
Journal of Geo-information Science >
Estimating Soil Organic Matter based on Machine Learning Under Sparse Sample
Received date: 2019-08-13
Request revised date: 2019-12-14
Online published: 2020-11-25
Supported by
The National Key Research and Development Program of China(2017YFD0801205)
The Science and Technology Innovation Capacity Building Project of Beijing Academy of Agriculture and Forestry Sciences(KJCX20170407)
The Science and Technology Innovation Capacity Building Project of Beijing Academy of Agriculture and Forestry Sciences(KJCX20200414)
Scientific Research Project Funded by The Education Department of Hunan Province(13B129)
Project Supported by Open Fund of Hunan Engineering Laboratory(KFJ180602)
Copyright
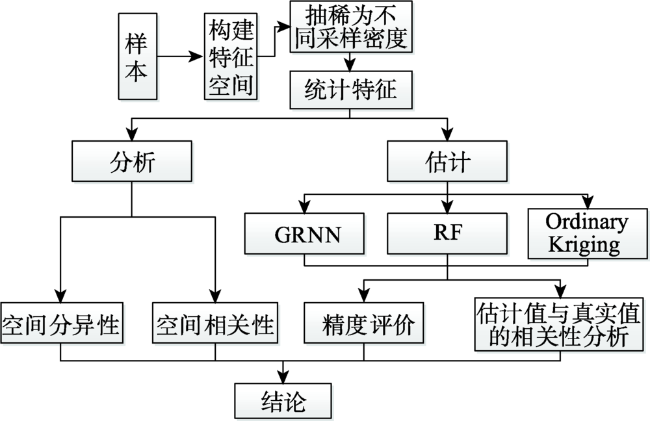
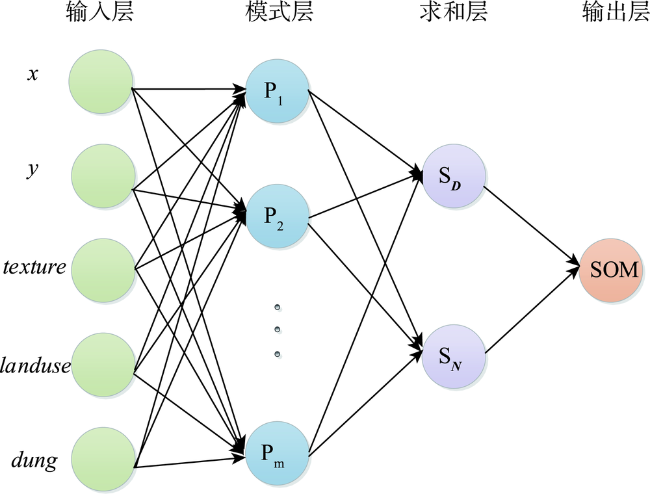
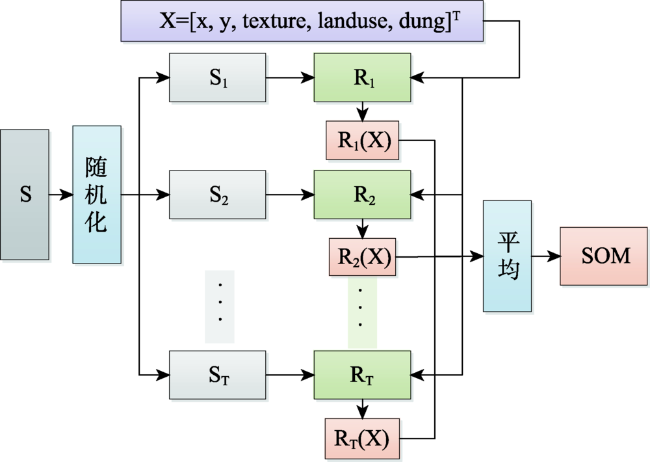
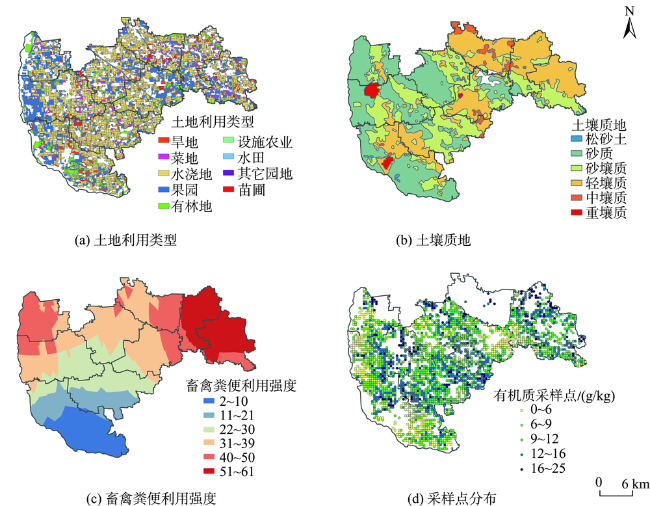
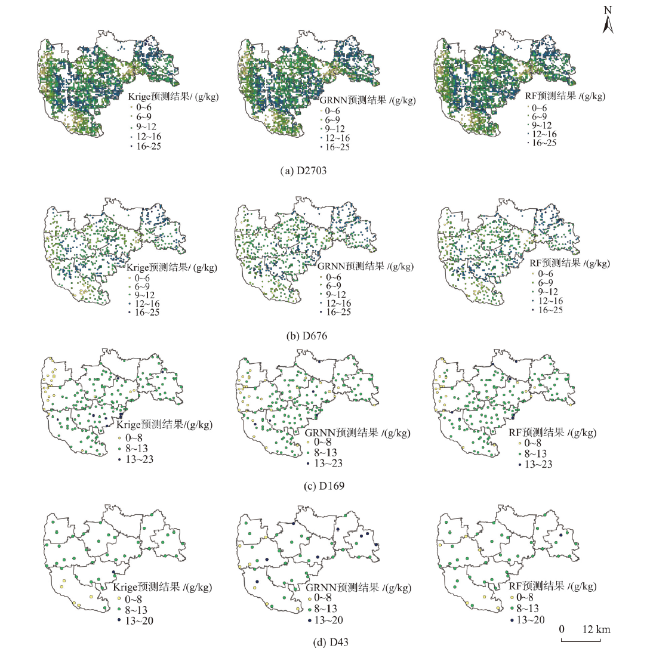
To improve the accuracy of soil organic estimation in the case of sparse samples and to construct the soil organic predictive models applying the machine learning methods, GRNN (Generalized Regression Neural Network) and RF(Random Forest). The soil was diluted into 8 samples with different sampling density (2703, 1352, 676, 339, 169, 85, 43, 22 samples) according to the soil organic matter sampling data of Daxing agricultural land in 2007 applying the MMSD (Minimization of the Mean of the Shortest Distances) criterion. GRNN (Generalized Regression Neural Network), RF (random forest) and Ordinary Kriging are applied to predict each sampling density espectively. Cross Validation is used to verify the prediction accuracy of unknown samples at each sampling density. With the decrease of sampling point density, the spatial correlation between sampling points decreases gradually, thus the semivariogram's fitting precision deteriorates, the errorofprediction point result increases, and the confidence of the prediction decreases. The spatial correlation between sampling points is close to disappear when the sample is diluted under 43 and 22 samples, and the coefficient of determination of the semivariogram function is low and the residual is large. The impacts the Ordinary Kriging receives, which are from the changes in the number of the sampling points, sampling density and spatial structures of samples is obvious. The prediction accuracy of the method decreases with the decrease of the number of sampling points. There is no significant correlation between the predicted values and the observed values at or below 85 sampling points. The prediction accuracy of GRNN and RF is almost independent of the sampling density. The predicted values fluctuate within a certain threshold space around the observed values, and has good correlation. At sampling points of 85 and below, the prediction accuracy is greatly improved compared with Ordinary Kriging. Ordinary Kriging is not suitable for spatial interpolating calculation in the case of sparse samples, especially in the case of weak spatial correlation. The machine learning models can fully learn the environmental information and spatial proximity information of soil sampling points. They combine attribute similarity and spatial correlation and have better stability and adaptability, not being easy to be affected by the number of sampling points, configuration and sampling density, and can make stable and accurate predictions even when the spatial autocorrelation between sampling points is very weak.

