
Journal of Geo-information Science >
Photon-Counting LiDAR Point Cloud Data Filtering based on the Random Forest Algorithm
Received date: 2019-01-08
Request revised date: 2019-03-25
Online published: 2019-06-15
Supported by
National Natural Science Foundation of China, No.41871278
Forest Product Processing and Inversion Project for the Terrestrial Ecosystem Carbon Monitoring Satellite, No.2016K-10
Copyright
The new generation of spaceborne laser satellite ICESat-2 (the Ice, Cloud, and land Elevation Satellite-2) of NASA (National Aeronautics and Space Administration) has adopted a newly designed micropulse photon counting system, which is the very first time that this technology gets applied in the space environment. Thanks to the high sensitivity of single photon detection technology, it can be seen from the currently released data product (both from the airborne simulators and the simulation data) that there is huge noise in the atmosphere and even below the ground. Therefore, preliminary research on these relevant experimental data to investigate the methods for separating signal photons from noise photons are important for the future applications. MATLAS data, which simulate the expected performance of the ICESat-2 ATLAS (Advanced Topographic Laser Altimeter System) instrument, was chosen to test our machine learning-based approach from two test sites in Oregon and Virginia in the United States. We first derived 12 features, such as the kNN (k-Nearest Neighbour) distance, based on the characteristics of photon point clouds data. Then we applied feature selection techniques by ranking variable importance using Random Forest. Three most representative features were chosen according to the variable importance ranking and we built a Random Forest classifier trained by the sample points we had selected. The established models were further applied to the whole study area. The final classification results indicate that the classifier we constructed had good