
Journal of Geo-information Science >
Extracting Mixed Topic Patterns within Downtown Beijing at the Block Level
Received date: 2019-10-11
Request revised date: 2020-02-02
Online published: 2020-08-25
Supported by
The Open Project Program of the State Key Laboratory of Virtual Reality Technology and Systems, Beihang University(01119220010011)
Copyright
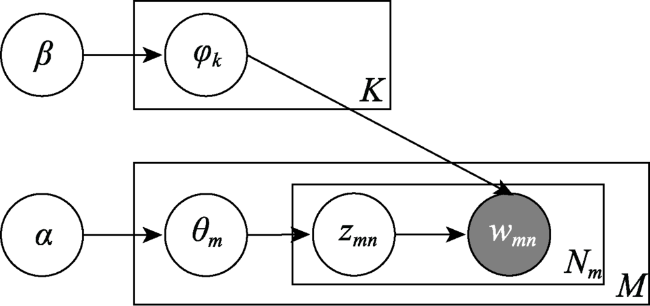
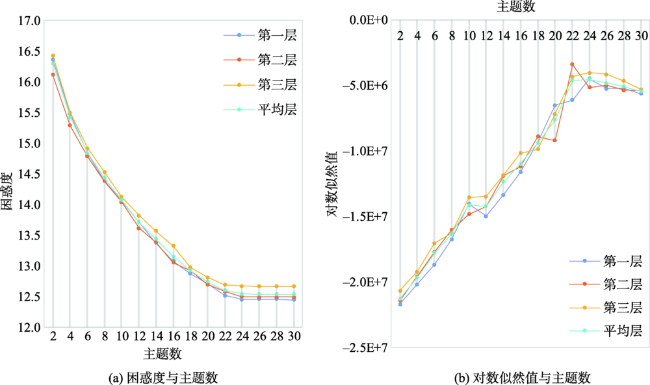
Cities with different land use types influenced by rapid urbanization and urban expansion support various human activities, such as shopping, eating, living, working, and recreation. The mixed use of land can stimulate the vitality of the city, enable the city togather enough people at different points in time, thus producing more interaction, promoting diversified consumption, and improving the economic and social benefits of the city.Mixed characteristics of land use types in cities gain more popularity in many researches due to the huge practical meanings. However, previous researches on mixed characteristics calculation mainly focused on POI data,and there is a lack of consideration for detecting urban topics. Human activities usually take place in different types of points of interest, the potential relationships and spatial interactions between the different types of adjacent POIs can work together to express the potential semantics of locations. In this paper, from an urban topic perspective, a method for the consideration of the relationship between POIs was proposed, and the Hill Numbers Diversity Index was applied to calculate the mixed degree of topics at the block level. Specifically,LDA (Latent Dirichlet Allocation) topic model was firstly used to generate topic vectors of the block and the co-occurrence patterns of POIs. Secondly, the diversity index was introduced to measure the mixed degree of blocks. Then, according to the Goodness of Variance Fit (GVF) and the nature break method, the blocks wereclassified into three groups: (1) high mixed blocks, (2) medium mixed blocks, and (3) low mixed blocks. Finally, multiple linear regression was applied based on mixed degree and topics in the blocksto uncover the significant topics and mixed pattern.Results show that different mixed blocks haddifferent mixed patterns.For high mixed blocks, the topic of teahouse restaurant was significant; the topics of company, enterprise, and residence weresignificant in medium mixed blocks; and the most typical two patterns in low mixed blocks werethe existence of landscape and famous scenery topic and teahouse restaurant topic. To sum up,starting from the urban topic, this paper reveals the mixed pattern of block, and the results show thatdifferent mixed patterns reflect the characteristics of different mixed areas and present certain rules in spatial distribution, which is conducive to the deep understanding of the cityareas, so as to provide a reference for the construction of Beijing mixed city, and also provide suggestions for other mixed cities.
