
Journal of Geo-information Science >
Personalized Recommendation Method of Thematic Map Products based on Item2Vec with Negative Sampling Optimization
Received date: 2019-11-07
Request revised date: 2020-01-10
Online published: 2021-01-25
Supported by
LZJTU EP(201806)
China Knowledge Center for Engineering Sciences and Technology-Water Conservancy Professional Knowledge Service System(CKCEST-2019-1-6)
Copyright
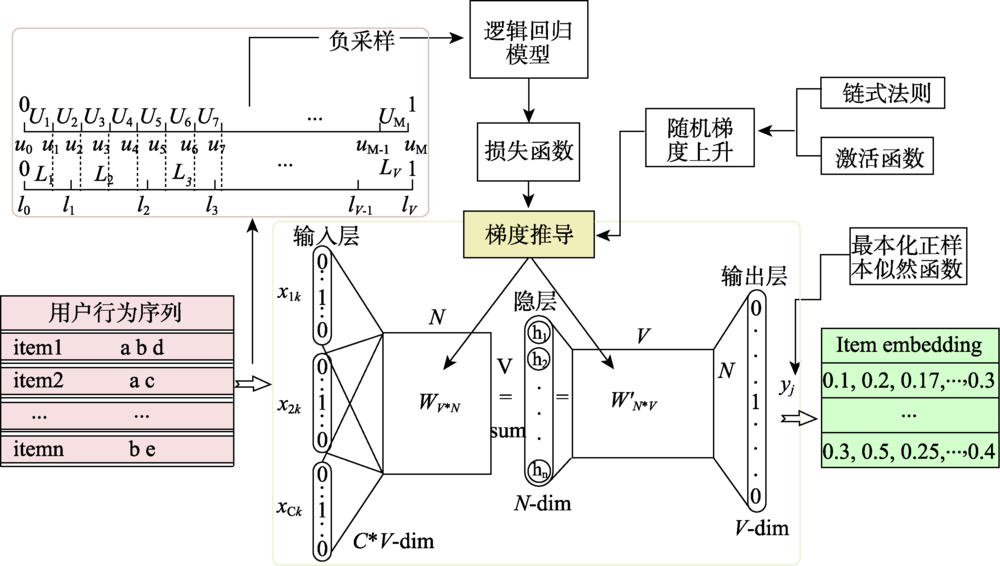
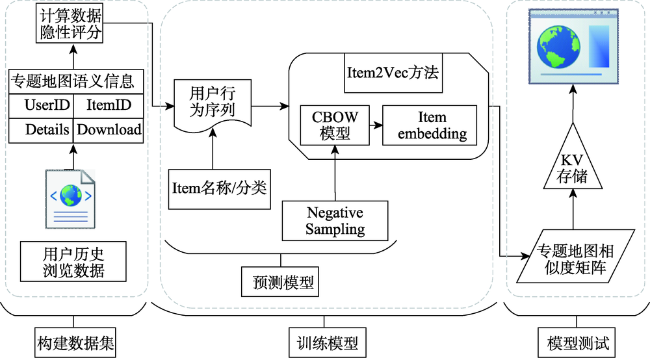
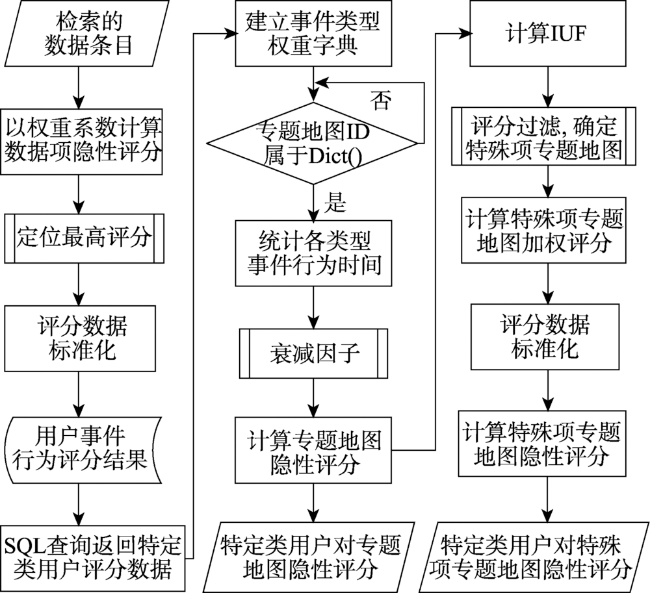
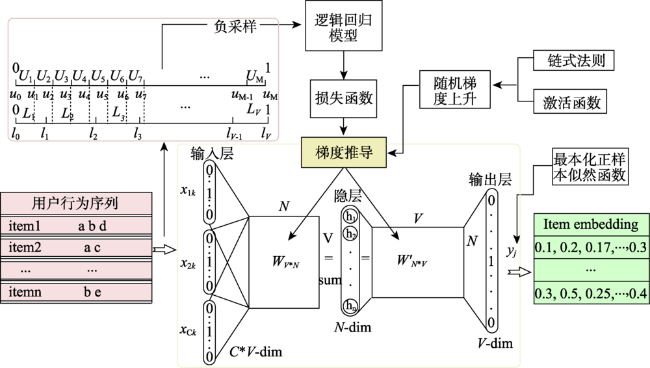
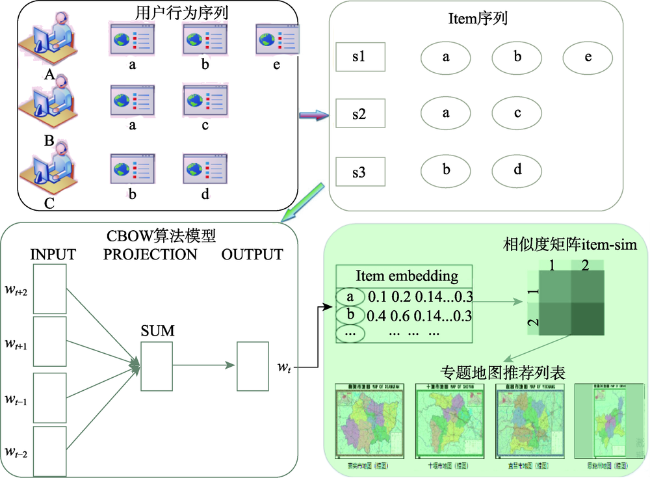
Establishing a user preference recommendation model suitable for thematic map product search is one of the effective ways to improve the quality of the thematic map products. In the thematic map product recommendation scenario, there are serious problems of content cold-start and sparse comment data. The existing recommendation algorithms cannot recommend thematic map products with different features for specific types of users, resulting in users' limited preference for obtaining preference information from the thematic maps. Hence, this paper presents a user preference recommendation method based on the combination of CBOW with Negative Sampling and Iten2Vec based on Word2Vec. Firstly, calculating implicit ratings of the interaction behavior data in the user behavior log, to replace sparse user ratings in thematic disaster scenarios; Secondly, extracting context-aware feature information of central thematic map based on CBOW model with Negative Sampling. By controlling the ratio of positive and negative samples to 1:2, the prediction accuracy of the potential score of the target thematic map is improved; Finally, mapping Thematic CMaps with user behavior characteristics information to vector space via Item2Vec, calculating the user's similarity matrix to the thematic map and completing recommendations based on user preference. Test results on thematic map scoring experiment dataset Thematic CMaps and four validation dataset MovieLens show that, compared with the four traditional recommendation algorithm of LFM, Personal Rank, Content Based, and SVD, this proposed method can effectively improve the precision potential scoring, and the highest recommending performance is 27.85%. Compared with Item2Vec with Huffman sampling method and YouTubeNet two neural network recommendation algorithms, the score prediction accuracy has improved to a certain extent, and the recommendation performance has been continuously improved, reaching the maximums of 2.97% and 5.78%. Taking the singular value decomposition (SVD) of the classic algorithm as an example, in the increasing data subset after the segmentation of MovieLens-20M dataset, the score prediction accuracy and performance of the method used in this paper are better than SVD method.
