
Journal of Geo-information Science >
Risk Assessment of Mountain Torrents based on Three Machine Learning Algorithms
Received date: 2019-04-23
Request revised date: 2019-06-17
Online published: 2019-12-11
Supported by
National Key Research and Development Program of China(No.2016YFA0601500)
Copyright
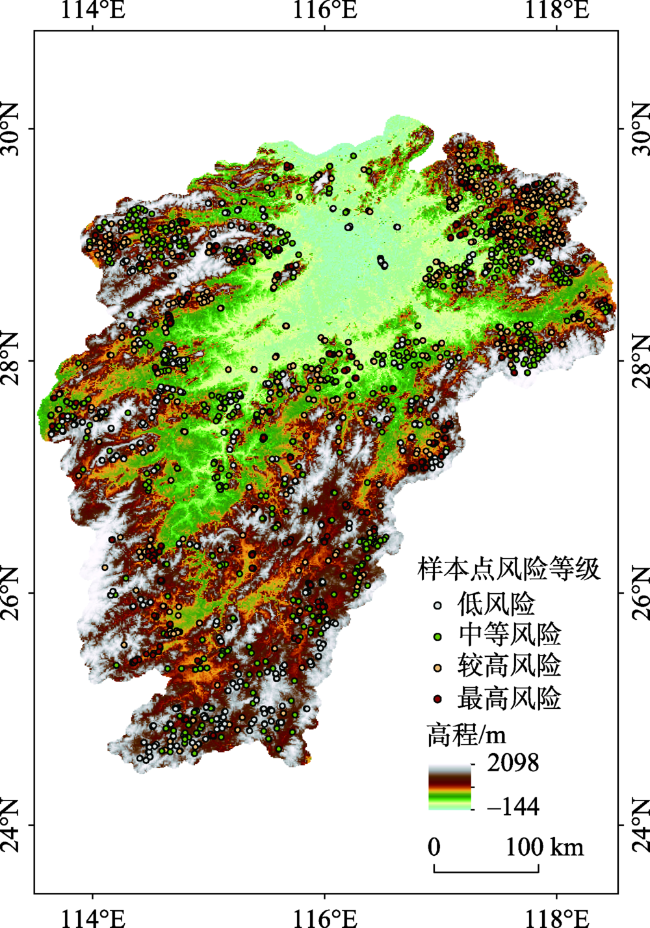
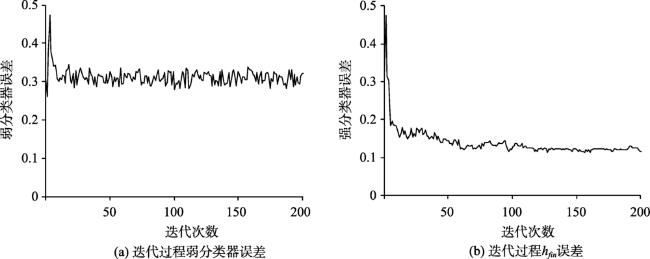
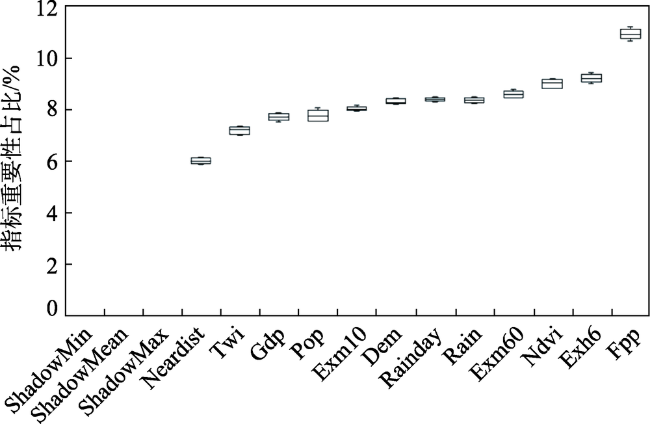
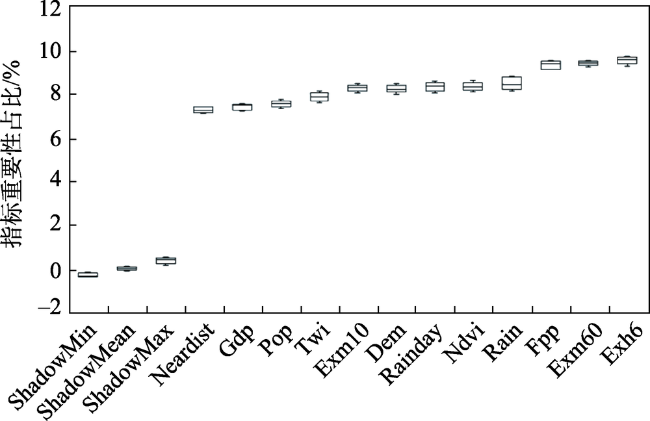
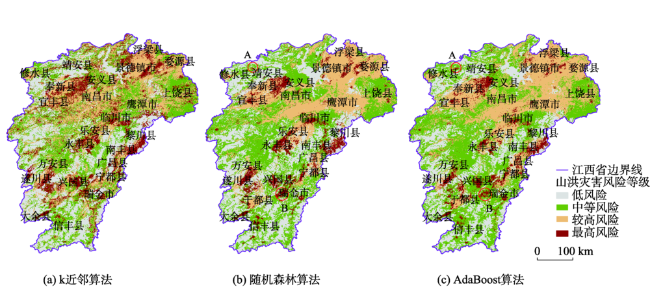
In China, floods are considered the most frequent natural disaster that can cause serious damages to the safety of human beings and severe economic losses. We chose Jiangxi Province as the study area, which frequently suffered from mountain torrents. According to the conceptual model of flood risk, 12 flood risk assessment indexes were selected from three aspects: trigger factor, hazard inducing environment, and hazard bearing agent. Three models of flood risk assessment were constructed using different machine learning algorithms, including k-Nearest Neighbor (kNN), Random Forest (RF), and AdaBoost. To evaluate the models' performances, we applied three quantitative performance indexes: accuracy, Kappa coefficient, and the ROC curve (AUC value). We analyzed the importance of indexes based on Random Forest algorithm and the feature extraction algorithm of Boruta. Then, the zoning maps of mountain flood risk drawn by the three models were used to compare and analyze the pattern of mountain flood disasters. According to the outcomes of the performance analysis, the average values of accuracy, Kappa coefficient, and AUC of the AdaBoost model were 0.902, 0.870, and 0.826, respectively. The accuracy and Kappa coefficient were slightly higher than RF, the AUC value was equivalent to RF. The three performance indexes of the kNN model were all lower than those of the other two. Our findings suggest that five indexes play very important roles in the formation of the final flood disaster risk, including