
Journal of Geo-information Science >
Water Body Extraction of High Resolution Remote Sensing Image based on Improved U-Net Network
Received date: 2019-10-24
Request revised date: 2020-02-16
Online published: 2020-12-25
Supported by
National Key Research and Development Program of China(2017YFB0503905)
National Natural Science Foundation of China(41971363)
Copyright
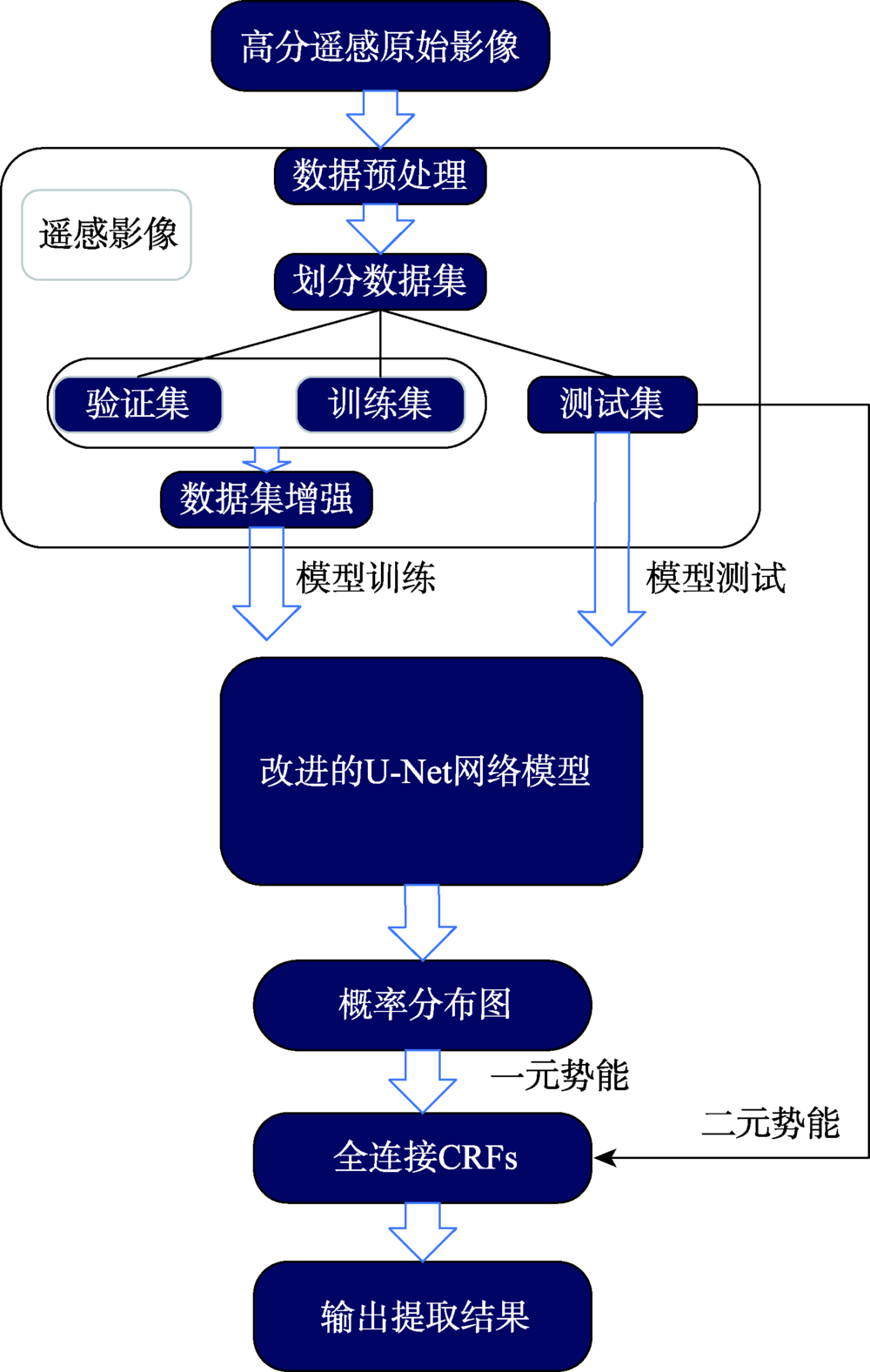
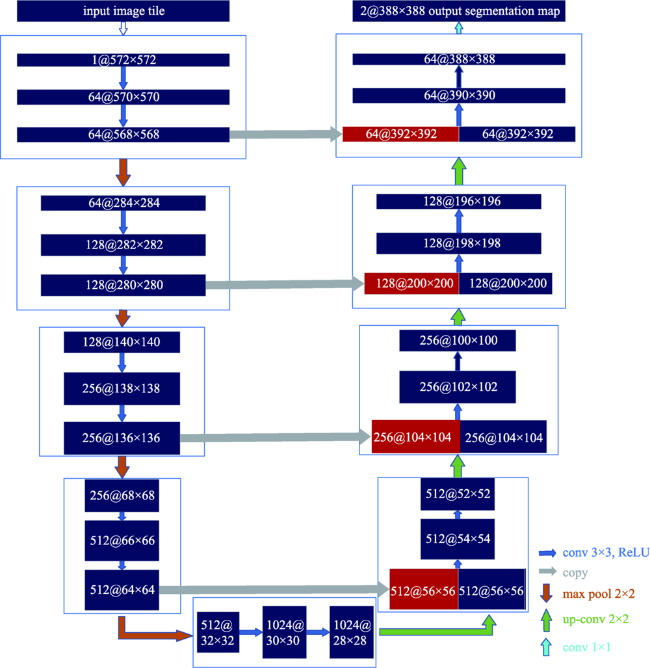
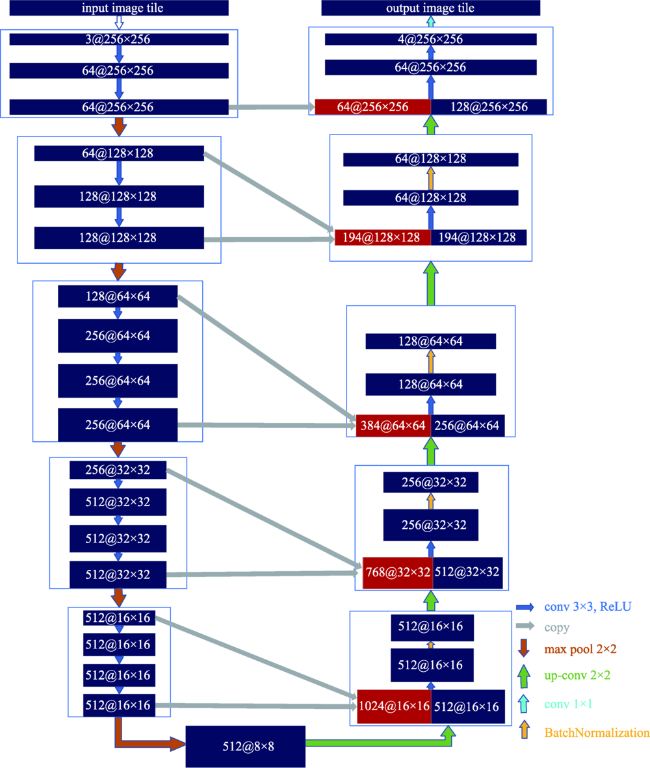
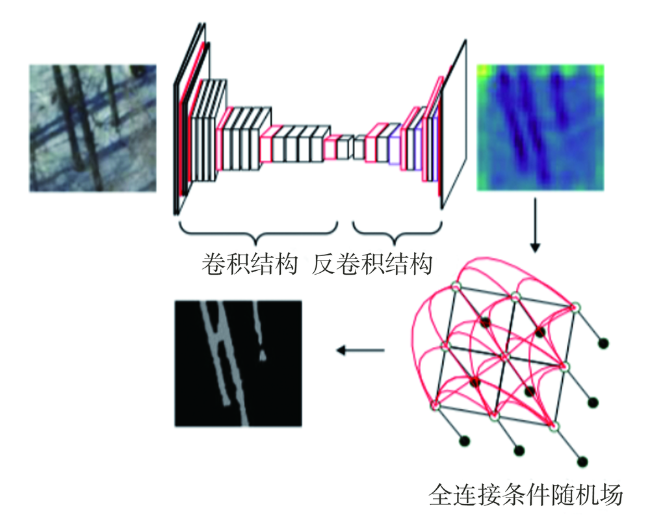
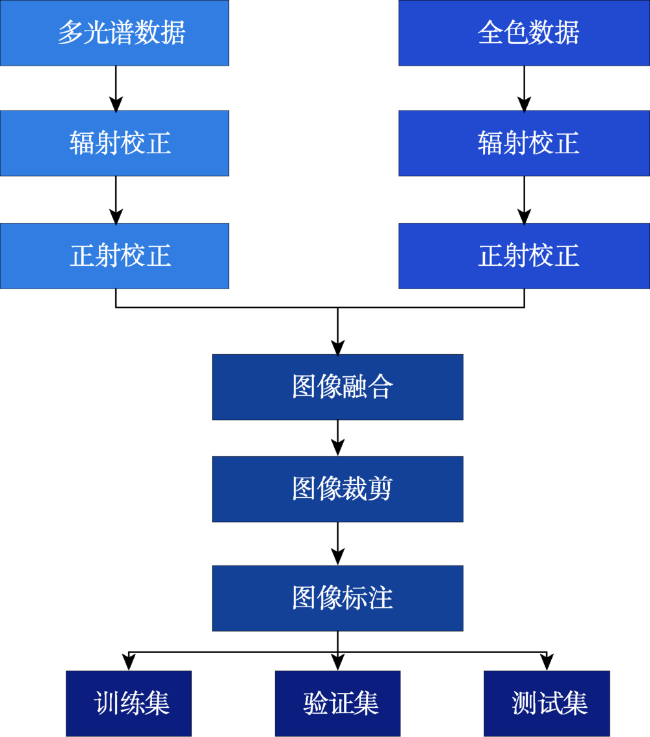
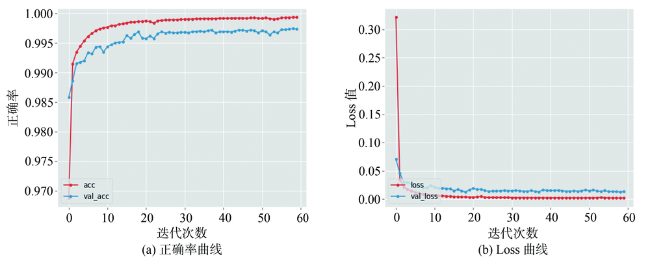
There are two main methods of traditional water body extraction: a method based on spectral information and a method based on classification. Traditional water body extraction methods based on spectral information fail to take into account features such as water body shape, internal texture, water body size, and adjacent relations of water body. Also, there is a common phenomenon of “same object with different spectra and same spectrum with different objects”, which could result in low accuracy of water body extraction. Thus, the traditional methods that design features based