LIU Mingjie , XU Zhuokui , GAO Yunbing , YANG Jing , PAN Yuchun , GAO Bingbo , ZHOU Yanbing , ZHOU Wanpeng , WANG Ling . Estimating Soil Organic Matter based on Machine Learning Under Sparse Sample[J]. Journal of Geo-information Science, 2020 , 22(9) : 1799 -1813 . DOI: 10.12082/dqxxkx.2020.190441
表1 土壤有机质含量方差分析Tab. 1 Variance analysis of soil organic matter |
| 方差来源 | 偏差平方和 | 自由度Df | 均方 | F | P | |
|---|---|---|---|---|---|---|
| 用地类型 | 组间 | 351.750 | 4 | 87.938 | 6.871 | 0.000 |
| 组内 | 1023.868 | 80 | 12.796 | |||
| 总体 | 1375.618 | 84 | ||||
| 土壤质地 | 组间 | 356.405 | 3 | 118.802 | 9.442 | 0.000 |
| 组内 | 1019.213 | 81 | 12.583 | |||
| 总体 | 1375.618 | 84 | ||||
| 畜禽粪便利用强度 | 组间 | 241.351 | 5 | 48.270 | 3.362 | 0.008 |
| 组内 | 1134.267 | 79 | 14.358 | |||
| 总体 | 1375.618 | 84 | ||||
| 土壤类型 | 组间 | 0.945 | 2 | 0.472 | 0.028 | 0.972 |
| 组内 | 1374.674 | 82 | 16.764 | |||
| 总体 | 1375.618 | 84 | ||||
| 植被指数 | 组间 | 17.592 | 2 | 8.796 | 0.531 | 0.590 |
| 组内 | 1358.027 | 82 | 16.561 | |||
| 总体 | 1375.618 | 84 |
表2 研究区所有实验组土壤有机质含量描述性统计Tab. 2 Descriptive statistics of soil organic matter in all experimental groups in the study area |
| 实验组 | 极大值/ (g/kg) | 极小值/ (g/kg) | 平均值/ (g/kg) | 标准差/ (g/kg) | 变异 系数 | 偏度 | 峰度 | K-S双侧 显著性 |
|---|---|---|---|---|---|---|---|---|
| D2703 | 24.73 | 1.20 | 10.49 | 3.91 | 37.28 | 0.147 | -0.098 | 0.302 |
| D1352 | 24.73 | 1.65 | 10.53 | 3.92 | 37.23 | 0.159 | -0.003 | 0.632 |
| D676 | 24.73 | 1.65 | 10.58 | 4.11 | 38.87 | 0.318 | 0.036 | 0.640 |
| D339 | 24.73 | 1.81 | 10.55 | 3.94 | 37.32 | 0.223 | 0.292 | 0.946 |
| D169 | 22.98 | 1.98 | 10.20 | 3.99 | 39.08 | 0.290 | 0.112 | 0.964 |
| D85 | 18.05 | 2.03 | 10.93 | 4.05 | 37.01 | -0.181 | -0.804 | 0.934 |
| D43_1 | 17.97 | 4.35 | 11.07 | 3.46 | 31.24 | -0.187 | -0.616 | 0.972 |
| D43_2 | 17.73 | 2.98 | 10.07 | 4.17 | 41.39 | 0.122 | -0.893 | 0.951 |
