
Journal of Geo-information Science >
Research on Population Spatialization Method in Township Scale based on Census and Mobile Location Data
Received date: 2019-12-26
Request revised date: 2020-03-17
Online published: 2020-07-25
Supported by
the Strategic Priority Research Program of the Chinese Academy of Sciences(A类XDA19040501)
Construction Project of China Knowledge Center for Engineering Sciences and Technology(CKCEST-2019-3-6)
the Specific Informatization Scientific Research Science Program of the Chinese Academy of Sciences(XXH13505-07)
Copyright
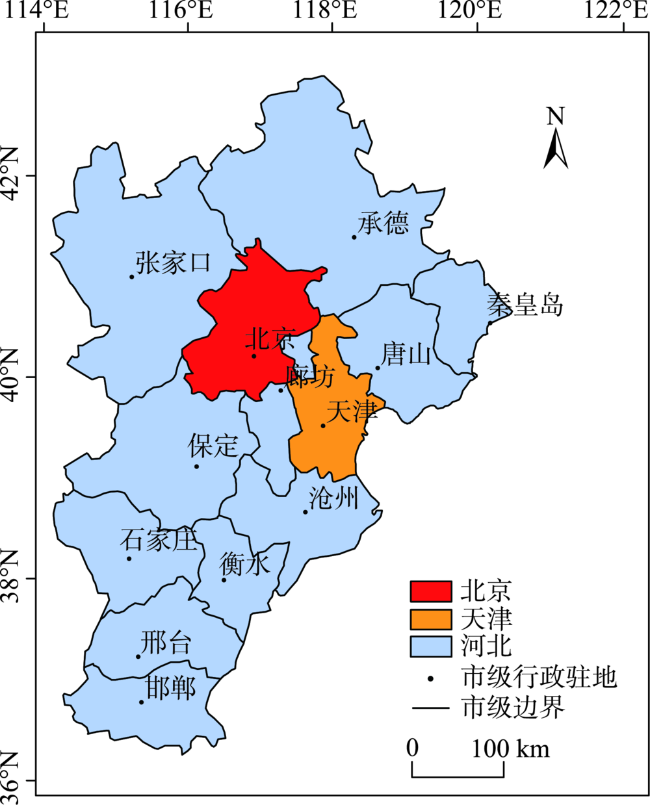
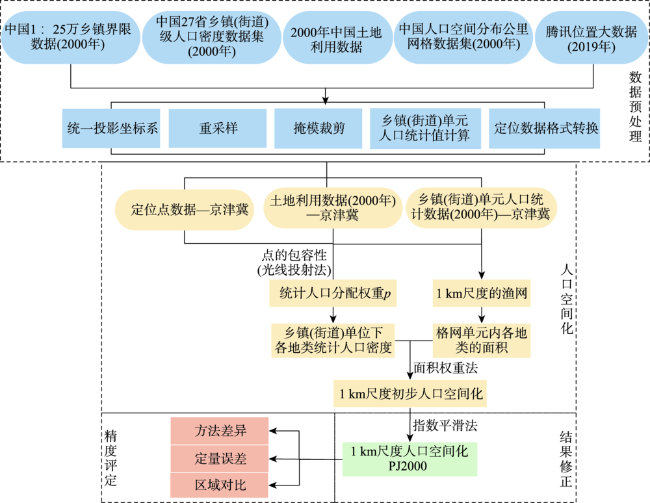
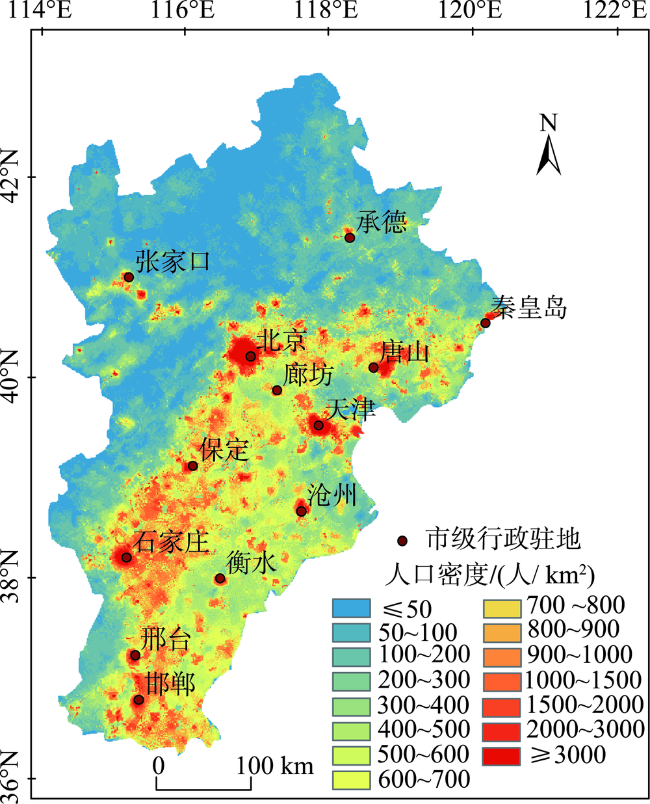
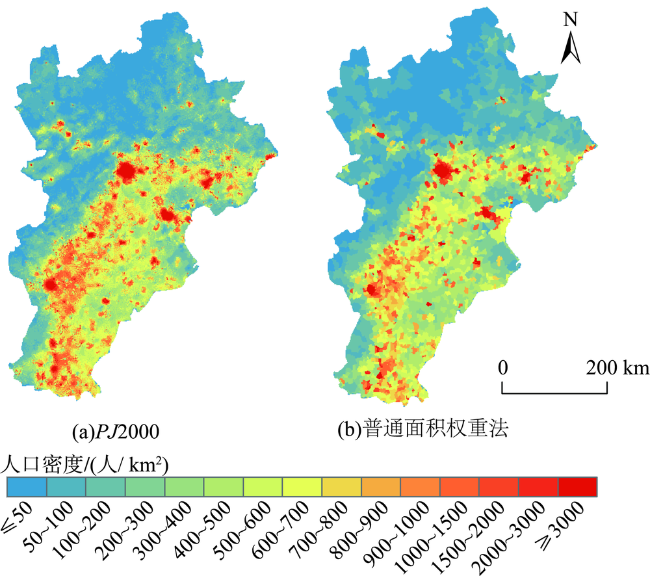
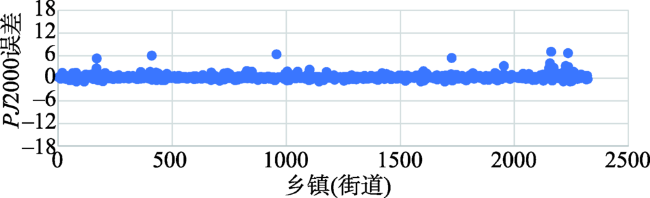
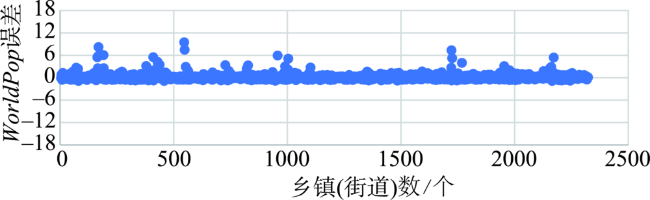
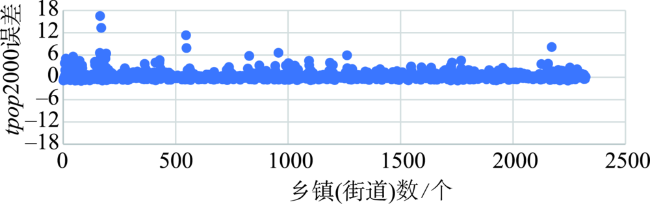
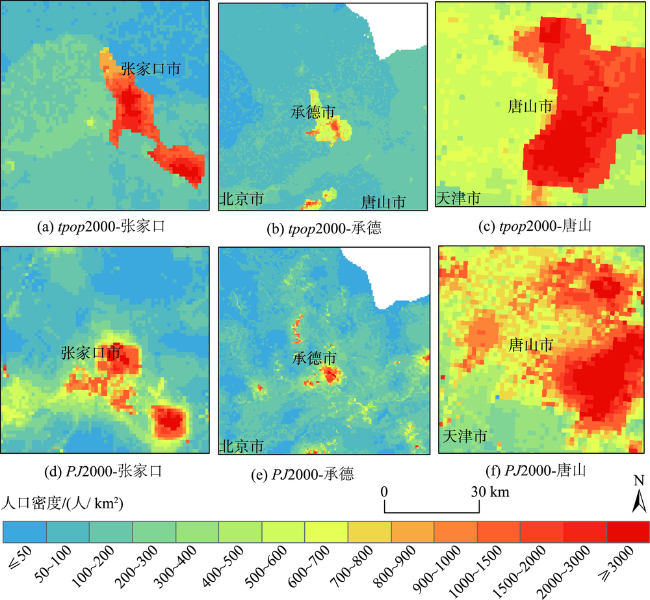
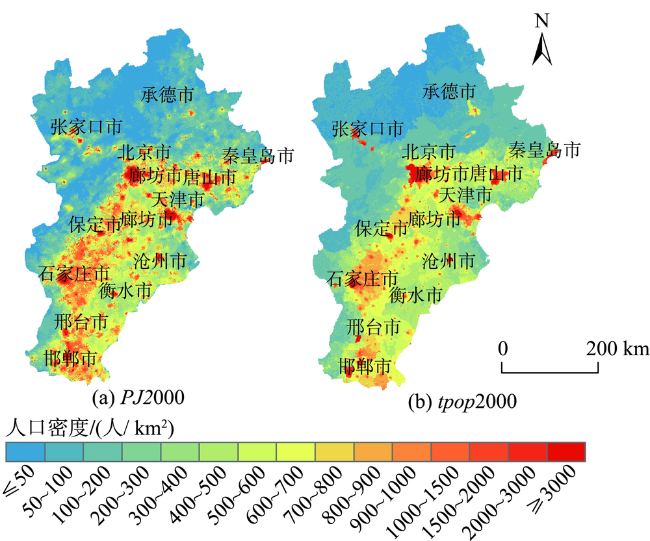
Quantifying the spatial distribution of population is a basis and hot issue in population geography researches. At present, there are large differences between different scales of spatialized population data in the world, because of various production methods, data sources, etc. This leads to the inconsistency of