
Journal of Geo-information Science >
Assessing PM2.5 Exposure Risk by Coupling Land Use Regression Model and Population Weighted Model
Received date: 2018-12-28
Request revised date: 2019-03-24
Online published: 2019-07-25
Supported by
National Natural Science Foundation of China, No.41671430
Copyright
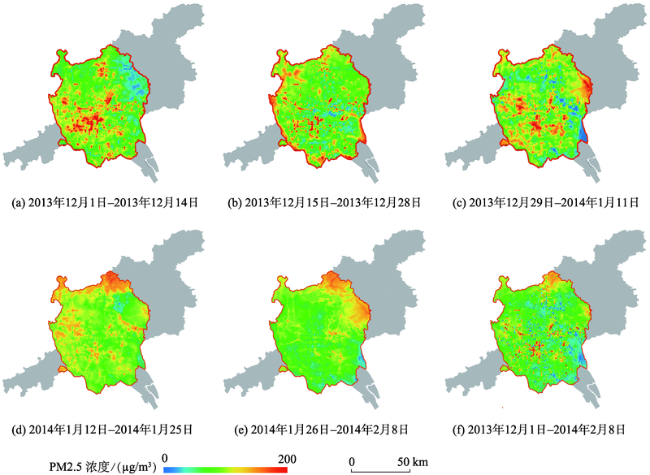
With the rapid urbanization in the recent years, the deterioration of urban eco-environment and consequent impacts on human health have raised increasing concern. Air pollution, especially PM2.5, has become one of the most serious problems which threaten public health. As the key of air pollution health assessment, exposure risk assessment needs accurate data of air pollution concentration. However, it is impossible to get intra-urban PM2.5 concentration in random places based on existing monitoring data. Additionally, most PM2.5 risk exposure assessment studies take air pollution concentration as the evaluation index, without considering the spatial distribution of population. Coupling population-weighted assessment method is one of the feasible solutions to solve this problem. To this end, PM2.5 monitoring data, land use data, road data, and meteorological data were applied to developed the PM2.5 Land Use Regression (LUR) model in the Guangzhou-Foshan metropolitan area from December 1, 2013 to February 8, 2014. Then, the population density data were coupled to assess the population-weighted exposure risk of PM2.5. The results reveal that: (1) LUR predicted the spatial distribution of PM2.5 with good performance (R2 of 0.786-0.913). (2) From December 1, 2013 to February 8, 2014, the mean simulated PM2.5 concentration of the Guangzhou-Foshan metropolitan area changed fluctuatingly and the highest concentration was 97.91 μg/m3 (from December 29 to January 11) while the lowest was 53.40 μg/m3 (from January 26 to February 8). PM2.5 exposure in 99.8% of the study area was above the WHO require exposure standard. (3) The spatial distribution of PM2.5 concentration varied from place to place. High-concentration areas were located in Tianhe District, Yuexiu District, north of Panyu District, north of Huadu District, Chancheng District, middle of Nanhai District and middle of Sanshui District, while low-concentration areas included mainly Baiyun District, south-east of Panyu District and south of Shunde District. There were two high-level centers of population-weighted exposure risk located at the Guangzhou and Foshan downtowns. (4) After coupling the population weighted model, the high risk areas of PM2.5 in the Guangzhou-Foshan metropolitan area changed. The old high concentration areas focused on Nanhai District, Tianhe District, Yuexiu District, and Chancheng District, while coupling the population density data resulted in a more concentrated PM2.5 exposure centers, since the high risk areas tended to centralize around the downtowns of Guangzhou and Foshan.
