体性不明原因疾病 | 0402 | 重大刑事案件 |
| 0103 | 地震灾害 | 0203 | 交通运输安全事故 | 0303 | 食品安全和职业危害 | 0403 | 经济安全事件 |
| 0104 | 地质灾害 | 0204 | 城市生命线事故 | 0304 | 动物疫情 | 0404 | 涉外突发事件 |
| 0105 | 海洋灾害 | 0205 | 通讯安全事故 | 0399 | 其他 | 0405 | 规模较大的群体性事件 |
| 0106 | 生物灾害 | 0206 | 环境污染和生态破坏 | 0406 | 民族宗教 | ||
| 0107 | 森林草原火灾 | 0207 | 严重火灾 | 0407 | 反政府和反社会主义骚乱暴动 | ||
| 0108 | 宇宙灾害 | 0208 | 中毒事件 | 0499 | 其他 | ||
| 0199 | 其他 | 0209 | 急性化学事故 | ||||
| 0210 | 放射事故 | ||||||
| 0211 | 医药事故 | ||||||
| 0212 | 探险遇难 | ||||||
| 0213 | 旅游事故 | ||||||
| 0299 | 其他 | ||||||
Tab. 3 Semantic framework of seismic event表3 公共安全事件/地震事件的语义框架 |
| 要素类型名称 | 地震事件要素 | 数据类型 | |
|---|---|---|---|
| 类型 | 事件类型 | 字符型 | |
| 对象 | 地震名称 | 字符型 | |
| 编号 | 记录编号 | 整数型 | |
| 时间 | 发震时间 | 年-月-日-时-分-秒(时间型) | |
| 空间 | 发震地点 | 字符型 | |
| 震中纬度 | 实数型 | ||
| 震中经度 | 实数型 | ||
| 地震深度 | 实数型 | ||
| 属性 | 原因 | 发震原因 | 字符型 |
| 结果 | 地震震级 | 实数型 | |
| 地震烈度 | 整型 | ||
| 死亡人数 | 整型 | ||
| 受伤人数 | 整型 | ||
| 失踪人数 | 整型 | ||
| 受灾人数 | 整型 | ||
| 安置人数 | 整型 | ||
| 建筑损坏 | 整型 | ||
| 经济损失 | 实数型 | ||
| 受灾范围 | 实数型 | ||
| 记录时间 | 年-月-日-时-分-秒(时间型) | ||
| 行为 | 震感程度 | 字符型 | |
| 天气状况 | 字符型 | ||
| 救援方式 | 捐款/实地/安置/重建/ | ||
| 影响 | 救援人数 | 整型 | |
| 救援资金 | 实数型 | ||
| 来源 | 发布时间 | 发布时间 | 年-月-日-时-分-秒(时间型) |
| 网址 | 信息网址 | 字符型 | |
| 可靠性 | 信息可靠性级别 | 国家媒体/地方媒体/企业媒体 | |
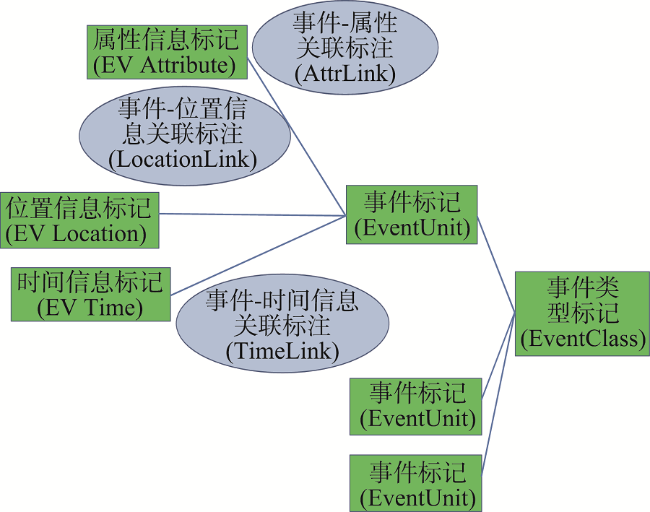
Fig. 2 Framework of information labeling of event attributes图2 事件要素信息标注基本框架 |
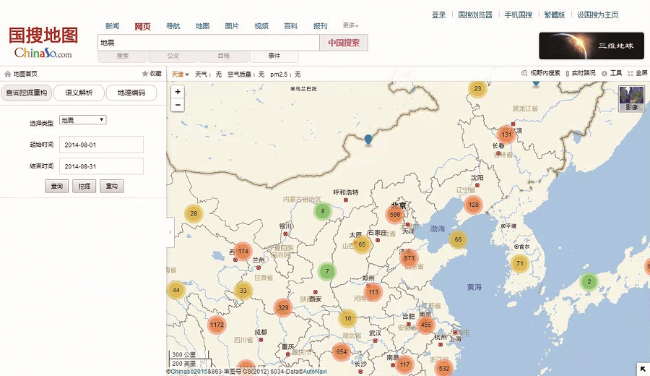
Fig. 3 Seismic event distribution based on extraction result in August 2014图3 2014年8月地震事件文本解析结果 |
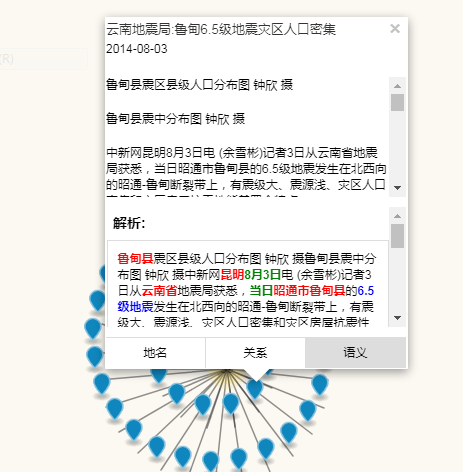
Fig. 4 Extraction result of seismic event text图4 地震事件信息解析结果示意 |
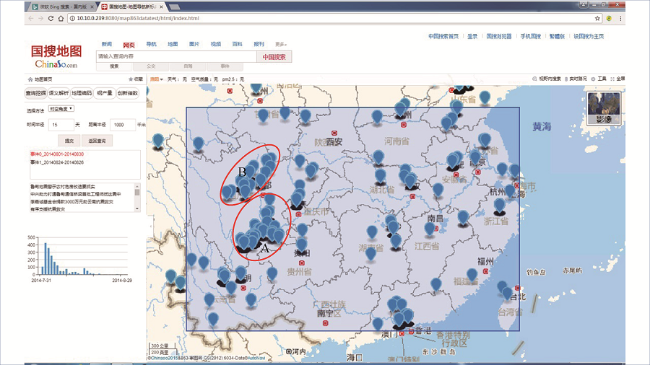
Fig. 5 Media concern on Yunnanludian earthquake across China图5 “云南鲁甸6.5级地震”全国关注度分布 |
Tab.4 Structural records of ludian earthquake from web texts表4 鲁甸地震网络文本结构化数据示例 |
| 属性列 | 记录1 | 记录2 | 记录3 | …… |
|---|---|---|---|---|
| 事件类型 | 地震 | 地震 | 地震 | …… |
| 地震名称 | 邵通鲁甸地震 | 邵通鲁甸地震 | 邵通鲁甸地震 | |
