
Journal of Geo-information Science >
Research on Public Opinion Analysis Methods in Major Public Health Events: Take COVID-19 Epidemic as an Example
Received date: 2020-05-07
Revised date: 2020-07-20
Online published: 2021-04-25
Supported by
National Key R&D Program of China(2018YFC1508901-3)
Copyright
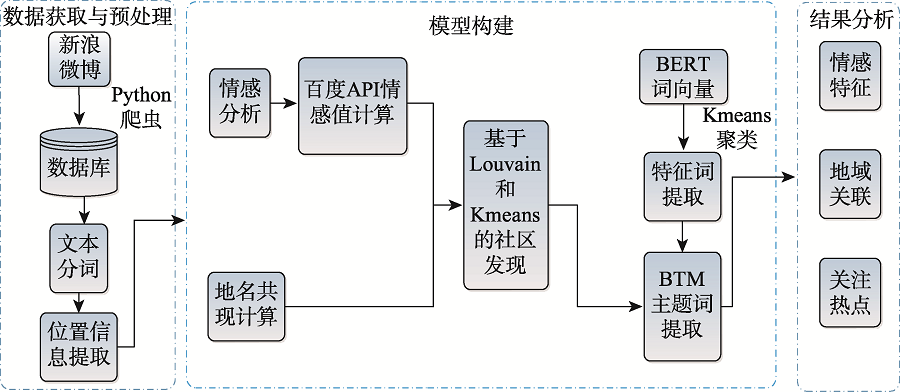
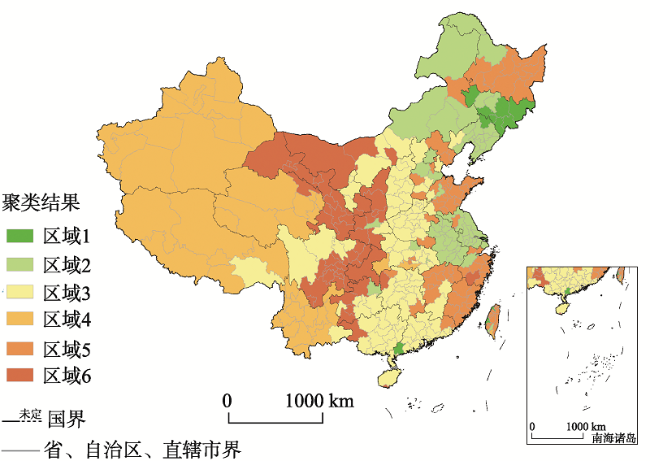
Since December 2019, COVID-19 has rapidly swept the world. As of May 10, 2020, 16:40 PM, Beijing time, the global confirmed COVID-19 cases reached 4,115,662, which has become a major global issue. Social media platforms such as microblog have become the important channel for information transmission and an effective sensor of public sentiment. In-depth mining and analysis of microblog information can not only characterize the public opinion, but also help the government to conduct targeted guidance on public sentiment and properly control public opinion. Therefore, this study collected more than 330,000 Sina Weibo data about COVID-19 from January 18, 2020 to January 28, 2020. Based on the spatial clustering method using Louvain and K-means and an improved BTM subject word extraction algorithm, users' attention information and emotional characteristics are labeled with their locations. Thus, the evaluation method of public opinion is constructed by integrating user's location information, which is able to analyze the characteristics of public opinion and the difference in the topics concerned at different regions. Our results show that the characteristics of public opinion in different regions can be comprehensively evaluated using the spatial clustering method based on Louwain and K-mean. The BTM subject word extraction method based on BERT word vector can effectively make up the disadvantages of traditional subject word extraction methods that need large computation and have data redundancy, and thus has stronger expression ability in user data mining. The hot topics concerned in different regions have certain differences. The public opinion analysis method proposed in this paper can effectively reflect the public opinion characteristics of different regions and provide reference for the public opinion analysis of major public health events.