performance to distinguish signal photons from noise photons. In terms of the mean values of the statistical indicators in the test sites, the overall classification accuracy was 96.79%, and the Kappa coefficient was 0.94. The producer and user accuracies were 97.1% and 96.8%, respectively. Additionally, the results show that our method not only worked well on data of relatively lower noise rate on flat terrain surfaces but also achieved good results for those with higher noise rate on complex terrain surfaces. To conclude, our method showes good potential to be applied to larger areas, for especially the classification of the photon counting LiDAR data in the future.
Key words: random forest; machine learning; photon-counting; LiDAR; point clouds classification
CHEN Bowei , PANG Yong , LI Zengyuan , LU Hao , LIANG Xiaojun . Photon-Counting LiDAR Point Cloud Data Filtering based on the Random Forest Algorithm[J]. Journal of Geo-information Science, 2019 , 21(6) : 898 -906 . DOI: 10.12082/dqxxkx.2019.190013
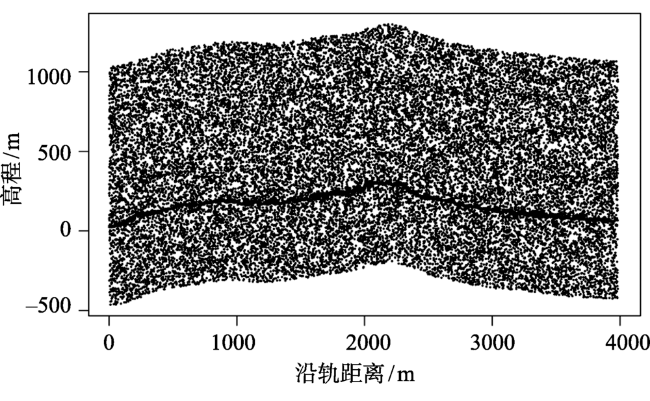
Fig. 1 MATLAS data with high noise rate on complex terrain surfaces (Oregon site, US)图1 强噪声复杂地形的MATLAS数据(美国俄勒冈州) |
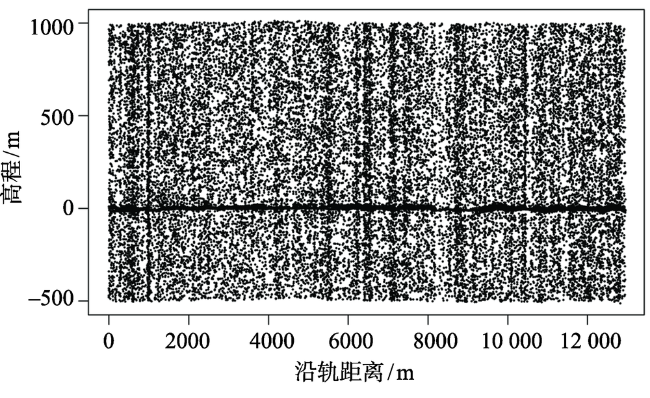
Fig. 2 MATLAS data with low noise rate on flat terrain surfaces (Virginia site, US)图2 弱噪声平坦地形区的MATLAS数据(美国弗吉尼亚州) |
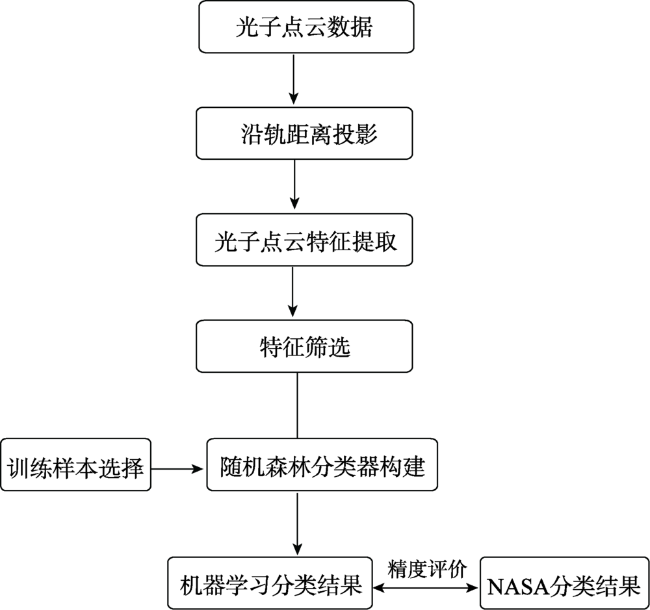
Fig. 3 Flowchart of the photon-counting LiDAR point clouds filtering algorithm based on random forest图3 基于随机森林的光子计数激光雷达点云滤波的总体流程 |
Tab. 1 Features of the photon point clouds表1 激光雷达光子点云特征 |
| 编号 | 特征名称 | 特征定义 | 编号 | 特征名称 | 特征定义 |
|---|---|---|---|---|---|
| 1 | h | 光子点云高度 | 7 | dist.p75 | 10 m窗口范围内每个点与窗口内全部点75%高度分位数的差 |
| 2 | dist.mean | 10 m窗口范围内每个点与窗口内全部点高度均值的差 | 8 | h.kurtosis | 10 m窗口范围内每个点与窗口内全部点高度峰度的差 |
| 3 | dist.median | 10 m窗口范围内每个点与窗口内全部点高度中值的差 | 9 | h.skewness | 10 m窗口范围内每个点与窗口内全部点高度偏度的差 |
| 4 | dist.p10 | 10 m窗口范围内每个点与窗口内全部点10%高度分位数的差 | 10 | dist | 光子点云的沿轨距离 |