Key words: block; LDA; POI co-occurrence; topic; topic mixed pattern; topic mixed degree; TF-IDF; multiple linear regression
LIU Jingjing , LIU Yusi , YI Disheng , YANG Jing , ZHANG Jing . Extracting Mixed Topic Patterns within Downtown Beijing at the Block Level[J]. Journal of Geo-information Science, 2020 , 22(6) : 1370 -1382 . DOI: 10.12082/dqxxkx.2020.190594
表1 2016年北京市四环内POI属性介绍Tab. 1 Introduction of POI Attributes within the fourth ringroad of Beijing in 2016 |
| 序号 | 属性字段名称 | 数据类型 | 作用描述 |
|---|---|---|---|
| 1 | OBJECTID | Integer | 唯一识别码 |
| 2 | 名称 | String | POI点名称 |
| 3 | x | Double | 经度 |
| 4 | y | Double | 纬度 |
| 5 | Type | String | POI类型 |
表2 2016年北京市四环内POI的类别Tab. 2 Categories of POIs within the fourth ringroad of Beijing in 2016 |
| 类别 | 名称 | 类别 | 名称 |
|---|---|---|---|
| 1 | 茶座甜品 | 13 | 科研机构 |
| 2 | KTV | 14 | 培训机构 |
| 3 | 展览馆 | 15 | 体育场馆 |
| 4 | 公司企业 | 16 | 图书馆 |
| 5 | 大学 | 17 | 餐厅 |
| 6 | 风景名胜 | 18 | 文化宫 |
| 7 | 购物中心 | 19 | 基础教育 |
| 8 | 集市 | 20 | 银行 |
| 9 | 商铺 | 21 | 游乐园 |
| 10 | 酒吧 | 22 | 住宅区 |
| 11 | 酒店 | 23 | 医院 |
| 12 | 剧院 |
表3 典型街区中前6类POI权重结果Tab. 3 Weight results of the first six POIs in typical blocks |