MAO Wenshan , ZHAO Hongli , SUN Fengjiao , JIANG Yunzhong , JIANG Qian , ZHU Yanru . Personalized Recommendation Method of Thematic Map Products based on Item2Vec with Negative Sampling Optimization[J]. Journal of Geo-information Science, 2020 , 22(11) : 2128 -2139 . DOI: 10.12082/dqxxkx.2020.190668
表1 用于计算专题地图隐性评分的数据格式Tab. 1 Data format used to calculate thematic map implicit ratings |
| 用户ID | 内容ID | 事件行为次数 | 浏览时间/s | |||
|---|---|---|---|---|---|---|
| 浏览行为 | 描述性行为 | 属性行为 | 决定性行为 | |||
| 1494590 | 60287 | 1 | 1 | 3 | 1 | 83 |
表2 用户事件行为权重分配Tab. 2 Weights assignment of user event behavior |
| 事件行为 | 释义 | 权重分配 |
|---|---|---|
| 浏览行为 | 次级评分 | 50 > (w3×1) |
| 描述性行为 | 中等评分 | 50 < (w3×3) |
| 属性行为 | 积极评分 | 80 < (w2×1) + (w3×3) |
| 决定性行为 | 最高评分 | 100 = (w1*1) |
表4 模型训练参数设置Tab. 4 Parameter settings in this article model |
| 参数 | 释义 | Thematic CMaps | MovieLens-100K/ MovieLens-1M | MovieLens-10M | MovieLens-20M |
|---|---|---|---|---|---|
| size | item向量维度 | 5 | 20/100 | 128 | 250 |
| window | 上下文窗口长度 | 3 | 3/4 | 6 | 8 |
| negative | 负采样个数 | 32 | 64/64 | 128 | 256 |
| sg/hs | 训练模式/采样模式 | 0/0 | 0/0 | 0/0 | 0/0 |
| min_count | item向量最小频次 | 3 | 4/5 | 6 | 8 |
| iter | 训练迭代次数 | 5 | 5/50 | 100 | 200 |
| alpha | 迭代学习率 | 0.025 | 0.025 | 0.050 | 0.050 |
表5 各模型预测评分性能对比Tab. 5 Comparison of prediction score performance on each model |
| 模型 | Thematic CMaps | MovieLens-100K | MovieLens-1M | MovieLens-10M | MovieLens-20M |
|---|---|---|---|---|---|
| LFM | 1.338 | 1.221 | 1.196 | 1.169 | 1.130 |
| Personal Rank | 1.324 | 1.212 | 1.183 | 1.176 | 1.122 |
| Content Based | 1.297 | 1.194 | 1.087 | 1.007 | 0.914 |
| SVD | 1.135 | 0.938 | 0.906 | 0.886 | 0.850 |
| YouTubeNet | 1.129 | 0.923 | 0.885 | 0.872 | 0.831 |
| Item2Vec(霍夫曼) | 1.123 | 0.917 | 0.881 | 0.851 | 0.807 |
| Item2Vec(负采样) | 1.118 | 0.912 | 0.875 | 0.835 | 0.783 |
表6 模型在MovieLens-20M数据集切分下的实验结果Tab. 6 Experimental results of the model under the MovieLens-10M dataset segmentation |
| 模型 | 10% | 30% | 50% | 70% | 90% |
|---|---|---|---|---|---|
| SVD | 0.904 | 0.894 | 0.886 | 0.878 | 0.870 |
| Item2Vec(负采样) | 0.867 | 0.854 | 0.835 | 0.814 | 0.787 |