| D43_3 | 17.84 | 3.53 | 11.10 | 3.53 | 31.80 | -0.091 | -0.900 | 0.855 |
| D43_4 | 19.67 | 2.02 | 10.33 | 4.04 | 39.13 | 0.128 | -0.064 | 0.906 |
| D43_5 | 17.68 | 2.19 | 10.39 | 4.46 | 42.90 | -0.329 | -0.998 | 0.445 |
| D22_1 | 18.28 | 3.53 | 10.70 | 4.30 | 40.13 | 0.293 | -0.988 | 0.611 |
| D22_2 | 17.61 | 3.91 | 11.28 | 3.84 | 34.03 | -0.037 | -0.634 | 0.940 |
| D22_3 | 16.40 | 3.72 | 10.49 | 3.60 | 34.29 | -0.380 | -0.692 | 0.783 |
| D22_4 | 15.34 | 4.29 | 10.56 | 3.24 | 30.72 | -0.320 | -0.825 | 0.912 |
| D22_5 | 17.86 | 2.36 | 9.35 | 4.36 | 46.60 | 0.260 | -0.540 | 0.999 |
注:为排除随机现象的干扰,43、22个采样点时各抽5组进行实验。 |
表3 土壤有机质含量分级标准Tab. 3 Soil organic matter content grading standard |
| 土壤属性 | 丰富 | 较丰富 | 中等 | 较缺乏 | 缺乏 | 极缺乏 |
|---|---|---|---|---|---|---|
| 有机质/(g/kg) | >40 | 30~40 | 20~30 | 10~20 | 6~10 | < 6 |
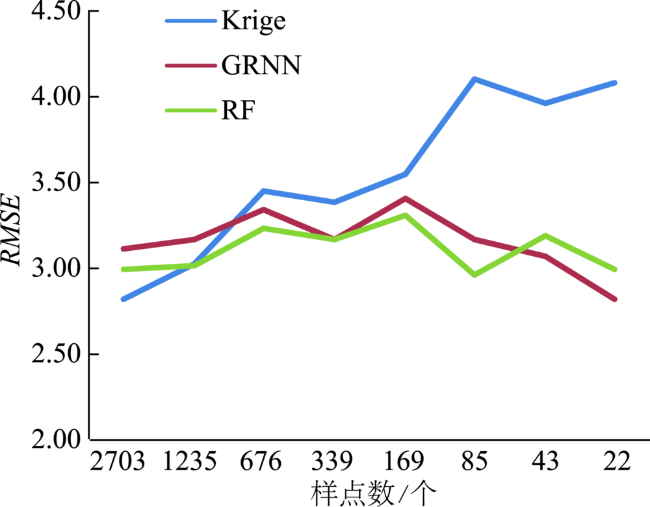
表4 所有实验组GRNN、RF和普通克里格法的预测精度Tab. 4 Prediction accuracy of GRNN, RF and Ordinary Krigingin all experimental groups |
| 实验组 | RMSE | MRE/% | MAE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Krige | GRNN | RF | Krige | GRNN | RF | Krige | GRNN | RF | |||
| D2703 | 2.82 | 3.11 | 2.99 | 26.89 | 29.59 | 28.92 | 2.21 | 2.43 | 2.35 | ||
| D1352 | 3.02 | 3.17 | 3.01 | 29.54 | 30.28 | 29.50 | 3.02 | 2.46 | 2.36 | ||
| D676 | 3.45 | 3.34 | 3.23 | 33.00 | 31.94 | 30.50 | 2.74 | 2.65 | 2.57 | ||
| D339 | 3.38 | 3.17 | 3.17 | 35.60 | 30.64 | 31.19 | 2.82 | 2.47 | 2.53 | ||
| D169 | 3.55 | 3.41 | 3.31 | 35.92 | 36.64 | 34.39 | 2.83 | 2.75 | 2.61 | ||
| D85 | 4.10 | 3.17 | 2.96 | 43.76 | 33.37 | 30.45 | 3.47 | 2.72 | 2.46 | ||
| D43_1 | 3.36 | 2.84 | 2.72 | 30.40 | 25.63 | 23.73 | 2.74 | 2.31 | 2.18 | ||
| D43_2 | 4.13 | 3.19 | 3.11 | 44.58 | 34.52 | 33.70 | 3.34 | 2.70 | 2.65 | ||
| D43_3 | 3.68 | 3.14 | 3.31 | 35.53 | 30.26 | 31.93 | 3.17 | 2.67 | 2.91 | ||
| D43_4 | 3.95 | 2.76 | 3.18 | 44.86 | 33.59 | 37.36 | 3.21 | 2.36 | 2.69 | ||