| 街区1 | 街区216 | 街区345 | 街区360 | ||||
|---|---|---|---|---|---|---|---|
| POI类型 | 权重 | POI类型 | 权重 | POI类型 | 权重 | POI类型 | 权重 |
| 游乐园 | 10.33 | 风景名胜 | 7.45 | 商铺 | 13.99 | 商铺 | 17.8 |
| 商铺 | 6.82 | 游乐园 | 1.44 | 餐厅 | 7.49 | 住宅区 | 9.30 |
| 公司企业 | 6.62 | 公司企业 | 0.69 | 酒吧 | 5.83 | 餐厅 | 9.28 |
| 餐厅 | 3.41 | 茶座甜品 | 0.36 | 住宅区 | 5.57 | 公司企业 | 6.18 |
| 风景名胜 | 3.37 | 基础教育 | 0.20 | 茶座甜品 | 5.35 | 酒店 | 1.99 |
| 茶座甜品 | 3.30 | 商铺 | 0.17 | 购物中心 | 2.20 | 茶座甜品 | 1.48 |
表4 LDA建模结果中部分主题的前5类POITab. 4 Top 5 POIs of some topics in LDA modeling results |
| 主题1 | 主题2 | 主题4 | 主题7 | 主题12 | 主题14 |
|---|---|---|---|---|---|
| 茶座甜品 | 风景名胜 | 酒吧 | 图书馆 | 购物中心 | 科研机构 |
| 餐厅 | 餐厅 | 餐厅 | 住宅区 | 商铺 | 商铺 |
| 商铺 | 酒店 | 茶座甜品 | 餐厅 | 餐厅 | 茶座甜品 |
| 培训机构 | 剧院 | 住宅区 | 商铺 | 茶座甜品 | 餐厅 |
| 公司企业 | 公司企业 | 商铺 | 银行 | 酒吧 | 基础教育 |
| 主题 15 | 主题 16 | 主题 17 | 主题 19 | 主题 20 | 主题 21 |
| 酒店 | 游乐园 | 公司企业 | 住宅区 | 体育场馆 | 大学 |
| 餐厅 | 茶座甜品 | 餐厅 | 商铺 | 餐厅 | 餐厅 |
| 商铺 | 公司企业 | 培训机构 | 餐厅 | 商铺 | 商铺 |
| 体育场馆 | 商铺 | 基础教育 | 公司企业 | 培训机构 | 茶座甜品 |
| 文化宫 | 购物中心 | 文化宫 | 酒店 | 公司企业 | 公司企业 |
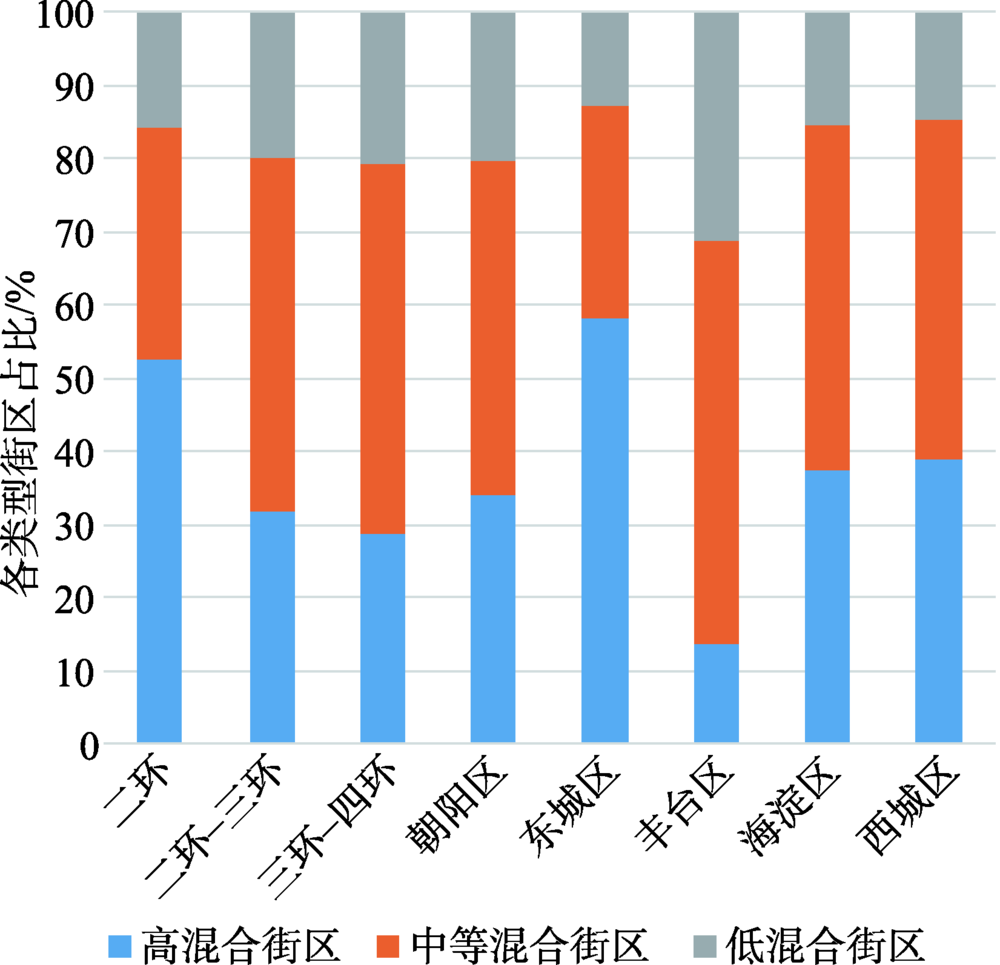
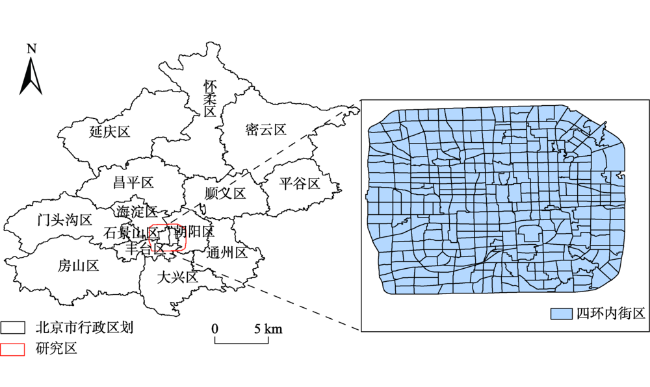
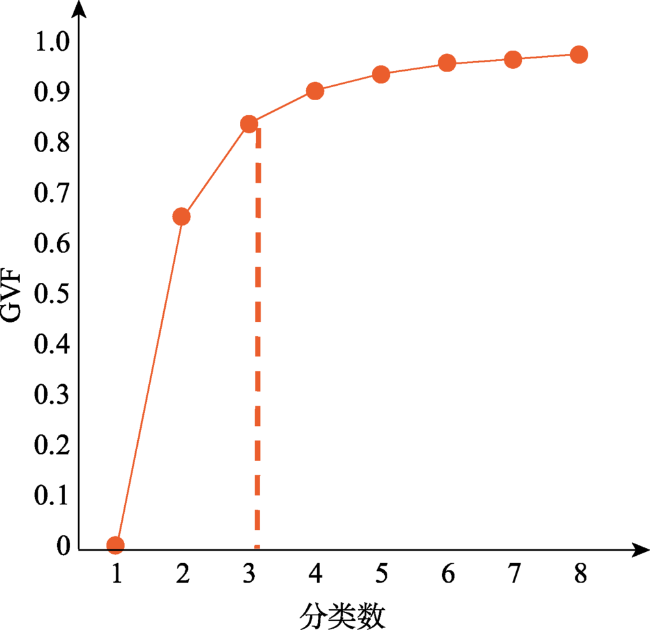