population spatialization, especially the 1 km-scale data which is widely needed. This paper takes Beijing-Tianjin- Hebei region as study area to build a population spatialized model at 1 km spatial resolution, based on multi-source data such as the township scale census data in 2000 and available mobile location data. The statistic population distribution weight (p) is calculated using the light projection method. Preliminary population spatialization is calculated using the area-weighted method, and the preliminary data is further modified by the exponential smoothing algorithm. Finally, the population spatialization dataset (PJ2000) with 1 km resolution in Beijing-Tianjin-Hebei region is obtained. This dataset integrates the small-scale characteristics of the township street demographic data and the advantages of mobile phone location data. The PJ2000 dataset reflects the actual location and the detailed characteristics of the population distribution in Beijing-Tianjin-Hebei region. Combined with the population density dataset (i.e., WorldPop) and China's kilometer gridded population spatial distribution dataset, the accuracy assessment of PJ2000 is carried out from three aspects: method difference, quantitative error, and regional comparison. The PJ2000 dataset solves the problem of the different distribution of population density over the same land cover type but different towns, and addresses the large difference in the gridded data of population spatialization. The overall accuracy of PJ2000 dataset is 90%, with 87% townships (streets) showing relative error less than 0.5. The correlation coefficient (r) between PJ2000 and the pop2000 township demographic data in the year of 2000 is 0.95. In addition, the population density distribution of this dataset is relatively uniform at the local to large scale. Our results prove that the accuracy of the population density dataset with 1km scale is significantly improved. The population spatialization model is constructed by integrating multi-source data such as township-level demographic data and mobile location data. In the future, it is expected that this method could be applied to obtain the population spatialization distribution for other city agglomerations. Our model could provide high-quality population density dataset for collaborative development of urban agglomeration and risk assessment of natural and man-made disasters in cities, such as earthquake, flood, fire, and public infectious diseases.