potential farmland productivity, average annual maximum rainstorm within six hours, average annual maximum rainstorm within one hour, NDVI, and average annual rainfall. Our mapping results show that the areas of higher and highest risk zones account for 34.4% of Jiangxi Province. The regions with higher and highest risk are mainly distributed in the vicinity of mountains with high rainfall, heavy rainstorm, and high potential of farmland production.
ZHOU Chao , FANG Xiuqin , WU Xiaojun , WANG Yuchen . Risk Assessment of Mountain Torrents based on Three Machine Learning Algorithms[J]. Journal of Geo-information Science, 2019 , 21(11) : 1679 -1688 . DOI: 10.12082/dqxxkx.2019.190185
表1 研究数据来源Tab. 1 Data and sources |
表2 模型指标平均值计算结果Tab. 2 Performances of the three algorithms |
| Accuracy值 | Kappa系数 | AUC值 | |
|---|---|---|---|
| kNN | 0.867 | 0.822 | 0.803 |
| RF | 0.888 | 0.850 | 0.827 |
| AdaBoost | 0.902 | 0.870 | 0.826 |
| [1] |
徐在庸 . 山洪及其防治[M]. 北京: 水利出版社, 1981.
[
|
| [2] |
黄大鹏, 刘闯, 彭顺风 . 洪灾风险评价与区划研究进展[J]. 地理科学进展, 2007,26(4):11-22.
[
|
| [3] |
王秋香, 崔彩霞, 姚艳丽 . 新疆不同区域洪灾受灾面积变化趋势及多尺度分析[J]. 地理学报, 2008,63(7):769-779.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
赖成光, 陈晓宏, 赵仕威 , 等. 基于随机森林的洪灾风险评价模型及其应用[J]. 水利学报, 2015,46(1):58-66.
[
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
曹莹, 苗启广, 刘家辰 , 等. AdaBoost算法研究进展与展望[J]. 自动化学报, 2013,39(6):745-758.
[
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
管珉, 陈兴旺 . 江西省山洪灾害风险区划初步研究[J]. 暴雨灾害, 2007(4):339-343.
[
|
| [27] |
|
| [28] |
方秀琴, 王凯, 任立良 , 等. 基于GIS的江西省山洪灾害风险评价与分区[J]. 灾害学, 2017,32(1):111-116.
[
|
| [29] |
江西省水文局. 江西省暴雨洪水查算手册(2010版)[EB/OL].
[ Hydrographic Office of Jiangxi Province. Rainstorm and flood calculation manual in Jiangxi Province (2010) [EB/OL].
|
| [30] |
中国科学院资源环境科学数据中心[DB/OL].
[ Resource and Environment Data Cloud Platform[DB/OL].
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
汪云云, 陈松灿 . 基于AUC的分类器评价和设计综述[J]. 模式识别与人工智能, 2011,24(1):64-71.
[
|
| [35] |
|
| [36] |
|
| [37] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}