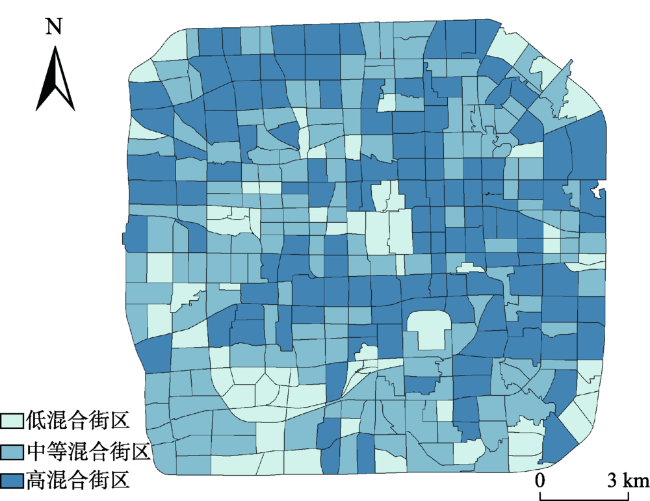
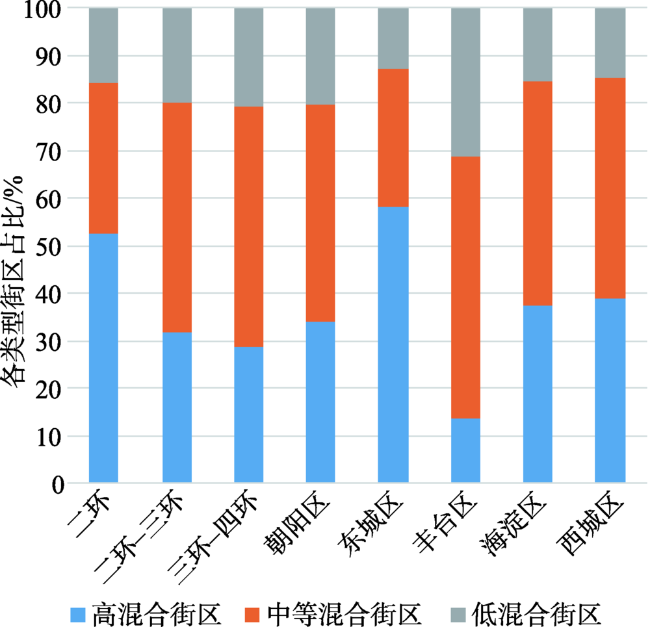
图5 四环区域内自然断裂法划分的街区分布Fig. 5 Block distribution within the fourth ringroad of Beijing by natural break method |
表5 3类混合街区多元线性回归方程的显著性Tab. 5 Significance of multivariate linear regression equation for three kinds of mixed block |
| 回归模型 | F | Sig. |
|---|---|---|
| 高混合街区 | 16.706 | 0.000 |
| 中等混合街区 | 11.399 | 0.000 |
| 低混合街区 | 9.467 | 0.000 |
表6 街区混合度与22维主题的多元线性回归结果Tab. 6 Results of multiple linear regression for block mixing degree and 22 topics |
| 变量 | 非标准化系数 | 标准误差 | 标准系数 | t | Sig. | |
|---|---|---|---|---|---|---|
| 高混和街区(R2=0.497) | (常量) | 17.763 | 0.549 | — | 32.336 | 0.000 |
| 主题19 | -17.463 | 2.849 | -0.464 | -6.131 | 0.000 | |
| 主题20 | -6.754 | 3.210 | -0.151 | -2.104 | 0.037 | |
| 主题12 | 8.440 | 2.665 | 0.214 | 3.168 | 0.002 | |
| 主题4 | 9.335 | 2.683 | 0.241 | 3.479 | 0.001 | |
| 主题1 | -22.574 | 4.687 | -0.433 | -4.816 | 0.000 | |
| 主题21 | -7.635 | 2.113 | -0.304 | -3.614 | 0.000 | |
| 主题18 | -5.585 | 2.114 | -0.188 | -2.641 | 0.009 | |
| 主题13 | 7.611 | 3.118 | 0.160 | 2.440 | 0.016 | |