ZOU Yuxuan , WU Zhifeng , CAO Zheng . Assessing PM2.5 Exposure Risk by Coupling Land Use Regression Model and Population Weighted Model[J]. Journal of Geo-information Science, 2019 , 21(7) : 1018 -1028 . DOI: 10.12082/dqxxkx.2019.180695
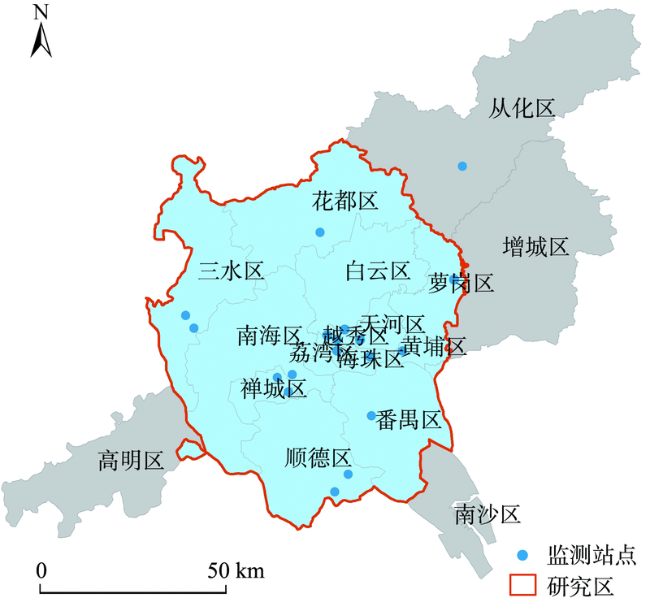
Fig. 1 Distribution of state controlling monitoring sites in Guangzhou and Foshan图1 广东省广佛地区国控空气质量监测站点分布 |
Tab.1 Correlations between the geographical variables and PM2.5 concentration in monitoring sites表1 监测站点地理要素特征变量与PM2.5浓度的相关性 |
| 自变量 | Pearson相关系数 | 自变量 | Pearson相关系数 |
|---|---|---|---|
| 植被_50 m(x1) | -0.198 | 主干道长度_50 m(x33) | - |
| 植被_100 m(x2) | -0.301 | 主干道长度_100 m(x34) | - |
| 植被_200 m(x3) | -0.323 | 主干道长度_200 m(x35) | 0.183 |
| 植被_300 m(x4) | -0.344 | 主干道长度_300 m(x36) | 0.175 |
| 植被_500 m(x5) | -0.292 | 主干道长度_500 m(x37) | 0.221 |
| 植被_1000 m(x6) | -0.379 | 主干道长度_1000 m(x38) | 0.247 |
| 植被_1200 m(x7) | -0.392 | 主干道长度_1200 m(x39) | 0.297 |
| 植被_1500 m(x8) | -0.416 | 主干道长度_1500 m(x40) | 0.292 |
| 水体_50 m(x9) | - | 一级公路长度_50 m(x41) | -0.047 |
| 水体_100 m(x10) | - | 一级公路长度_100 m(x42) | -0.047 |
| 水体_200 m(x11) | -0.123 | 一级公路长度_200 m(x43) | -0.032 |
| 水体_300 m(x12) | -0.112 | 一级公路长度_300 m(x44) | -0.023 |
| 水体_500 m(x13) | -0.078 | 一级公路长度_500 m(x45) | -0.054 |
| 水体_1000 m(x14) | -0.181 | 一级公路长度_1000 m(x46) | -0.033 |
| 水体_1200 m(x15) | -0.388 | 一级公路长度_1200 m(x47) | -0.036 |
| 水体_1500 m(x16) | -0.482 | 一级公路长度_1500 m(x48) | -0.002 |
| 不透水面_50 m(x17) | 0.329 | 二级公路长度_50 m(x49) | 0.164 |
| 不透水面_100 m(x18) | 0.356 | 二级公路长度_100 m(x50) | 0.164 |
| 不透水面_200 m(x19) | 0.337 | 二级公路长度_200 m(x51) | 0.644** |
| 不透水面_300 m(x20) | 0.366 | 二级公路长度_300 m(x52) | 0.333 |
| 不透水面_500 m(x21) | 0.410 | 二级公路长度_500 m(x53) | 0.107 |
| 不透水面_1000 m(x22) | 0.492 | 二级公路长度_1000 m(x54) | -0.053 |
| 不透水面_1200 m(x23) | 0.510 | 二级公路长度_1200 m(x55) | -0.108 |
| 不透水面_1500 m(x24) | 0.597* | 二级公路长度_1500 m(x56) | 0.038 |
| 道路总长度_50 m(x25) | 0.133 | 三级公路长度_50 m(x57) | -0.132 |
| 道路总长度_100 m(x26) | -0.127 | 三级公路长度_100 m(x58) | -0.332 |
| 道路总长度_200 m(x27) | 0.076 | 三级公路长度_200 m(x59) | -0.444 |
| 道路总长度_300 m(x28) | 0.076 | 三级公路长度_300 m(x60) | -0.300 |
| 道路总长度_500 m(x29) | 0.278 | 三级公路长度_500 m(x61) | -0.150 |
| 道路总长度_1000 m(x30) | 0.319 | 三级公路长度_1000 m(x62) | -0.092 |
| 道路总长度_1200 m(x31) | 0.347 | 三级公路长度_1200 m(x63) | -0.046 |
