
Journal of Geo-information Science >
Research on User Spatial Access Aggregation Behavior in Network Geographic Information Service
Received date: 2020-07-31
Revised date: 2020-09-30
Online published: 2021-03-25
Supported by
National Key Research and Development Foundation of China(2016YFB0502301)
National Natural Science Foundation of China(41771426)
Copyright
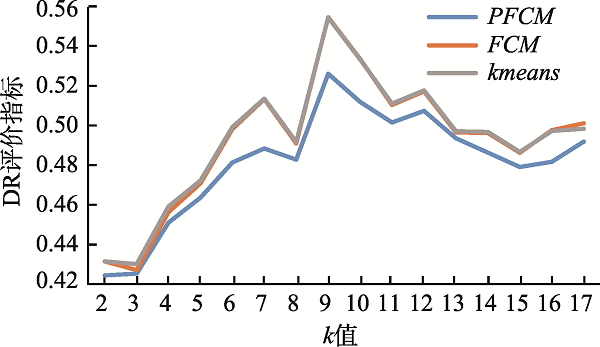
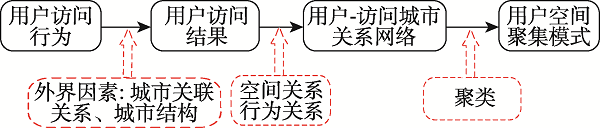
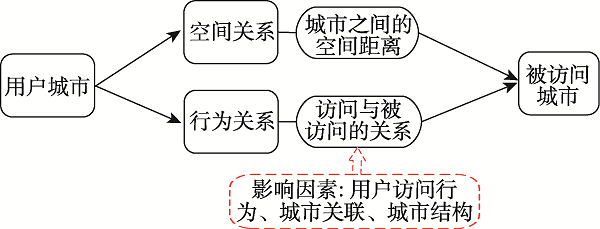
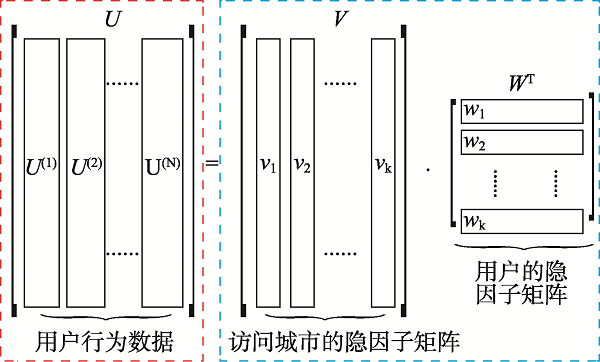
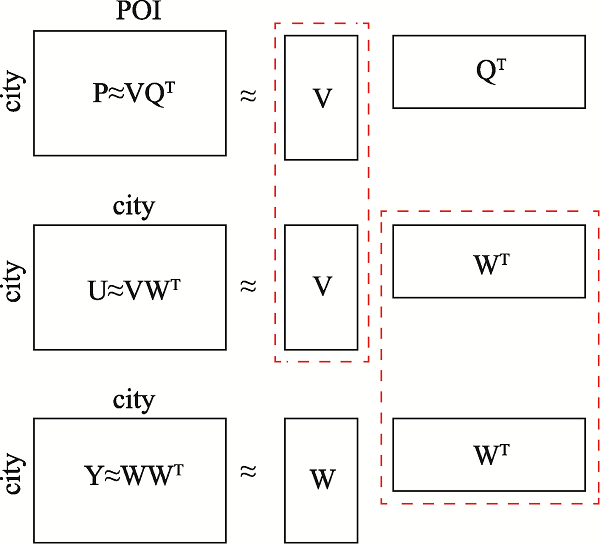
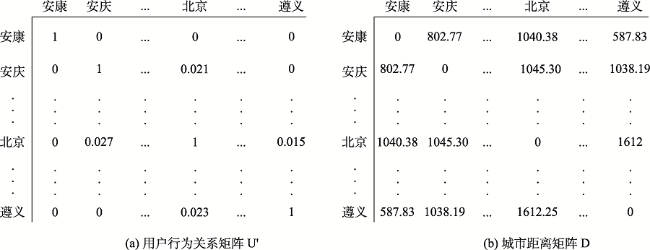
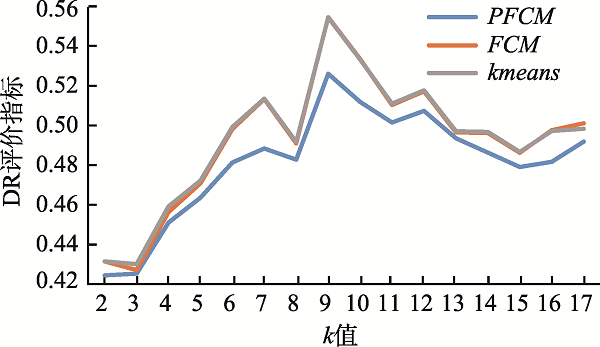
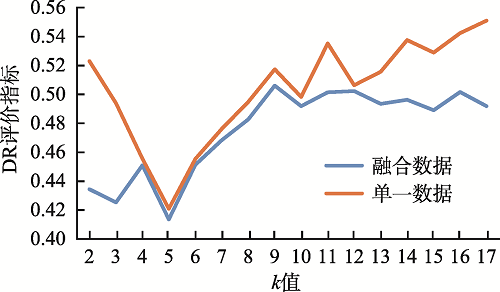
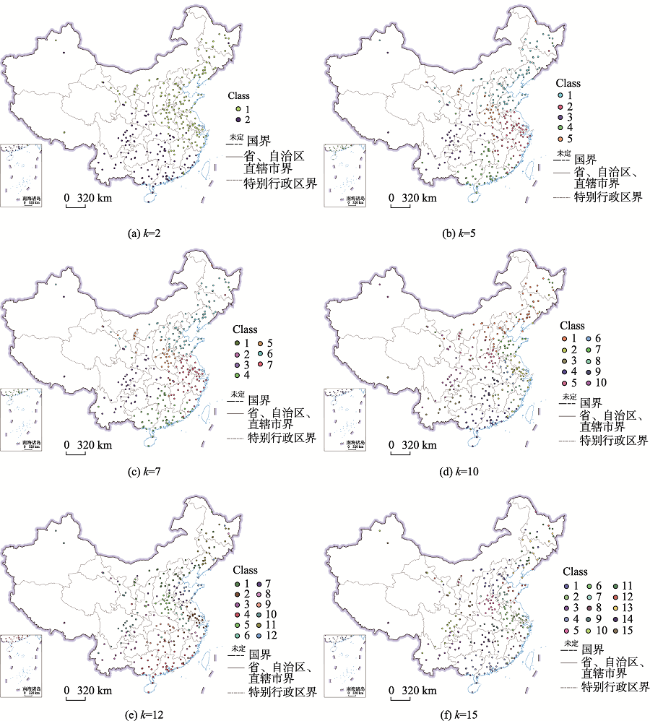
The rapid development of the geographic information industry has promoted the popularization of network geographic information services, providing the public with indispensable and convenient services such as spatial positioning, spatial query, and path planning, which penetrate all aspects of life. At the same time, the number of users is also exploding, how to provide users with on-demand and high-quality geographic information services has become one of the key issues to be solved. So it is meaningful to study the access behavior of users of network geographic information services, which is conducive to understanding users' geographic information interests and realizing on-demand services. Based on the theory of full spatial information system modeling, this paper constructs a user-visited city relationship network and studies the spatial aggregation of user access. Users' behavioral relationship strength generally involves many factors. This paper takes into account that the expression of behavioral relationship strength in relational network needs to consider user access behavior, city association relationship, and city structure at the same time, and there will be bias on a single user accesses behavior data. In order to solve this bias, this paper proposes a data fusion method based on matrix decomposition to integrate user access data, city associated data, and Point of Interest (POI) data in network geographic information services to express the strength of user-city access correlation. In the relational network, the fusion data are used to express the strength of behavioral relationship, and the distance between cities is used to express the strength of spatial relationship. On this basis, the clustering pattern mining of users is realized based on the relational network clustering method. The characteristics of users' preference to different cities will affect the clustering results. Given that clustering methods are usually based on spatial distance to achieve clustering, they cannot take into account the user's preference characteristics of different cities in the relationship network. On the basis of Fuzzy C-means Clustering algorithm (FCM), this paper proposes the PFCM algorithm based on the user's access probability to the city definition of access preference. At the same time, the spatial distance between cities and the strength of access behavior relationship in the relational network are taken into account to reduce the deviation of clustering results. This research expresses the spatial interest preferences of users through the spatial clustering of user visits. It helps to understand the relationship between user access behavior and cities and provides guidance for the performance improvement of network geographic information services in data caching and advance push so as to better serve user access.
