
Journal of Geo-information Science >
Parallel Construction and Distributed Storage for Vector Tile
Received date: 2019-05-23
Request revised date: 2019-11-12
Online published: 2020-09-25
Supported by
National Natural Science Foundation of China(31770768)
The Natural Science Foundation of Heilongjiang Province of China(F2017001)
Heilongjiang Province Applied Technology Research and Development Program Major Project(GA18B301)
Copyright
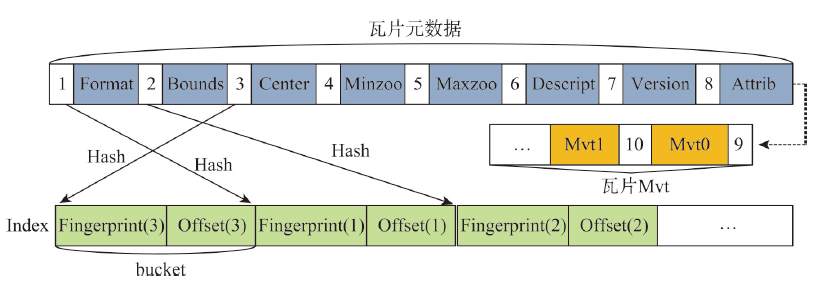
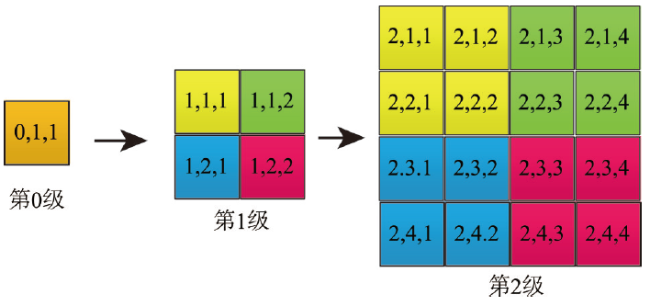
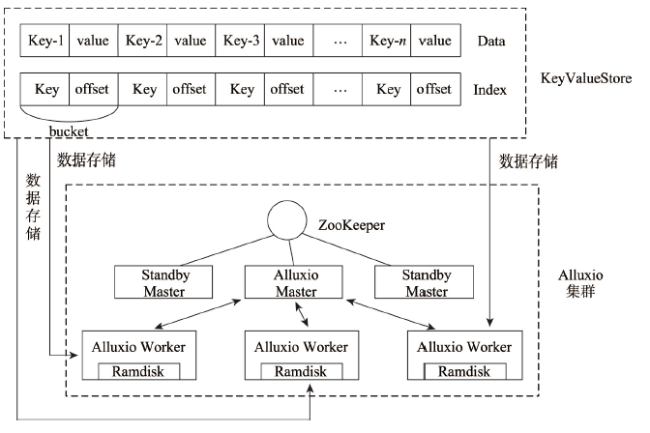
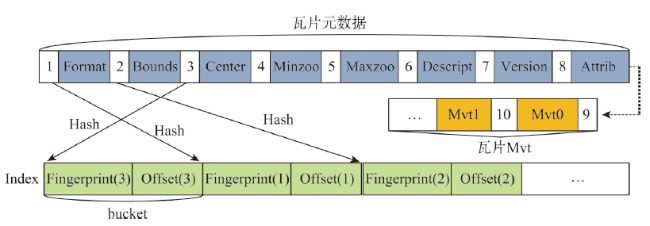
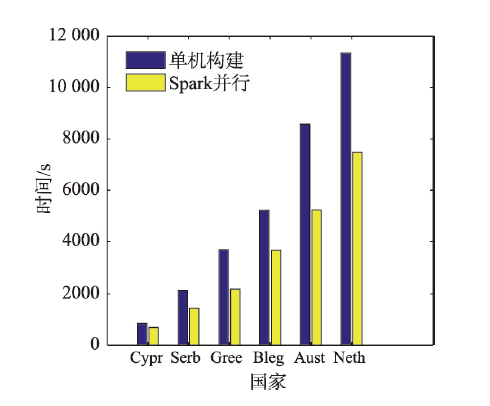
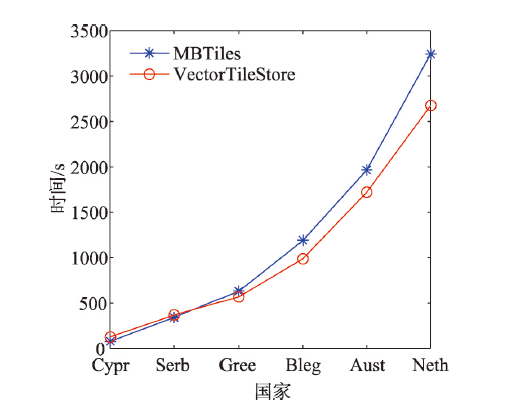
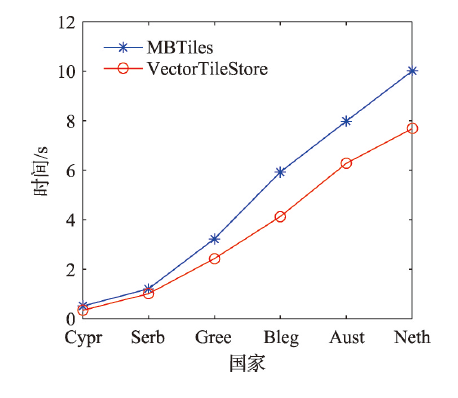
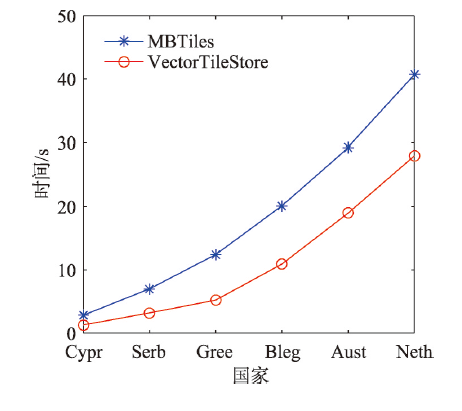
With the deepening of the information technology, Internet maps containing multi-source geospatial information are widely used in many fields such as forestry, ocean, land, transportation, and military. At the same time, due to the advancement of Earth observation, surveying, and mapping technology, spatial data with high precision and wide coverage has grown rapidly, leading to an era of geospatial big data. Under this background, how to quickly and efficiently construct Internet map services becomes the current research priorities and challenges. Grid tiles has been used to construct Internet maps at the beginning, and played an important role in the fast-growing popularity of Internet maps. However, with the mobilization of maps and the gradual deepening of applications, the disadvantages of large size and low efficiency of applying grid tiles are becoming more and more obvious, which is difficult to meet the needs of applications. Vector tiles have many advantages over traditional grid tiles, such as small in size, high in generation efficiency, and support dynamic interaction, are becoming the focus of next generation Internet map service research. In order to further accelerate the processing speed and enhance the scalability in current vector tile application, this study uses big data technology for vector tile processing. Firstly, we uses the parallel computing framework-Spark, to build the vector tile pyramid model. Specifically, through customizing the Spark conversion function, the