| 道路总长度_1500 m(x32) | 0.418 | 三级公路长度_1500 m(x64) | -0.127 |
注:**相关性在0.01层上显著;*相关性在0.05层上显著;样本量n=18。监测站点缓冲区内x9, x10, x33, x34变量多为零值,因此无相关性分析结果。 |
Tab. 2 Buffer radius of geographical variables that associated most strongly with PM2.5 in each subclass表2 地理要素特征变量各子类中与PM2.5相关性最强的缓冲区范围 |
| 子类 | 植被 | 水体 | 不透水面 | 道路总长 | 主干道 | 一级公路 | 二级公路 | 三级公路 |
|---|---|---|---|---|---|---|---|---|
| 缓冲区范围/m | 1500 | 1500 | 1500 | 1500 | 1200 | 500 | 200 | 200 |
| R | -0.416 | -0.482 | 0.597 | 0.418 | 0.297 | -0.054 | 0.644 | -0.444 |
Tab. 3 Regression R2 at different Kriging interpolation grain sizes表3 克里金插值像元大小对应回归模型精度 |
| 像元大小/m | 30 | 50 | 100 | 200 | 300 | 500 | 1000 |
|---|---|---|---|---|---|---|---|
| R2 | 0.924 | 0.924 | 0.924 | 0.915 | 0.920 | 0.920 | 0.926 |
Tab. 4 Correlations between the geographical variables and PM2.5 concentration based on partial correlation analysis in Guangzhou-Foshan metropolitan area from December 1, 2013 to February 8, 2014表4 2013年12月1日-2014年2月8日广佛都市区地理要素与PM2.5浓度偏相关分析 |
| 变量 | 植被 (1500 m) | 水体 (1500 m) | 不透水面(1500 m) | 道路总长(1500 m) | 主干道 (1200 m) | 一级公路(500 m) | 二级公路(200 m) | 三级公路 (200 m) |
|---|---|---|---|---|---|---|---|---|
| R | -0.465 | -0.297 | 0.648 | 0.542 | 0.345 | 0.206 | 0.282 | -0.395 |
注:()内为缓冲区半径长度,土地利用变量表示各土地利用类型在缓冲区内面积占比,道路交通变量表示各道路类型在缓冲区内道路长度。 |
Tab. 5 Multivariable linear regression equations and its R2 from December 1, 2013 to February 8, 2014表5 2013年12月1日-2014年2月8日多元线性回归方程及模型精度 |
| 时段 | 回归方程 | R2 |
|---|---|---|
| 时段一 | Y=3.876x8+19.372x16+29.967x24+42.788x26-34.143x37-50.086x44+93.066x53-38.663x59 +27.562x65-11.11x66-42.257x67+89.081 | 0.825 |
| 时段二 | Y=15.052x8+48.009x16+9.022x24+22.677x26-17.731x37-26.441x44+104.565x53-31.973x59 +5.38x65-5.463x66-21.818x67+66.51 | 0.786 |
| 时段三 | Y=48.153x8+28.691x16+37.224x24+63.619x26-27.226x37+37.04x44+22.141x53-70.281x59 -38.965x65-38.5x66-24.872x67+87.678 | 0.892 |
| 时段四 | Y=43.816x8+25.451x16+25.249x24+30.497x26-6.236x37+15.35x44+40.895x53-47.251x59 -7.594x65-47.62x66-52.629x67+82.223 | 0.813 |
| 时段五 | Y=20.882x8+3.161x16+17.805x24-33.023x26+7.659x37+45.987x44-33.884x53-42.567x59-15.06x65+0.173x66-74.48x67+85.962 | 0.913 |
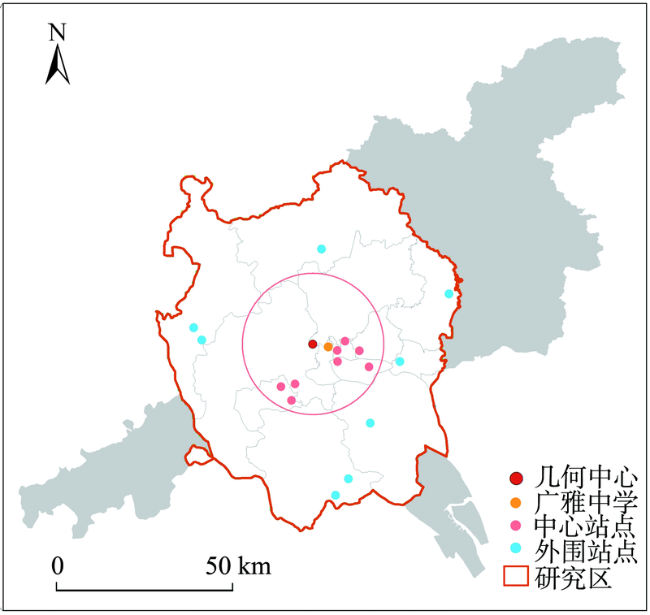
Fig. 2 Types of the monitoring sites within the Guangzhou-Foshan metropolitan area图2 广佛都市区内监测站点类别 |