| 中等混合街区(R2=0.361) | (常量) | 12.132 | 0.403 | — | 30.069 | 0.000 |
| 主题19 | -8.329 | 1.575 | -0.366 | -5.289 | 0.000 | |
| 主题20 | -4.761 | 1.914 | -0.181 | -2.488 | 0.014 | |
| 主题17 | -5.142 | 1.869 | -0.186 | -2.750 | 0.007 | |
| 主题10 | 6.550 | 2.290 | 0.196 | 2.861 | 0.005 | |
| 主题22 | 5.275 | 2.331 | 0.160 | 2.263 | 0.025 | |
| 主题13 | 4.525 | 2.265 | 0.141 | 1.998 | 0.047 | |
| 低混合街区(R2=0.425) | (常量) | 4.508 | 0.265 | — | 17.016 | 0.000 |
| 主题5 | 20.417 | 4.915 | 0.396 | 4.154 | 0.000 | |
| 主题1 | 5.628 | 1.857 | 0.288 | 3.031 | 0.004 | |
| 主题3 | 11.469 | 4.556 | 0.243 | 2.517 | 0.014 | |
| 主题6 | 12.533 | 4.640 | 0.260 | 2.701 | 0.009 | |
| 主题2 | -2.460 | 1.014 | -0.236 | -2.426 | 0.018 |
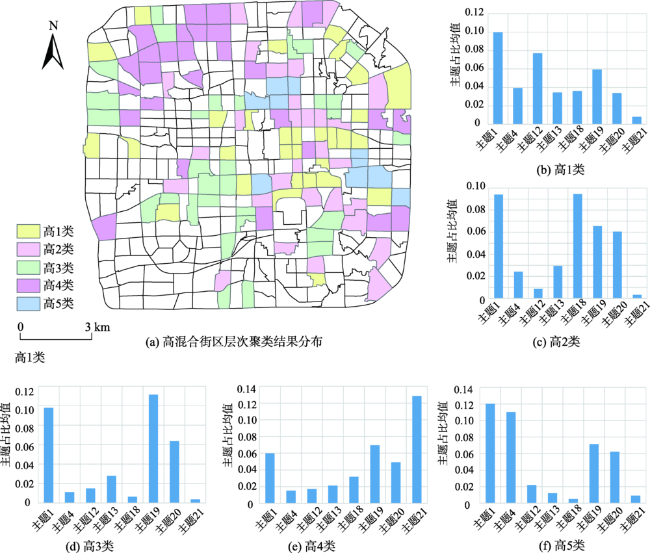
图7 高混合街区层次聚类结果分布及各类中主题均值Fig. 7 The distribution of hierarchical clustering results and the histogram of mean value of various subjects in high mixed block |
表7 高混合街区主题混合模式Tab. 7 Mixed pattern of high mixed blocks |
| 模式类型 | 主题混合模式 |
|---|---|
| 模式1(高1类) | 购物中心主题+住宅(商铺)主题+茶座餐厅主题+其他 |
| 模式2(高2类) | 医院主题+茶座餐厅主题+其他 |
| 模式3(高3类) | 住宅(商铺)主题+茶座餐厅主题+其他 |
| 模式4(高4类) | 大学主题+茶座餐厅主题+住宅(商铺)主题+其他 |
| 模式5(高5类) | 酒吧主题+茶座餐厅主题+其他 |