on classification to extract water body is complex and impossible to capture the deep information of water body features. This paper proposed an improved U-Net network semantic segmentation method, which uses the de-encoding structure of the classic U-Net network to improve the network: ① Use the VGG network to shrink the path and increase the depth of the network to extract deep features of the water; ② Strengthen the low-dimensional feature information in the expansion path, fuse the feature map on the next layer of the shrinking feature pyramid with the feature map on the corresponding expansion path in the next layer, and enhance the model's low-dimensional feature information to improve the classification accuracy of the model; and ③ The Conditional Random Feld (CRF) was introduced in the post-classification process to refine the segmentation results and improve the segmentation accuracy. In the study of Qingdao area, SegNet, classic U-Net network, and improved U-Net network were selected as controlled experiments while maintaining the same training set, validation set, and test set. The test results show that the improved U-Net network structure performed better than SegNet and classic U-Net networks in terms of IoU, accuracy rate and Kappa coefficient. Compared with SegNet, the three indicators increased by 10.5%, 12.3%, and 0.14, respectively. Compared with the results of the classic U-Net network, each indicator increased by 5.8%, 4.4% and 0.05, respectively. The results demonstrate the effectiveness of the improved method in this paper. In addition, the method proposed in this paper has more advantages than the other two networks in the extraction of small targets in the test area, the completeness of water body extraction, the distinction between shadows and water bodies, and the accuracy of boundary segmentation. In order to verify the space-time scalability of the model, this paper chose western Qingdao and Xining, Qinghai as the verification areas. The verification results show that the water body extraction was good for areas similar to the geographical environment of the experimental area, and the effect of water body extraction needs to be further improved in places that differ greatly from the geographical environment of the experimental area. In general, the improved U-Net network can effectively achieve the task of water extraction.