| D43_5 | 4.69 | 3.42 | 3.61 | 67.44 | 38.46 | 47.36 | 4.06 | 2.70 | 3.01 | ||
| D22_1 | 4.34 | 3.22 | 3.42 | 43.60 | 35.06 | 33.76 | 3.77 | 2.86 | 2.91 | ||
| D22_2 | 4.31 | 2.43 | 2.62 | 65.64 | 24.60 | 26.55 | 3.83 | 2.13 | 2.28 | ||
| D22_3 | 3.90 | 2.89 | 3.07 | 77.11 | 27.63 | 33.04 | 3.54 | 2.27 | 2.64 | ||
| D22_4 | 3.53 | 2.56 | 2.86 | 58.38 | 23.23 | 27.42 | 3.03 | 2.18 | 2.45 | ||
| D22_5 | 4.31 | 2.98 | 2.98 | 146.35 | 35.83 | 41.13 | 3.79 | 2.44 | 2.55 | ||
表5 所有实验组样本的空间自相关分析Tab. 5 Spatial correlation analysis of all experimental groupsamples |
| 实验组 | 平均最短距离/m | Moran's I值 | Z得分 | P值 | 实验组 | 平均最短距离/m | Moran's I值 | Z得分 | P值 |
|---|---|---|---|---|---|---|---|---|---|
| D2703 | 371.45 | 0.35 | 56.78 | 0.00 | D43_3* | 2615.74 | 0.15 | 1.15 | 0.25 |
| D1352 | 425.63 | 0.33 | 30.83 | 0.00 | D43_4* | 3109.01 | 0.15 | 1.30 | 0.19 |
| D676 | 567.68 | 0.33 | 14.99 | 0.00 | D43_5* | 2909.11 | 0.08 | 0.83 | 0.41 |
| D339 | 810.79 | 0.20 | 8.24 | 0.00 | D22_1* | 4237.90 | -0.32 | -1.39 | 0.17 |
| D169 | 1285.91 | 0.17 | 5.68 | 0.00 | D22_2* | 4384.49 | -0.15 | -0.53 | 0.60 |
| D85 | 1914.45 | 0.19 | 3.06 | 0.00 | D22_3* | 3662.95 | -0.10 | -0.19 | 0.85 |
| D43_1 | 2792.95 | 0.22 | 2.41 | 0.02 | D22_4* | 4342.87 | 0.10 | 0.74 | 0.46 |
| D43_2 | 3110.80 | 0.14 | 1.52 | 0.13 | D22_5* | 4723.02 | -0.11 | -0.48 | 0.63 |
注:*表示检验结果为空间自相关性不显著。 |
表6 3种土壤有机质影响因素探测结果Tab. 6 Detected result of three influence factor of soil organic matter |
| 实验组 | 土地利用类型 | 土壤质地 | 畜禽粪便影响强度 | |||||
|---|---|---|---|---|---|---|---|---|
| q值 | p值 | q值 | p值 | q值 | p值 | |||
| D2703 | 0.182 | 0.000 | 0.199 | 0.000 | 0.148 | 0.000 | ||
| D1352 | 0.209 | 0.000 | 0.190 | 0.000 | 0.139 | 0.000 | ||
| D676 | 0.198 | 0.000 | 0.233 | 0.000 | 0.171 | 0.000 | ||
| D339 | 0.212 | 0.000 | 0.189 | 0.000 | 0.138 | 0.000 | ||
| D169 | 0.210 | 0.000 | 0.229 | 0.000 | 0.202 | 0.000 | ||