Tab. 6 Accuracy of the PM2.5 concentration modeling results in checkpoint (Guangdong Guangya high school) from December 1, 2013 to February 8, 2014表6 2013年12月1日-2014年2月8日检验点广雅中学PM2.5浓度拟合结果 |
| 时段一 | 时段二 | 时段三 | 时段四 | 时段五 | 平均 | |
|---|---|---|---|---|---|---|
| PM2.5监测值 | 117.37 | 79.19 | 109.49 | 84.74 | 66.71 | 91.50 |
| PM2.5模拟值 | 112.68 | 77.54 | 111.67 | 90.37 | 66.66 | 91.78 |
| 误差率/% | 4.00 | 2.10 | 2.00 | 6.60 | 0.70 | 3.10 |
Tab. 7 PM2.5 concentration modeling error rates at core and periphery monitor sites in Guangzhou-Foshan metropolitan area from December 1, 2013 to February 8, 2014 (%)表7 2013年12月1日-2014年2月8日广佛都市区中心及外围监测站点PM2.5浓度拟合误差率 |
| 时段一 | 时段二 | 时段三 | 时段四 | 时段五 | 平均 | ||
|---|---|---|---|---|---|---|---|
| 中心监测点 | 11.2 | 9.0 | 9.6 | 11.9 | 6.6 | 9.7 | |
| 外围监测点 | 13.4 | 18.2 | 7.8 | 8.4 | 13.0 | 12.2 | |
Table 8 Mean modeled PM2.5 concentration of the Guangzhou-Foshan metropolitan area and percentage of areas where PM2.5 concentration exceeded the WHO standard, from December 1, 2013 to February 8, 2014表8 2013年12月1日-2014年2月8日广佛都市区PM2.5浓度模拟平均值及超WHO标准面积占比 |
| 时段一 | 时段二 | 时段三 | 时段四 | 时段五 | 平均 | |
|---|---|---|---|---|---|---|
| PM2.5平均值 | 95.13 | 71.19 | 97.91 | 80.69 | 53.40 | 79.67 |
| 面积比/% | 100 | 100 | 100 | 100 | 99.10 | 99.80 |
Fig. 3 Simulation of PM2.5 concentration in the Guangzhou-Foshan metropolitan area from December 1, 2013 to February 8, 2014图3 2013年12月1日-2014年2月8日广佛都市区PM2.5浓度模拟 |
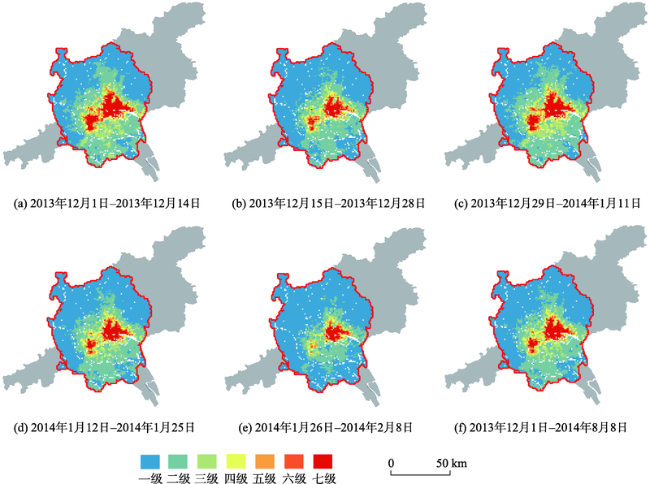
Fig. 4 PM2.5 Exposure risk in the Guangzhou-Foshan metropolitan area from December 1, 2013 to February 8, 2014图4 2013年12月1日-2014年2月8日广佛都市区PM2.5暴露风险 |
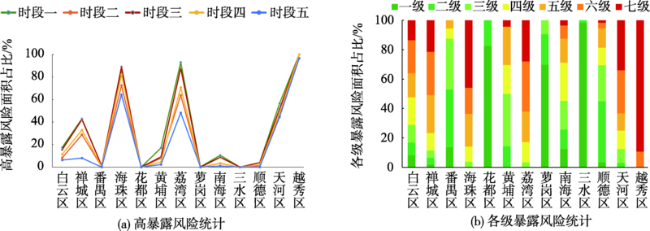
Fig. 5 Exposure risk statistics in each district of the Guangzhou-Foshan metropolitan area from December 1, 2013 to February 8, 2014图5 2013年12月1日-2014年2月8日广佛都市区各行政区暴露风险统计 |
| [1] |
|
| [2] |
中国环境科学研究院.环境空气质量标准[M].北京:中国环境科学出版社,2012.
[Technical guideline for population exposure assessment of environmental pollutant[M]. Beijing: China Environmental Science Press, 2012. ]
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
[
|
| [15] |
|
| [16] |
[
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
[
|
| [21] |
[
|
| [22] |
[
|
| [23] |
[
|
| [24] |
[
|
| [25] |
|
| [26] |
|
| [27] |
[
|
| [28] |
[
|
| [29] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}