WANG Xiaojie , WANG Juanle , XUE Runsheng . Research on Population Spatialization Method in Township Scale based on Census and Mobile Location Data[J]. Journal of Geo-information Science, 2020 , 22(5) : 1095 -1105 . DOI: 10.12082/dqxxkx.2020.190806
表1 人口空间化数据源Tab.1 Population spatialization data source |
| 数据名称 | 年份 | 精度 | 来源 | 作用 |
|---|---|---|---|---|
| DMSP/OLS夜间灯光 | 2000 | — | 资源环境数据云平台(http://www.resdc.cn/data.aspx?DATAID=213) | 实验数据可用性验证 |
| 中国土地利用数据 | 2000 | 100 m | 资源环境数据云平台(http://www.resdc.cn/data.aspx?DATAID=97) | 提供各土地利用类型,以确定不同类型的人口分配权重p |
| 腾讯位置大数据 | 2019 | — | 腾讯位置大数据(https://heat.qq.com/index.php) | 计算统计人口分配权重p |
| 乡镇界线数据 | 2000 | 1:25万 | 国家科技基础条件平台—国家地球系统科学数据共享平台(http://www.geodata.cn) | 提供乡镇街道的边界 |
| 27省乡镇(街道)级人口密度数据集 | 2000 | 1 km | Science Data Bank (http://www.csdata.org/paperView?id=2) | 提供2000年乡镇街道统计人口 |
| 中国人口空间分布公里网格数据集 | 2000 | 1 km | 资源环境数据云平台(http://www.resdc.cn/DOI/DOI.aspx?DOIid=32) | 精度对比验证 |
| WorldPop数据集 | 2000 | 100 m | WorldPop(https://www.worldpop.org/) | 精度对比验证 |
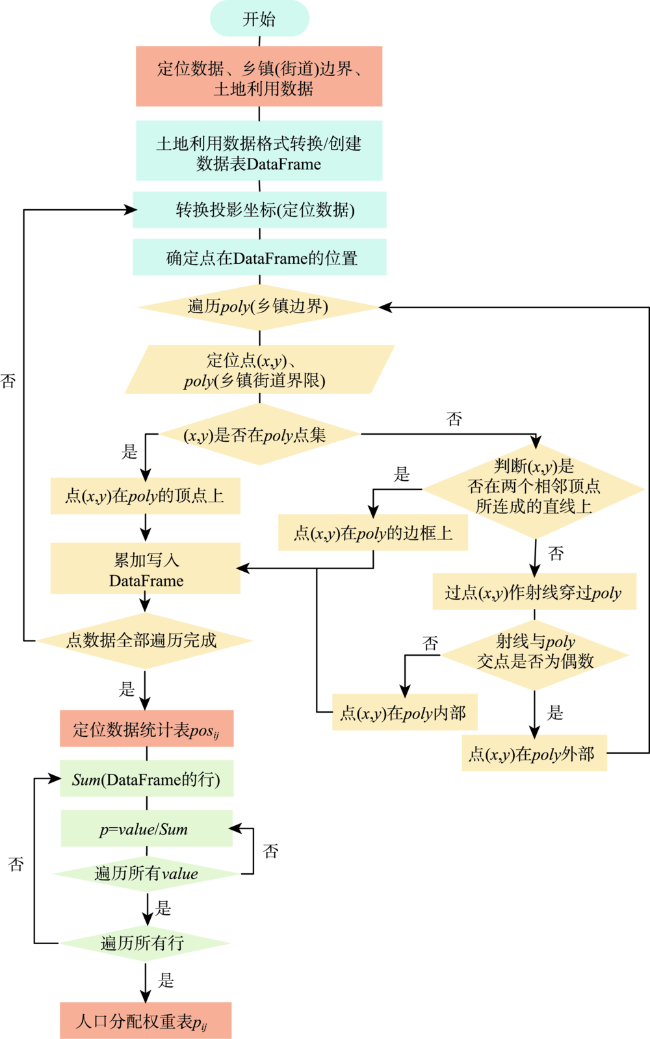
表2 腾讯定位数据统计表posijTab. 2 Tencent positioning data statistics table posij |
| 乡镇街道(序号)/地类 | 11 | 12 | 21 | 22 | 23 | 24 | 31 | 32 | 33 | 41 | 42 | … |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2063 | 403 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 1 | 0 | 14 | 1002 | 0 | 0 | 55 | 0 | 0 | 0 | 0 | 0 | … |
| 2 | 0 | 588 | 49 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 3 | 0 | 227 | 66 | 0 | 737 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 4 | 0 | 13 063 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 5 | 0 | 16 711 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 6 | 0 | 0 | 30 | 80 | 34 | 49 | 0 | 0 | 0 | 0 | 0 | … |
| 7 | 0 | 2320 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 8 | 0 | 0 | 91 | 234 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| 10 | 0 | 0 | 0 | 0 | 1197 | 0 | 0 | 0 | 0 | 0 | 0 | … |
| … | … | … | … | … | … | … | … | … | … | … | … | … |