steps of tile generation are parallelized, and the original vector data GeoJson is converted into a vector tile set-MapBox Vector Tile (Mvt). Then we designs a tile storage model-VectorTile Store, to store the generated Mvt based on the distributed memory filesystem-Alluxio. The VectorTile Store model stores data with key-value pairs, with the tile metadata occupying the first eight key-value pairs, and each single tile occupying a key-value pair. When the data is being written, a hash index is built based on the key for fast access. This model efficiently stores massive tiles and is highly scalable. The experimental results show that the vector tile parallel construction algorithm and distributed storage model proposed in this paper are more efficient than traditional schemes, and are more suitable for massive vector tile data processing.
Key words: vector tile; web map service; parallel processing; spark; distributed storage; alluxio
NIE Pei , CHEN Guangsheng , JING Weipeng . Parallel Construction and Distributed Storage for Vector Tile[J]. Journal of Geo-information Science, 2020 , 22(7) : 1487 -1496 . DOI: 10.12082/dqxxkx.2020.190255
| [1] |
张晓祥. 大数据时代的空间分析[J]. 武汉大学学报·信息科学版, 2014,39(6):655-659.
[
|
| [2] |
周侗, 龙毅. 我国近期移动地图与互联网地图发展综述[J]. 地理与地理信息科学, 2012,28(5):1-5.
[
|
| [3] |
|
| [4] |
聂沛, 陈广胜, 景维鹏. 一种面向遥感影像的分布式存储方法[J]. 测绘工程, 2018,27(11):43-48.
[
|
| [5] |
朱秀丽, 周治武, 李静. 网络矢量地图瓦片技术研究[J]. 测绘通报, 2016(11):106-109.
[
|
| [6] |
刘义, 陈荦, 景宁, 等. 利用MapReduce进行批量遥感影像瓦片金字塔构建[J]. 武汉大学学报·信息科学版, 2013,38(3):278-282.
[
|
| [7] |
赫高进, 吴秋云, 陈荦, 等. 基于MPI的大规模遥感影像金字塔并行构建方法[J]. 地球信息科学学报, 2015,17(5):515-522.
[
|
| [8] |
|
| [9] |
陈桦, 李艳明, 朱美正. 一种支持大量并发用户的瓦片缓存方案研究[J]. 计算机工程与科学, 2012,34(12):144-149.
[
|
| [10] |
陈举平, 丁建勋. 矢量瓦片地图关键技术研究[J]. 地理空间信息, 2017(8):44-47.
[
|
| [11] |
张立强, 徐翔, 谭继强. 基于并行技术的大规模矢量地图可视化方法[J]. 地理与地理信息科学, 2013,29(4):13-16.
[
|
| [12] |
金澄, 安晓亚, 崔海福, 等. 矢量瓦片地图线化简算法研究[J]. 地球信息科学学报, 2019,21(10):1502-1509.
[
|
| [13] |
朱笑笑, 张丰, 杜震洪. 顾及要素空间分布特征的稠疏矢量瓦片构建方法研究[J]. 浙江大学学报:理学版, 2017(44):591-598.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
The Alluxio Open Foundation. Key-value system client api[EB/OL]. https://github.com/Alluxio/alluxio/blob/bra nch-1.8/docs/en/api/Key-Value-System-API.md. 2018-10.
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}