CHEN Wenjing , LI Rui , DONG Guangsheng , LI Jiang . Research on User Spatial Access Aggregation Behavior in Network Geographic Information Service[J]. Journal of Geo-information Science, 2021 , 23(1) : 93 -103 . DOI: 10.12082/dqxxkx.2021.200424
| 算法1 PFCM聚类算法 |
|---|
| 输入: |
| 用户行为矩阵 |
| 城市中心位置经纬度 |
| 输出:隶属度矩阵 |
| 1.用之间的值随机初始化隶属度矩阵, 使其满足(2)式的约束 2.选取聚类中心 3. 4. 5. 6. |
| 算法2 数据融合过程: 用户与城市的行为关系强度计算 |
|---|
| 输入: |
| :用户行为矩阵 |
| :城市关联矩阵 :城市结构矩阵 |
| 输出: :用户与城市的行为关系强度 |
| 1.随机初始化,,;梯度下降速率;迭代次数;误差阈值 2. 3. 4. ,, 5. 6. 7. 8. 9. 10. 11. 12. |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
吴华意, 李锐, 周振 , 等. 公共地图服务的群体用户访问行为时序特征模型及预测[J]. 武汉大学学报·信息科学版, 2015,40(10):1279-1286.
[
|
| [6] |
李锐, 沈雨奇, 蒋捷 , 等. 公共地图服务中访问热点区域的时空规律挖掘[J]. 武汉大学学报·信息科学版, 2018,43(9):1408-1415.
[
|
| [7] |
王末, 王卷乐, 赫运涛 . 地学数据共享网用户Web行为预测及数据推荐方法[J]. 地球信息科学学报, 2017,19(5):595-604.
[
|
| [8] |
冯秋燕 . 基于Web应用的日志异常检测与用户行为分析研究[D]. 广州:华南理工大学, 2019.
[
|
| [9] |
张林兵, 郭强, 吴行斌 , 等. 基于多维行为分析的用户聚类方法研究[J]. 电子科技大学学报, 2020,49(2):315-320.
[
|
| [10] |
周成虎 . 全空间地理信息系统展望[J]. 地理科学进展, 2015,34(2):129-131.
[
|
| [11] |
华一新, 周成虎 . 面向全空间信息系统的多粒度时空对象数据模型描述框架[J]. 地球信息科学学报, 2017,19(9):1142-1149.
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
谢娟英, 周颖, 王明钊 , 等. 聚类有效性评价新指标[J]. 智能系统学报, 2017,12(6):873-882.
[
|
| [16] |
胡定利, 李锐, 孟瑶 , 等. 新闻地名共现视角下的中国城市网络[J]. 武汉大学学报·信息科学版, 2020,45(2):281-288.
[
|
| [17] |
池娇, 焦利民, 董婷 , 等. 基于POI数据的城市功能区定量识别及其可视化[J]. 测绘地理信息, 2016,41(2):68-73.
[
|
| [18] |
赵卫锋, 李清泉, 李必军 . 利用城市POI数据提取分层地标[J]. 遥感学报, 2011,15(5):973-988.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}