
Journal of Geo-information Science >
Prediction Method of Tungsten-molybdenum Prospecting Target Area based on Deep Learning
Received date: 2019-01-18
Request revised date: 2019-04-22
Online published: 2019-06-15
Supported by
Development and promotion of intelligent geological survey system, No.DD20160355
Copyright
With the exploration of minerals from shallow mines to deep concealed mines, from easy-to-identify mines to difficult-to-identify mines, the difficulty of prospecting is increasing, and geological experts are paying more and more attention to the application of new theories, new methods, and new technologies. As a frontier field and technology of artificial intelligence, deep learning has a unique advantage in realizing the intelligent forecasting and evaluation of mineral resources. The method uses normalized geochemical data as the training data to extract outliers by a neural network called Autoencoder and identify the favorable mineralization areas, and then realizes the qualitative prediction of mineral resources prospecting prospect. The research results show that after classifying the original data of 957 single elements geochemical anomalies and labeling of the model, the whole process automatically completes the learning and prediction in the "black box" of the computer, compared with the traditional prediction research method, this method of research is highly automated and objective. In addition, this paper uses the known mine sites to construct the training dataset, and uses the random forest method to predict the mineral resources prospecting target area in the prediction area, which provides a scientific basis for further narrowing the scope of the prospecting target area.
CAI Huihui , ZHU Wei , LI Zixuan , LIU Yuanyuan , LI Longbin , LIU Chang . Prediction Method of Tungsten-molybdenum Prospecting Target Area based on Deep Learning[J]. Journal of Geo-information Science, 2019 , 21(6) : 928 -936 . DOI: 10.12082/dqxxkx.2019.190032
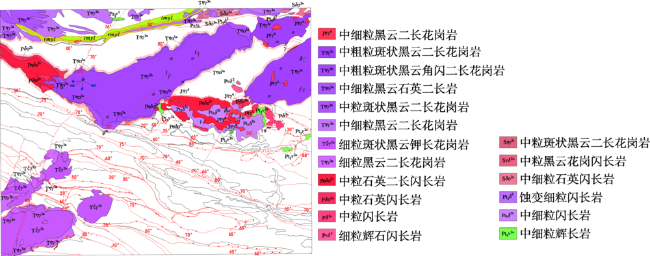
Fig. 1 Rock mass and structural lines in the study area图1 研究区岩体与构造 |
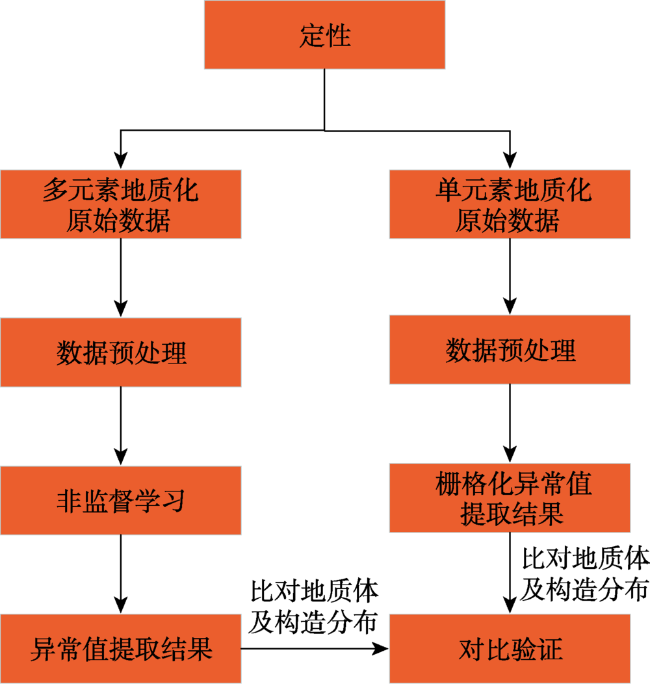
Fig. 2 Flowchart of qualitative prediction of mineral resources图2 定性矿产资源预测流程 |
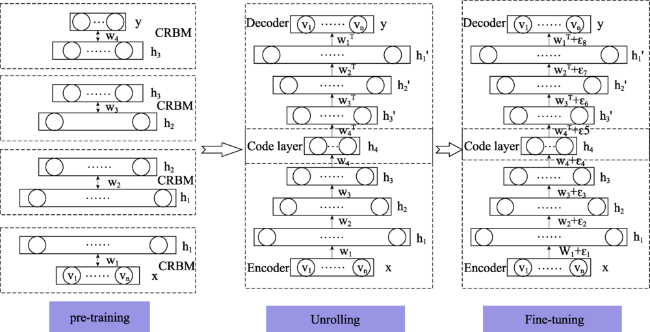
Fig. 3 Deep learning prediction model diagram of autoencoding networks图3 自编码网络深度学习预测模型 |
Fig. 4 Deep learning process diagram of autoencoding networks图4 自编码神经网络流程 |