| D85 | 0.256 | 0.067 | 0.259 | 0.016 | 0.175 | 0.035 | ||
| D43 | 0.500 | 0.004 | 0.177 | 0.071 | 0.345 | 0.050 | ||
| D22 | 0.496 | 0.016 | 0.477 | 0.049 | 0.742 | 0.034 | ||
4.2 GRNN、RF和Ordinary Kriging预测方法的比较 |
表7 GRNN、RF和普通克里格法的预测值与观测值的相关性分析Tab. 7 The correlation analysis between the observed values and predicted values of GRNN, RF and Ordinary Kriging |
| 实验组 | Krige | GRNN | RF | 实验组 | Krige | GRNN | RF |
|---|---|---|---|---|---|---|---|
| D2703 | 0.686** | 0.608** | 0.642** | D43_3 | 0.155 | 0.388* | 0.392** |
| D1352 | 0.635** | 0.590** | 0.637** | D43_4 | 0.153 | 0.669** | 0.576** |
| D676 | 0.543** | 0.581** | 0.616** | D43_5 | -0.067 | 0.591** | 0.577** |
| D339 | 0.450** | 0.580** | 0.578** | D22_1 | -0.137 | 0.572** | 0.590** |
| D169 | 0.433** | 0.500** | 0.545** | D22_2 | -0.343 | 0.709** | 0.630** |
| D85 | 0.175 | 0.599** | 0.660** | D22_3 | -0.094 | 0.584** | 0.440* |
| D43_1 | 0.210 | 0.532** | 0.594** | D22_4 | -0.102 | 0.547** | 0.398* |
| D43_2 | 0.129 | 0.559** | 0.627** | D22_5 | 0.054 | 0.635** | 0.762** |
注:检查手段为Pearson相关系数。*表示在0.05水平(双侧)上显著相关;**表示在0.01水平(双侧)上显著相关。 |
| [1] |
|
| [2] |
徐云鹤, 方斌. 江浙典型茶园土壤有机质空间异质性分析[J]. 地球信息科学学报, 2015,17(5):622-630.
[
|
| [3] |
陈桂香, 高灯州, 曾从盛, 等. 福州市农田土壤养分空间变异特征[J]. 地球信息科学学报, 2017,19(2):216-224.
[
|
| [4] |
|
| [5] |
|
| [6] |
黄昌勇, 徐建明. 土壤学(第三版)[M]. 北京: 中国农业出版社, 2010: 29-43
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
杨晓. 县域土壤有机质空间分布研究——以山东省诸城市为例[D]. 济南:山东农业大学, 2018.
[
|
| [12] |
高凤杰, 马泉来, 韩文文, 等. 黑土丘陵区小流域土壤有机质空间变异及分布格局[J]. 环境科学, 2016,37(5):1915-1922.
[
|
| [13] |
宋莎, 李廷轩, 王永东, 等. 县域农田土壤有机质空间变异及其影响因素分析[J]. 土壤, 2011,43(1):44-49.
[
|
| [14] |
王宗明, 张柏, 宋开山, 等. 东北平原典型农业县农田土壤养分空间分布影响因素分析[J]. 水土保持学报, 2007(2):73-77.
[
|
| [15] |
孔祥斌, 张凤荣, 王茹. 近20年城乡交错带土壤养分时间空间变异特征分析——以北京市大兴区为例[J]. 土壤, 2004(6):636-643.
[
|
| [16] |
秦静, 孔祥斌, 姜广辉, 等. 北京典型边缘区25年来土壤有机质的时空变异特征[J]. 农业工程学报, 2008,24(3):124-129.