表7 2种模型的推荐结果对比Tab. 7 Two recommended results comparison between Item2Vec (Negative Sampling) and SVD |
| 种子专题地图 | Item2Vec(负采样)—Top5 | SVD—Top5 |
|---|---|---|
| 107国道线路 地图——交通 地图|国道 线路图 | 109国道线路地图——交通地图|国道线路图 | 全国国道线路图——交通地图|国道线路图 |
| 全国国道线路图——交通地图|国道线路图 | 102国道线路地图——交通地图|国道线路图 | |
| 全国国道分布图——交通地图|国道线路图 | 104国道线路地图——交通地图|国道线路图 | |
| 102国道线路地图——交通地图|国道线路图 | 318国道全程示意图——交通地图|国道线路图 | |
| 318国道全程示意图——交通地图|国道线路图 | 317国道线路地图——交通地图|国道线路图 | |
| 四川省宜宾市 泸州市交通 地图——交通 地图|公路地图集 | 四川省雅安市阿垻州交通地图——交通地图|公路地图集 | 宁夏交通地图全图——交通地图|公路地图集 |
| 四川省眉山市乐山市交通地图——交通地图|公路地图集 | 四川省眉山市乐山市交通地图——交通地图|公路地图集 | |
| 四川省交通地图全图——交通地图|公路地图集 | 四川省交通地图全图——交通地图|公路地图集 | |
| 四川省成都市交通地图——交通地图|公路地图集 | 湖南省长沙株洲衡阳怀化交通地图——交通地图|公路 地图集 | |
| 四川南充德阳达州自贡内江交通地图——交通地图|公路 地图集 | 四川高速公路地图2017版——交通地图|高速公路网 | |
| 四川高速公路 地图2017版— 交通地图|高速 公路网 | 四川18条高速公路线路规划图2017——交通地图|高速公 路网 | 四川省收费公路主线站点分布图——交通地图|高速公路网 |
| 云南高速公路地图2017版——交通地图|高速公路网 | 国家高速公路网线路图——交通地图|高速线路图 | |
| 国家高速公路网规划方案图——交通地图|高速公路网 | 国家高速公路网布局——交通地图|高速线路图 | |
| 国家高速公路网线路图——交通地图|高速线路图 | 四川18条高速公路线路规划图2017——交通地图|高速 公路网 | |
| 甘肃高速公路地图2017版——交通地图|高速公路网 | 云南高速公路地图2017版——交通地图|高速公路网 |
| [1] |
|
| [2] |
郑束蕾, 陈毓芬, 杨春雷, 等. 地图个性化认知适合度的眼动试验评估[J]. 测绘学报, 2015,44(s1):27-35.
[
|
| [3] |
方潇, 李萌, 包芃, 等. 基于眼动实验的个性化地图推荐模型探讨[J]. 地理空间信息, 2015,13(1):167-170.
[
|
| [4] |
冯天文, 李轶鲲, 刘涛, 等. 语义扩散检索方法研究——以火灾应急图组库为例[J]. 测绘科学, 2018,43(12):115-121.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
姜波, 张晓筱, 潘伟丰. 基于二部图的服务推荐算法研究[J]. 华中科技大学学报(自然科学版), 2013,41(s2):93-99.
[
|
| [9] |
黄立威, 江碧涛, 吕守业, 等. 基于深度学习的推荐系统研究综述[J]. 计算机学报, 2018,427(7):191-219.
[
|
| [10] |
吴彦文, 刘闯. 基于用户偏好和可疑度的推荐方法研究[J]. 计算机应用研究, 2018,35(12):118-120.
[
|
| [11] |
|
| [12] |
陈晋音, 吴洋洋, 林翔. 基于图过滤的快速密度聚类双层网络推荐算法[J]. 控制理论与应用, 2019,36(4):542-552.
[
|
| [13] |
黄金超, 张佳伟, 陈宁, 等. 基于偏好度特征构造的个性化推荐算法[J]. 上海交通大学学报, 2018,52(7):770-776.
[
|
| [14] |
张敏, 丁弼原, 马为之, 等. 基于深度学习加强的混合推荐方法[J]. 清华大学学报(自然科学版), 2017,57(10):1014-1021.
[
|
| [15] |
陈冬林, 聂规划, 刘平峰. 基于网页语义相似性的商品隐性评分算法[J]. 系统工程理论与实践, 2006,26(11):98-102.
[
|
| [16] |
|
| [17] |
刘淑涵, 王艳东, 付小康. 利用卷积神经网络提取微博中的暴雨灾害信息[J]. 地球信息科学学报, 2019,21(7):1009-1017.
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}