| 2322 | 0 | 1003 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … |
表3 统计人口分配权重pijTab. 3 Statistical population distribution weight pij |
| 乡镇街道(序号)/地类 | 11 | 12 | 21 | 22 | 23 | 24 | 31 | 32 | 33 | 41 | 42 | … |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.84 | 0.16 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 1 | 0.00 | 0.01 | 0.94 | 0.00 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 2 | 0.00 | 0.92 | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 3 | 0.00 | 0.22 | 0.06 | 0.00 | 0.72 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 4 | 0.00 | 0.89 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 5 | 0.00 | 0.57 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 6 | 0.00 | 0.00 | 0.16 | 0.41 | 0.18 | 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 7 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 8 | 0.00 | 0.00 | 0.28 | 0.72 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| 10 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
| … | … | … | … | … | … | … | … | … | … | … | … | … |
| 2322 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … |
表4 显著相关性检验Tab. 4 Significant correlation test |
| PJ2000 | WorldPop | tpop2000 | |
|---|---|---|---|
| pop2000 | 0.950** | 0.935** | 0.905** |
注:**表示在1%水平(双侧)上显著相关。 |
| [1] |
杨晓荣, 陈楠. 基于多源数据的福建省人口数据空间化研究[J]. 贵州大学学报(自然科学版), 2019,36(2):79-84,95.
[
|
| [2] |
柏中强, 王卷乐, 杨飞. 人口数据空间化研究综述[J]. 地理科学进展, 2013,32(11):1692-1702.
[
|
| [3] |
陈彦光. 城市人口空间分布函数的理论基础与修正形式——利用最大熵方法推导关于城市人口密度衰减的Clark模型[J]. 华中师范大学学报(自然科学版), 2000,34(4):489-492.
[
|
| [4] |
|
| [5] |
邓顺强. 基于随机森林算法和多源数据的人口空间分布模型研究[D]. 上海:华东师范大学, 2018.
[
|
| [6] |
王明明, 王卷乐. 基于夜间灯光与土地利用数据的山东省乡镇级人口数据空间化[J]. 地球信息科学学报, 2019,21(5):699-709.
[
|
| [7] |
吴中元, 许捍卫, 胡钟敏. 基于腾讯位置大数据的精细尺度人口空间化——以南京市江宁区秣陵街道为例[J]. 地理与地理信息科学, 2019,35(6):61-65.
[
|
| [8] |
谭敏, 刘凯, 柳林, 等. 基于随机森林模型的珠江三角洲30 m格网人口空间化[J]. 地理科学进展, 2017,36(10):1304-1312.
[
|
| [9] |
田永中, 陈述彭, 岳天祥, 等. 基于土地利用的中国人口密度模拟[J]. 地理学报, 2004,59(2):283-292.
[
|
| [10] |
卓莉, 陈晋, 史培军, 等. 基于夜间灯光数据的中国人口密度模拟[J]. 地理学报, 2005,60(2):266-276.