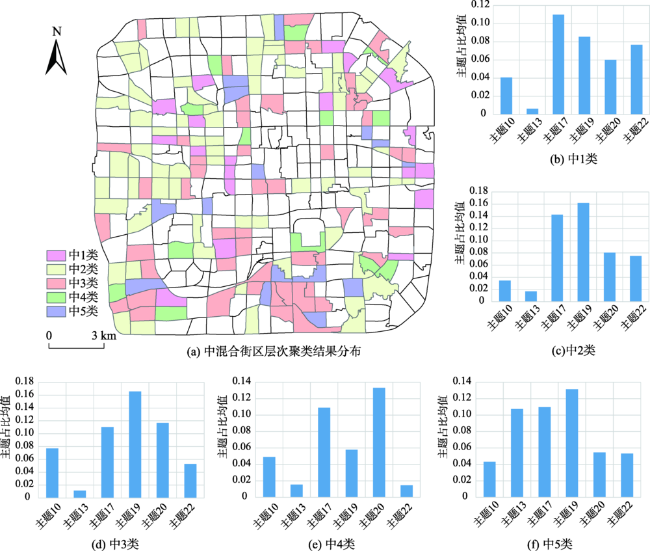
图8 中混合街区层次聚类结果分布及各类中主题均值Fig. 8 The distribution of hierarchical clustering results and the histogram of mean value of various subjects in middle mixed block |
表8 中混合街区主题混合模式Tab. 8 Mixed pattern of medium mixed blocks |
| 模式类型 | 主题混合模式 |
|---|---|
| 模式1(中1类) | 公司企业主题+住宅(商铺)主题+银行主题+其他 |
| 模式2(中2类) | 公司企业主题+住宅(商铺)主题+其他 |
| 模式3(中3类) | 住宅(商铺)主题+公司企业主题+体育场馆主题+其他 |
| 模式4(中4类) | 公司企业主题+体育场馆主题+其他 |
| 模式5(中5类) | 休闲娱乐主题+公司企业主题+住宅(商铺)主题+其他 |
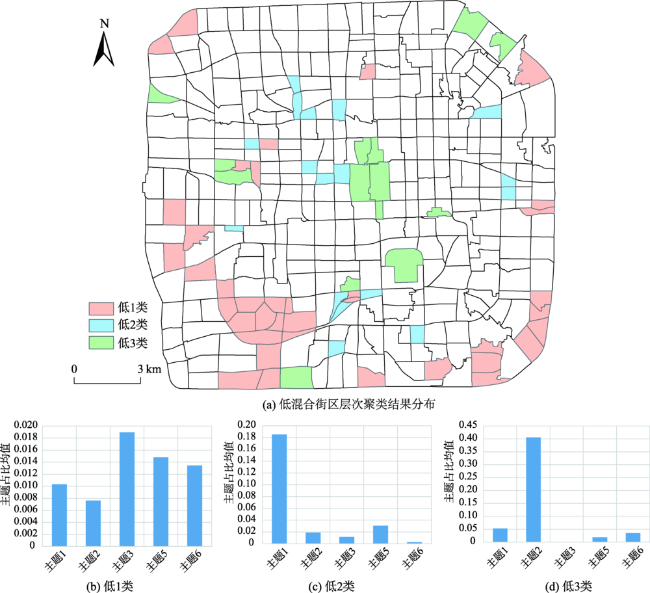
图9 低混合街区层次聚类结果分布及各类中主题均值Fig. 9 The distribution of hierarchical clustering results and the histogram of mean value of various subjects in low mixed block |
表9 低混合街区主题混合模式Tab. 9 Mixed pattern of low mixed blocks |
| 模式类型 | 主题混合模式 |
|---|---|
| 模式1(低1类) | 住宅(集市)主题+展览馆主题+其他 |
| 模式2(低2类) | 茶座餐厅主题+其他 |
| 模式3(低3类) | 风景名胜主题+其他 |
| [1] |
黄毅. 城市混合功能建设研究[D]. 上海:同济大学, 2008.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
龚咏喜, 李贵才, 林姚宇. 土地利用对城市居民出行碳排放的影响研究[J]. 城市发展研究, 2013,20(9):112-118.
[
|
| [6] |
包宇. 城市土地混合利用测度研究——以深圳市为例[J]. 湖北农业科学, 2016,55(22):5794-5797.
[
|
| [7] |
|
| [8] |
李苗裔, 马妍, 孙小明, 等. 基于多源数据时空熵的城市功能混合度识别评价[J]. 城市规划, 2018,42(2):97-103.