| 5 | dist.p25 | 10 m窗口范围内每个点与窗口内全部点25%高度分位数的差 | 11 | kNNdist3 | 光子点的K临近距离(K=3) |
| 6 | dist.p50 | 10 m窗口范围内每个点与窗口内全部点50%高度分位数的差 | 12 | dist.kmeans | 每个点分别与2类时的各自的K-means聚类中心的距离 |
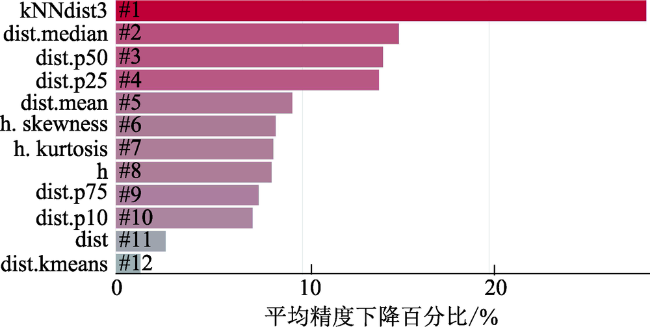
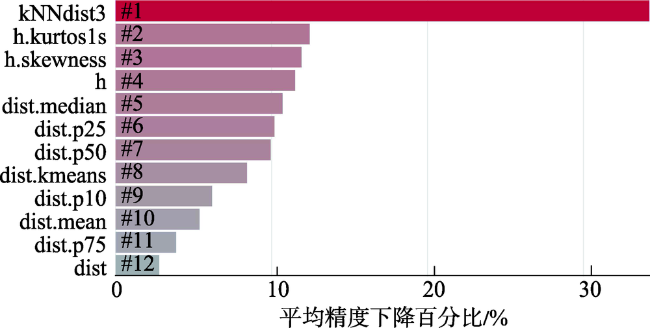
Fig. 4 Variable importance ranking based on random forest (high noise rate on complex terrain surfaces)图4 基于随机森林的重要性排序(强噪声复杂地形区) |
Fig. 5 Variable importance ranking based on random forest (low noise rate on flat terrain surfaces)图5 基于随机森林的重要性排序(弱噪声平坦地形区) |
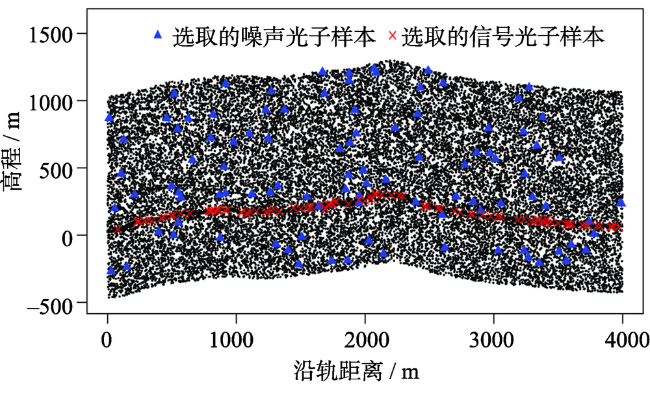
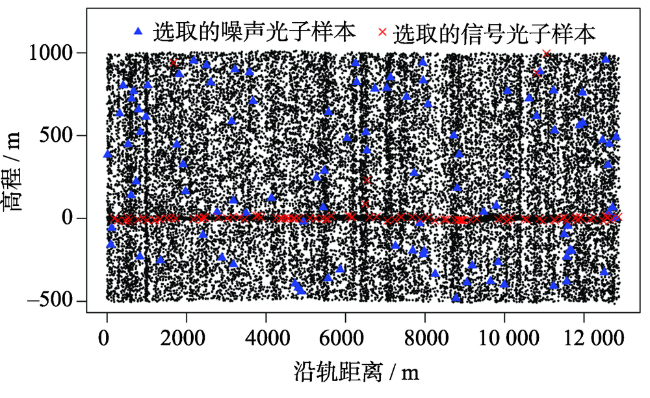
Fig. 6 Distribution of the training samples with high noise rate on the complex terrain surfaces图6 强噪声复杂地形区训练样本分布 |
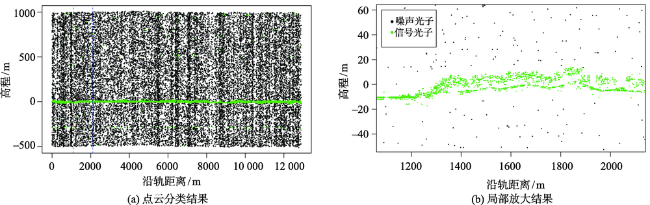
Fig. 7 Random forest classification result of the complex terrain surfaces with high noise rate (Oregon site, US)图7 强噪声复杂地形区基于随机森林的点云分类结果(美国俄勒冈州) |
Fig. 8 Distribution of the training samples with low noise rate on the flat terrain surfaces图8 弱噪声平坦地形区训练样本分布 |
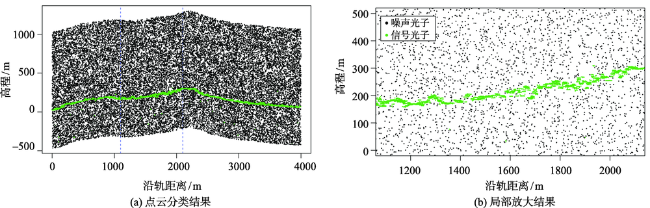
Fig. 9 Random forest classification result of the flat terrain surfaces with low noise rate (Virginia site, US)图9 弱噪声平坦地形区基于随机森林的点云分类结果(美国弗吉尼亚州) |
Tab. 2 Accuracy assessment of signal photons classification表2 信号光子点分类结果精度评价 |
| 研究区 | 总光子数/个 | 噪声光子数/个 | 信号光子数/个 | 信噪比 | 类别 | PA/% | UA/% | OA/% | Kappa系数 |
|---|---|---|---|---|---|---|---|---|---|
| 俄勒冈州 | 42 353 | 27 203 | 15 150 | 0.56 | 噪声 | 98.4 | 99.8 | 98.43 | 0.97 |
| 信号 | 99.6 | 97.1 | |||||||
| 弗吉尼亚 | 54 215 | 25 755 | 28 460 | 1.11 | 噪声 | 96.1 | 93.9 | 95.14 | 0.90 |
| 信号 | 94.3 | 96.4 | |||||||
| 均值 | 97.1 | 96.8 | 96.79 | 0.94 | |||||
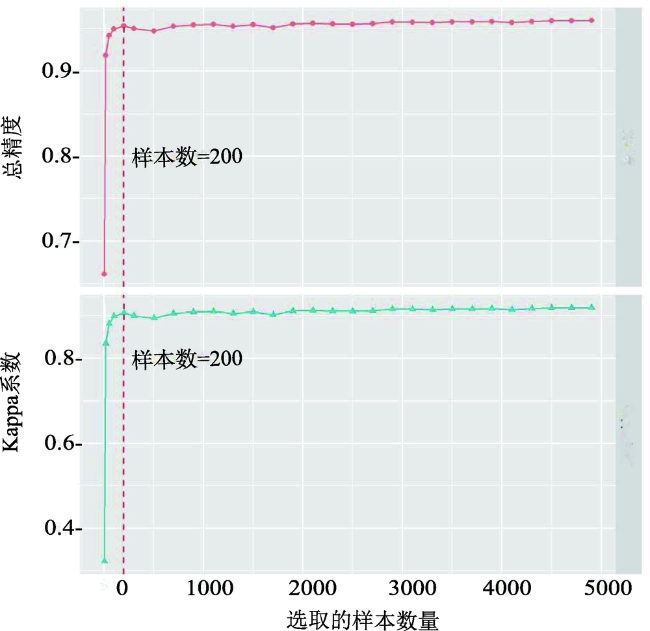
Fig. 10 Sensitivity of the classification result of the Virginia site with regard to different numbers of samples图10 弗吉尼亚研究区分类精度随选择样本数量的变化情况 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
|
| [3] |
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
[
|
| [19] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}