HE Hongshu , HUANG Xiaoxia , LI Hongga , NI Lingjia , WANG Xinge , CHEN Chong , LIU Ze . Water Body Extraction of High Resolution Remote Sensing Image based on Improved U-Net Network[J]. Journal of Geo-information Science, 2020 , 22(10) : 2010 -2022 . DOI: 10.12082/dqxxkx.2020.190622
表1 VGG16 网络结构配置Tab. 1 VGG16 network structure configuration |
| 感受野 | 步长 | 填充 | 输出大小 | |
|---|---|---|---|---|
| InputRGBimage:3@256×256 | ||||
| Conv+ReLU | 3×3 | 1 | 1 | 64@256×256 |
| Conv+ReLU | 3×3 | 1 | 1 | 64@256×256 |
| Max-pooling | 64@128×128 | |||
| Conv+ReLU | 3×3 | 1 | 1 | 128@128×128 |
| Conv+ReLU | 3×3 | 1 | 1 | 128@128×128 |
| Max-pooling | 128@64×64 | |||
| Conv+ReLU | 3×3 | 1 | 1 | 256@64×64 |
| Conv+ReLU | 3×3 | 1 | 1 | 256@64×64 |
| Conv+ReLU | 3×3 | 1 | 1 | 256@64×64 |
| Max-pooling | 256@32×32 | |||
| Conv+ReLU | 3×3 | 1 | 1 | 512@32×32 |
| Conv+ReLU | 3×3 | 1 | 1 | 512@32×32 |
| Conv+ReLU | 3×3 | 1 | 1 | 512@32×32 |
| Max-pooling | 512@16×16 | |||
| Conv+ReLU | 3×3 | 1 | 1 | 512@16×16 |
| Conv+ReLU | 3×3 | 1 | 1 | 512@16×16 |
| Conv+ReLU | 3×3 | 1 | 1 | 512@16×16 |
| Max-pooling | 512@8×8 | |||
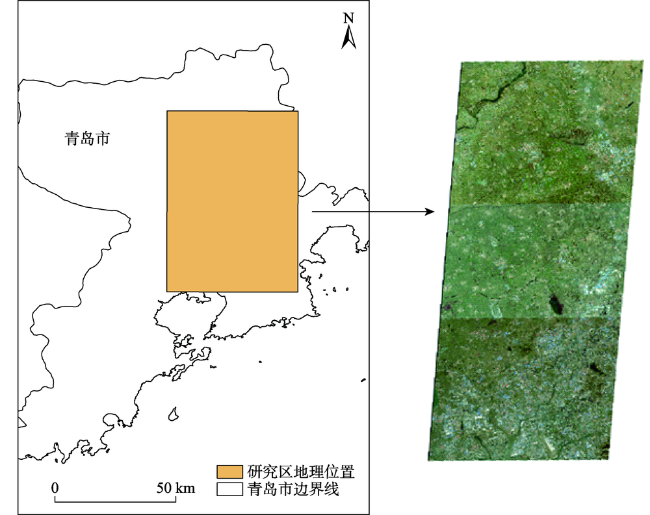
表2 青岛研究区遥感影像信息Tab. 2 RemotesensingimageinformationintheQingdaostudyarea |
| 影像编号 | 中心经度/°E | 中心纬度/°N | 成像时间 | 影像大小/像素×像素 |
|---|---|---|---|---|
| L1A0003593712 | 120.5 | 36.7 | 2018-11-12 | 27 620×35 273 |
| L1A0003593719 | 120.4 | 36.3 | 2018-11-12 | 27 620×35 113 |
| L1A0003593868 | 120.6 | 36.3 | 2018-11-12 | 27 620×35 191 |
表3 基础系统平台配置Tab. 3 Basic system platform configuration |
| 项目 | 系统 | CPU | 内存 | 硬盘 | 显卡 |
|---|---|---|---|---|---|
| 内容 | Ubuntu 16.04 | Intel E5- 1630 | 8 GB | 500 GB | NVIDIA GTX970 |
表4 重要软件配置Tab. 4 Important software configuration |
| 项目 | GPU-Driver | CUDA | Python | Keras | Tensorflow-gpu |
|---|---|---|---|---|---|
| 内容 | 384 | 8.0 | 3.6 | 2.2.4 | 1.4.0 |
表5 研究区5个典型区域不同方法水体提取结果比较Tab. 5 Comparison of water extraction results by different methods in 5 typical areas of the study area |
 |
表6 精度评价混淆矩阵Tab. 6 Confusion matrix for accuracy evaluation |
| 实际正类 | 实际负类 | |
|---|---|---|
| 预测正类 | TP | FP |
| 预测负类 | FN | TN |