Fig. 5 Coordinate ranges of the sampled chemical points in the study area图5 研究区化探采样点坐标范围 |
Tab. 1 CRBM size of each layer of the deep autoencoder networks表1 深度自编码网络每一层CRBM尺寸 |
| 网络层编号 | CRBM 尺寸 |
|---|---|
| Layer1 | 11×100 |
| Layer2 | 100×50 |
| Layer3 | 50×20 |
| Layer4 | 20×5 |
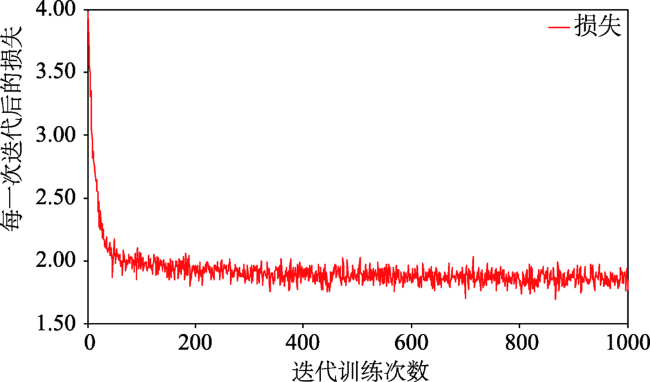
Fig. 6 Iterative losses of the autoencoder neural networks图6 深度自编码神经网络迭代损失 |
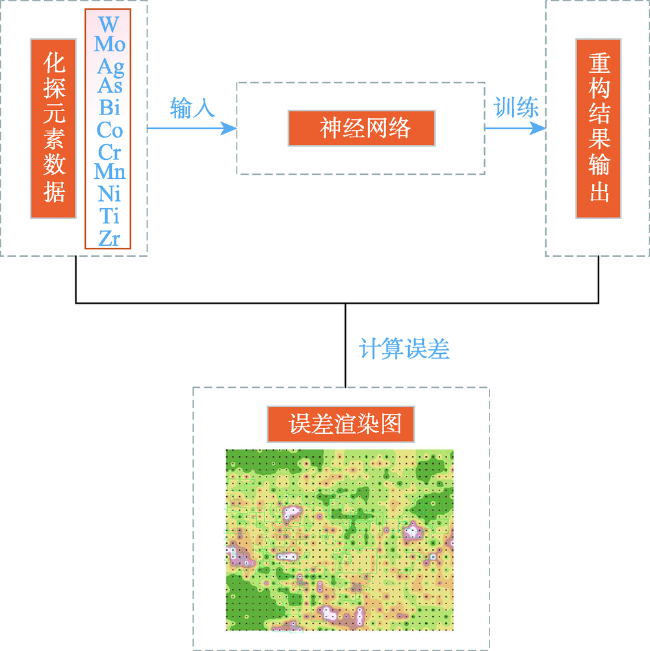
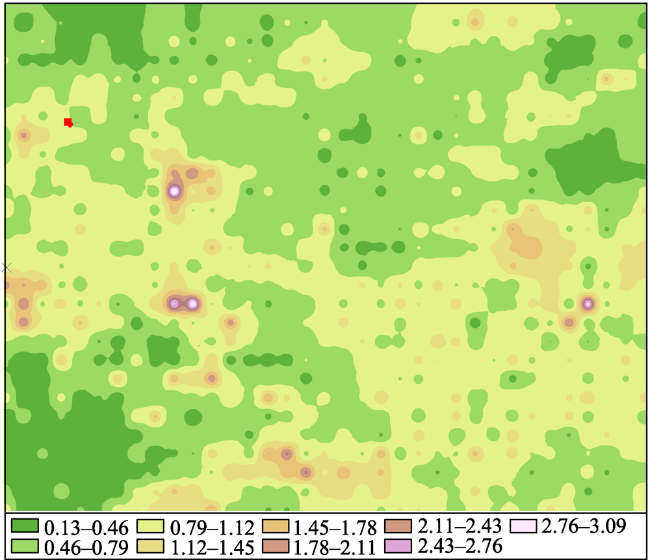
Fig. 7 Self-coding error map of the geochematic sampling points图7 化探采样点自编码深度误差 |
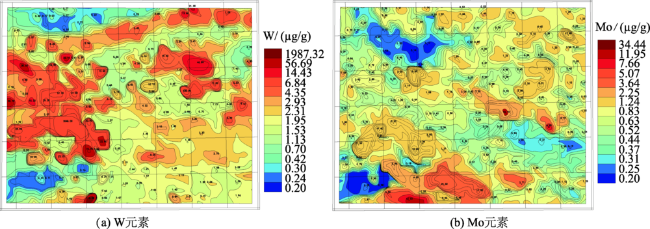
Fig. 8 Anomaly contour map of W and Mo图8 W和Mo的单元素异常等值线 |
Fig. 9 Geodetic points distribution map in the predicting area图9 预测区域化探点位数据分布 |
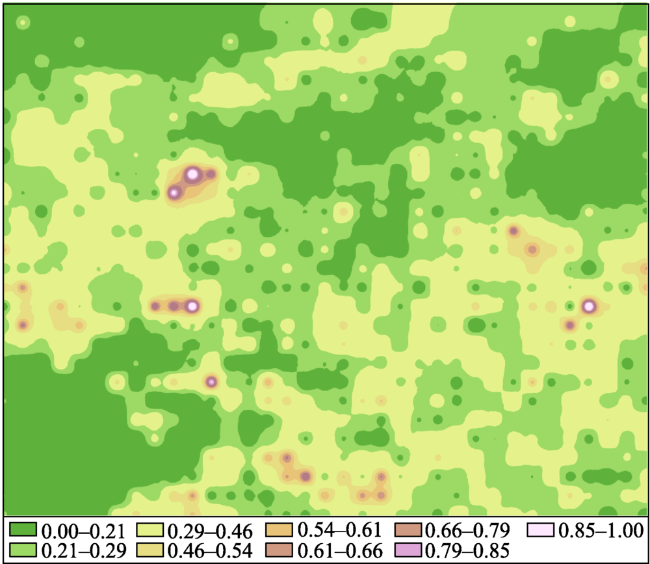
Fig. 10 Error map of the geochemical points in the predicting area图10 预测区域化探采样点误差 |
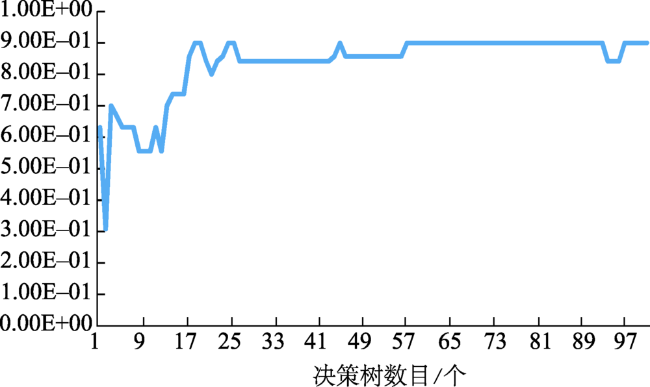
Fig. 11 Relationship between the number of random forest decision trees and their F1 scores图11 随机森林决策树数目与其F1得分间的关系 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
[
|
| [13] |
|
| [14] |
[
|
| [15] |
|
| [16] |
[
|
| [17] |
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}