[
|
| [11] |
黄益修. 基于夜间灯光遥感影像和社会感知数据的人口空间化研究[D]. 上海:华东师范大学, 2016.
[
|
| [12] |
杨皓斐, 曹仲, 李付琛. 基于手机大数据的动态人口感知[J]. 计算机系统应用, 2018,27(5):73-79.
[
|
| [13] |
洪东升. 基于定位数据的人口分布特征研究[D]. 北京:中国地质大学( 北京), 2015.
[
|
| [14] |
肖东升, 杨松. 基于夜间灯光数据的人口空间分布研究综述[J]. 国土资源遥感, 2019,31(3):10-19.
[
|
| [15] |
资源环境数据云平台. DMSP/OLS夜间灯光数据(2000)[DB/OL]. http://www.resdc.cn/data.aspx?DATAID=213.
[ Resource and Environment Data Cloud Platform. DMSP/OLS night light data(2000)[DB/OL]. http://www.resdc.cn/data.aspx?DATAID=213. ]
|
| [16] |
资源环境数据云平台. 中国土地利用现状遥感监测数据(2000)[DB/OL]. http://www.resdc.cn/data.aspx?DATAID=97.
[ Resource and Environment Data Cloud Platform. Remote sensing monitoring data of land use in China(2000)[DB/OL]. http://www.resdc.cn/data.aspx?DATAID=97. ]
|
| [17] |
腾讯位置大数据. 腾讯定位开放平台定位次数[DB/OL]. https://heat.qq.com/index.php. 2019.
[ Tencent's Location Big Data. Positioning of tencent positioning open platform[DB/OL]. https://heat.qq.com/index.php. 2019. ]
|
| [18] |
国家科技基础条件平台—国家地球系统科学数据共享服务平台. 中国1:25万乡镇界线数据(2000)[DB/OL]. http://www.geodata.cn. . 2017
[ National Earth System Science Data Sharing Infrastructure, National Science & Technology Infrastructure of China. China's 1:25 million township boundary data (2000) [DB/OL]. http://www.geodata.cn. . 2017]
|
| [19] |
柏中强, 王卷乐. 中国27省乡镇(街道)级人口密度数据集[J/OL]. 中国科学数据, 2016,1(1). http://www.csdata.org/paperView?id=2. DOI: 10.11922/csdata.170.2015.0002.
[
|
| [20] |
徐新良. 中国人口空间分布公里网格数据集[DB/OL]. 资源环境数据云平台, http://www.resdc.cn/DOI/DOI.aspx?DOIid=32 , 2017, DOI: 10.12078/2017121101.
[
|
| [21] |
WorldPop. China population 2000[DB/OL]. https://www. worldpop.org/geodata/summary?id=1552, 2018.
|
| [22] |
[
|
| [23] |
|
| [24] |
吴吉东, 王旭, 王菜林, 等. 社会经济数据空间化现状与发展趋势[J]. 地球信息科学学报, 2018,20(9):1252-1262.
[
|
| [25] |
潘志强, 刘高焕. 面插值的研究进展[J]. 地理科学进展, 2002,21(2):146-152.
[
|
| [26] |
张秋悦. 重庆市GDP值的趋势预测分析——基于指数平滑法[J]. 价值工程, 2019,38(27):187-189.
[
|
| [27] |
赵鑫, 宋英强, 刘轶伦, 等. 基于卫星遥感和POI数据的人口空间化研究——以广州市为例[J/OL]. 热带地理, 2019(12):1-16.
[
|
| [28] |
淳锦, 张新长, 黄健锋, 等. 基于POI数据的人口分布格网化方法研究[J]. 地理与地理信息科学, 2018,34(4):83-89,124.
[
|
| [29] |
杨旭. 人口统计数据空间化不同方案及其误差评价[D]. 开封:河南大学, 2015.
[
|
| [30] |
吴安坤, 田鹏举, 黄天福, 等. 基于人口/GDP数据空间化的雷电灾害风险评价[J]. 气象科技, 2018,46(5):1026-1031.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}