[
|
| [17] |
胡克林, 余艳, 张凤荣, 等. 北京郊区土壤有机质含量的时空变异及其影响因素[J]. 中国农业科学, 2006,38(4):764-771.
[
|
| [18] |
赵汝东, 孙焱鑫, 王殿武, 等. 北京地区耕地土壤有机质空间变异分析[J]. 土壤通报, 2010,41(3):552-557.
[
|
| [19] |
李启权, 王昌全, 岳天祥, 等. 基于神经网络模型的中国表层土壤有机质空间分布模拟方法[J]. 地球科学进展, 2012,27(2):175-184.
[
|
| [20] |
李启权, 王昌全, 张文江, 等. 基于神经网络模型和地统计学方法的土壤养分空间分布预测[J]. 应用生态学报, 2013,24(2):459-466.
[
|
| [21] |
江叶枫, 郭熙, 叶英聪, 等. 应用集成BP神经网络模型预测土壤有机质空间分布[J]. 江苏农业学报, 2017,33(5):1044-1050.
[
|
| [22] |
江叶枫, 郭熙. 基于辅助变量和回归径向基函数神经网络(R-R BFNN)的土壤有机质空间分布模拟[J]. 浙江农业学报, 2018,30(4):640-648.
[
|
| [23] |
江叶枫, 郭熙, 叶英聪, 等. 省域尺度土壤有机质空间分布的神经网络法预测[J]. 江苏农业学报, 2017,33(4):828-835.
[
|
| [24] |
|
| [25] |
宋英强, 杨联安, 冯武焕, 等. 基于多源辅助变量和极限学习机的蔬菜地土壤有机质预测研究[J]. 土壤通报, 2017,48(1):118-126.
[
|
| [26] |
|
| [27] |
|
| [28] |
何勇, 张淑娟, 方慧. 基于人工神经网络的田间信息插值方法研究[J]. 农业工程学报, 2004,20(3):120-123.
[
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
侯艺璇, 赵华甫, 吴克宁, 等. 基于BP神经网络的作物Cd含量预测及安全种植分区[J]. 资源科学, 2018,40(12):2414-2424.
[
|
| [35] |
|
| [36] |
GB 9834-88.土壤有机质测定法[S].
[ GB 9834-88. Method for determination of soil organic matter[S]. ]
|
| [37] |
|
| [38] |
|
| [39] |
许信旺. 不同尺度区域农田土壤有机碳分布与变化[D]. 南京:南京农业大学, 2008.
[
|
| [40] |
高凤杰, 吴啸, 师华定, 等. 基于贝叶斯最大熵的黑土区小流域土壤有机质空间预测[J]. 环境科学研究, 2019,32(8):1365-1373.
[
|
| [41] |
GB 18596-2001.畜禽养殖业污染物排放标准[S].
[ GB 18596-2001. Discharge standard of pollutants for livestock and poultry breeding[S]. ]
|
| [42] |
李帷, 李艳霞, 杨明, 等. 北京市畜禽养殖的空间分布特征及其粪便耕地施用的可达性[J]. 自然资源学报, 2010,25(5):746-755.
[
|
| [43] |
任丽, 杨联安, 王辉, 等. 基于随机森林的苹果区土壤有机质空间预测[J]. 干旱区资源与环境, 2018,32(8):141-146.
[
|
| [44] |
沈掌泉, 周斌, 孔繁胜, 等. 应用广义回归神经网络进行土壤空间变异研究[J]. 土壤学报, 2004,41(3):471-475.
[
|
| [45] |
范曼曼, 吴鹏豹, 张欢, 等. 采样密度对土壤有机质空间变异解析的影响[J]. 农业现代化研究, 2016,37(3):594-600.
[
|
| [46] |
姜怀龙, 李贻学, 赵倩倩. 县域土壤有机质空间变异特征及合理采样数的确定[J]. 水土保持通报, 2012,32(4):143-146.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}