| 记录编号 | 36 786 | 64 873 | 4783 | |
| 发震时间 | 2014-08-03-00-00-00 | 2014-08-03-16-30-00 | 2014-08-03-00-00-00 | |
| 发震地点 | 云南省昭通市鲁甸县 | 云南省昭通市鲁甸县 | 云南省昭通市鲁甸县 | |
| 震中经度 | - | 103.3 | 103.725 | |
| 震中纬度 | - | 27.1 | 27.34 | |
| 震源深度 | - | 12 000 | 12 000 | |
| 发震原因 | - | - | - | |
| 地震震级 | 6.5 | 6.5 | 6.5 | |
| 地震烈度 | - | - | - | |
| 死亡人数 | 367 | 589 | 617 | |
| 受伤人数 | 1801 | 2401 | 3143 | |
| 失踪人数 | 5 | 9 | 112 | |
| 受灾人数 | - | 1 088 400 | 1 088 400 | |
| 安置人数 | - | 229 700 | 229 700 | |
| 建筑损坏 | - | 80 900 | - | |
| 经济损失 | - | - | - | |
| 受灾范围 | - | - | - | |
| 记录时间 | 2014-08-03 | 2014-08-06-10-30-00 | 2014-08-21-00-00-00 | |
| 震感程度 | - | - | - | |
| 天气状况 | - | - | - | |
| 救援方式 | 捐款 | 安置 | 安置 | |
| 救援人数 | - | - | - | |
| 救援资金 | - | - | - | |
| 发布时间 | 2014-08-05-09-57-00 | 2014-08-06-12-58-08 | 2014-08-21-22-47-42 | |
| 信息网址 | http://dl.sina.com.cn/news/wenti/2014-08-05/095732477.html | http://news.iqilu.com/china/gedi/2014/0806/2093139.shtml | http://news.china.com.cn/rollnews/education/live/2014-08/21/content_28320532.htm | |
| 可靠性 | 企业媒体 | 地方媒体 | 国家媒体 |
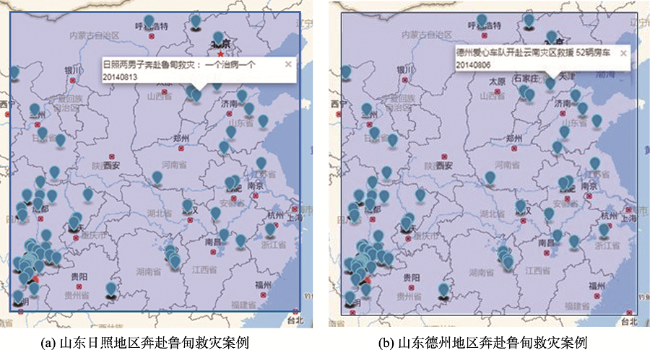
Fig. 6 Information extraction on reports of Yunnanludian earthquake rescue图6 “云南鲁甸6.5级地震”救援情况报道举例 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
|
| [6] |
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
[
|
| [15] |
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
[
|
| [21] |
|
| [22] |
|
| [23] |
[
|
| [24] |
[
|
| [25] |
[
|
| [26] |
[
|
| [27] |
[
|
| [28] |
[
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
[
|
| [34] |
[
|
| [35] |
[
|
| [36] |
[
|
| [37] |
[
|
| [38] |
[
|
| [39] |
[
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
[
|
| [44] |
[
|
| [45] |
|
| [46] |
[
|
| [47] |
[
|
| [48] |
[
|
| [49] |
[
|
| [50] |
[
|
| [51] |
[
|
| [52] |
[
|
| [53] |
[
|
| [54] |
[
|
| [55] |
[
|
| [56] |
[
|
| [57] |
|
| [58] |
[
|
| [59] |
[
|
| [60] |
[
|
| [61] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}