[
|
| [9] |
|
| [10] |
宁晓平. 土地利用结构与城市活力的影响分析[D]. 深圳:深圳大学, 2016.
[
|
| [11] |
许思扬, 陈振光. 混合功能发展概念解读与分类探讨[J]. 规划师, 2012,28(7):105-109.
[
|
| [12] |
|
| [13] |
康朝贵, 刘瑜, 邬伦. 城市手机用户移动轨迹时空熵特征分析[J]. 武汉大学学报·信息科学版, 2017,42(1):63-69.
[
|
| [14] |
康雨豪, 王玥瑶, 夏竹君. 利用POI数据的武汉城市功能区划分与识别[J]. 测绘地理信息, 2018,43(1):81-85.
[
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
百度地图开放平台[EB/OL]: http://lbsyun.baidu.com/.
[ Baidu Map Open Platform: http://lbsyun.baidu.com/.]
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
刘瑜, 詹朝晖, 朱递, 等. 集成多源地理大数据感知城市空间分异格局[J]. 武汉大学学报·信息科学版, 2018,43(3):327-335.
[
|
| [24] |
刘瑜. 社会感知视角下的若干人文地理学基本问题再思考[J]. 地理学报, 2016,71(4):564-575.
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
秦萧, 甄峰. 大数据与小数据结合:信息时代城市研究方法探讨[J]. 地理科学, 2017,37(3):321-330.
[
|
| [29] |
刘瑜, 康朝贵, 王法辉. 大数据驱动的人类移动模式和模型研究[J]. 武汉大学学报·信息科学版, 2014,39(6):660-666.
[
|
| [30] |
陈瑗瑗, 高勇. 利用社交媒体的位置潜语义特征提取与分析[J]. 地球信息科学学报, 2017,19(11):1405-1414.
[
|
| [31] |
李航. 统计学习方法—第二版[M]. 北京: 清华大学出版社, 2019.
[
|
| [32] |
陈泽东, 谯博文, 张晶. 基于居民出行特征的北京城市功能区识别与空间交互研究[J]. 地球信息科学学报, 2018,20(3):291-301.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}