表7 水体提取结果精度比较Tab. 7 Accuracy comparison of water extraction results |
| 方法 | IoU/% | 精准率/% | Kappa系数 |
|---|---|---|---|
| SegNet | 77.6 | 82.5 | 0.79 |
| 经典U-net | 82.3 | 90.4 | 0.88 |
| 改进后的U-Net网络 | 88.1 | 94.8 | 0.93 |
表8 应用区遥感影像信息Tab. 8 Remote sensing image information in the application area |
| 影像编号 | 中心经度/°E | 中心纬度/°N | 成像时间 | 影像大小/像素×像素 |
|---|---|---|---|---|
| L1A0003553729 | 120.1 | 36.3 | 2018-10-28 | 276 20×292 00 |
| L1A0003351642 | 101.5 | 36.8 | 2018-07-26 | 276 20×292 00 |
表9 应用区5个典型区域水体提取结果比较Tab. 9 Comparison of water extraction results in 5 typical areas of the application area |
| 区域1 | 区域2 | 区域3 | 区域4 | 区域5 | ||
|---|---|---|---|---|---|---|
| 青岛 | 原始 影像 |  |  |  |  |  |
| 水体 信息 |  | 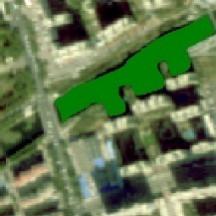 |  |  |  | |
| 西宁 | 原始 影像 |  |  |  |  |  |
| 水体 信息 |  | 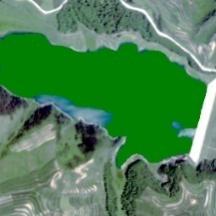 |  | 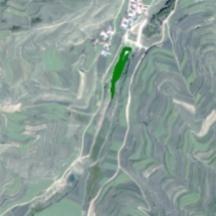 | 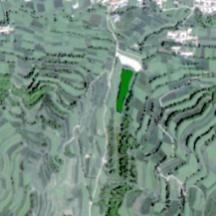 |
注: |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
吴赛, 张秋文. 基于MODIS遥感数据的水体提取方法及模型研究[J]. 计算机与数字工程, 2005(7):1-4.
[
|
| [5] |
李丹, 吴保生, 陈博伟, 等. 基于卫星遥感的水体信息提取研究进展与展望[J]. 清华大学学报(自然科学版), 2020,60(2):147-161.
[
|
| [6] |
|
| [7] |
|
| [8] |
都金康, 黄永胜, 冯学智, 等. SPOT卫星影像的水体提取方法及分类研究[J]. 遥感学报, 2001,5(3):214-219.
[
|
| [9] |
王培培. 基于ETM影像的水体信息自动提取与分类研究[J]. 首都师范大学学报(自然科学版), 2009,30(6):75-79.
[
|
| [10] |
胡德勇, 李京, 陈云浩, 等. 单波段单极化SAR图像水体和居民地信息提取方法研究[J]. 中国图象图形学报, 2008,13(2):257-263.
[
|
| [11] |
|
| [12] |
计梦予, 袭肖明, 于治楼. 基于深度学习的语义分割方法综述[J]. 信息技术与信息化, 2017(10):137-140.
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
许玥. 基于改进Unet的遥感影像语义分割在地表水体变迁中的应用[D]. 重庆:重庆师范大学, 2019.
[
|
| [19] |
陈前, 郑利娟, 李小娟, 等. 基于深度学习的高分遥感影像水体提取模型研究[J]. 地理与地理信息科学, 2019,35(4):43-49.
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
刘懿兰, 黄晓霞, 李红旮, 等. 基于卷积神经网络与条件随机场方法提取乡镇非正规固体废弃物[J]. 地球信息科学学报, 2019,21(2):259-268.
[
|
| [26] |
黄英来, 刘亚檀, 任洪娥. 基于全卷积神经网络的林木图像分割[J]. 计算机工程与应用, 2019,55(4):219-224.
[
|
| [27] |
王晨巍, 王晓君. 高分遥感卫星影像的预处理技术[J]. 电子技术与软件工程, 2016(24):122-123.
[
|
| [28] |
张新明, 祝晓斌, 蔡强, 等. 图像语义分割深度学习模型综述[J]. 高技术通讯, 2017,27(Z1):808-815.
[
|
/
| 〈 |
|
〉 |

 表示提取水体。
表示提取水体。{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}