HAN Keke , XING Ziyao , LIU Zhe , LIU Junming , ZHANG Xiaodong . Research on Public Opinion Analysis Methods in Major Public Health Events: Take COVID-19 Epidemic as an Example[J]. Journal of Geo-information Science, 2021 , 23(2) : 331 -340 . DOI: 10.12082/dqxxkx.2021.200226
表1 原始BTM与改进后的BTM主题提取结果对比Tab. 1 Comparison of results between the original BTM and the improved BTM theme extraction results |
| 编号 | 原始BTM主题提取结果 | 基于BERT词向量改进后的BTM主题提取结果 | ||
|---|---|---|---|---|
| 主题 | 关键词 | 主题 | 关键词 | |
| 1 | 确诊病例相关 | 武汉;说;没有;全国;确诊;真的;病例;现在 | 确诊病例相关 | 武汉;知道;全国;确诊;病例;想;没有;现在 |
| 2 | 口罩相关 | 口罩;戴;武汉;说;确诊;病例;出门 | 口罩 | 口罩;戴;买;出门;去;大家;出来;严重 |
| 3 | 医院物资缺乏 | 武汉;医院;确诊;病例; 医生;物资;全国;没有 | 医院物资缺乏 | 医院;医生;医护人员;没有;物资;现在;发热 |
| 4 | 医院物资缺乏二 | 物资;全国;没有;医院;现在;武汉;没;号;今天 | 野味相关 | 野味;吃;气死我了;大家;希望;重视;隔离;相信 |
| 5 | 野味相关 | 吃;野味;确诊;病例;全国;武汉;气死我了;野生动物 | 封城相关 | 武汉;口罩;封城;想;政府;人民;超市;戴上 |
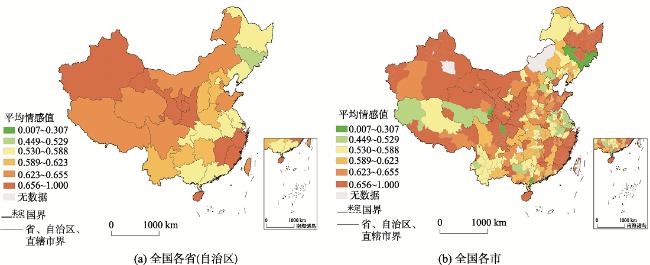
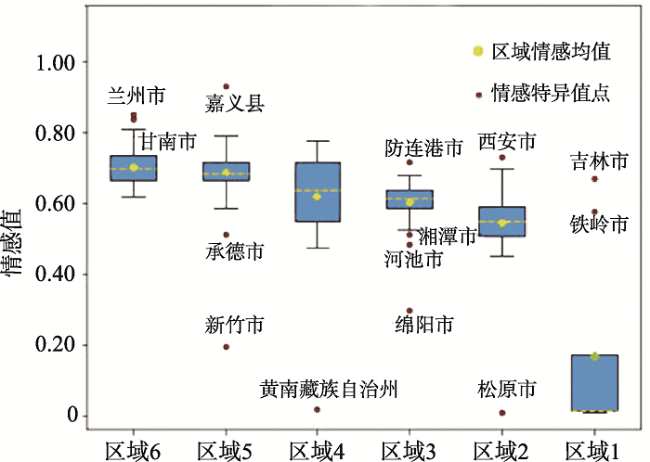
图2 全国各省(自治区)、各市新冠肺炎早期相关微博情感均值分布注:该图基于自然资源部标准地图服务网站下载的审图号为GS(2019)1702号的标准地图制作,底图无修改。 Fig. 2 The mean distribution of COVID-19 related emotions in early microblogs by province and city in China |
| [1] |
汪明艳, 余丽彬, 朱译冰. 舆论反转中群体极化效应的影响因素研究[J]. 情报杂志, 2018(9):106-112,119.
[
|
| [2] |
邵真如. 技术赋权视域下的90后大学生网络舆情研究:挑战与应对[J]. 课程教育研究, 2018(12):175.
[
|
| [3] |
丁学君, 樊荣, 杨锦仪. 突发公共卫生事件网络舆情研究现状及评述[J]. 电子政务, 2017(6):47-56.
[
|
| [4] |
|
| [5] |
|
| [6] |
齐珉, 齐文华, 苏桂武. 基于新浪微博的2017年四川九寨沟7.0级地震舆情情感分析[J]. 华北地震科学, 2020,38(1):57-63.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
林萍, 黄卫东. 基于LDA模型的网络舆情事件话题演化分析[J]. 情报杂志, 2013,32(12):26-30.
[
|
| [11] |
|
| [12] |
谈成访, 汪材印, 张亚康. 基于LDA模型的中文微博热点话题发现[J]. 宿州学院学报, 2014,29(4):71-73,77.
[
|
| [13] |
|
| [14] |
|
| [15] |
余淼淼, 周志平, 赵晓东, 等. 基于PAM概率主题模型的微博热点挖掘[J]. 微型机与应用, 2013,32(15):86-89.
[
|
| [16] |
王亚民, 胡悦. 基于BTM的微博舆情热点发现[J]. 情报杂志, 2016,35(11):119-124,140.
[
|
| [17] |
苏凯, 程昌秀,
[
|
| [18] |
张岩, 李英冰, 郑翔. 基于微博数据的台风“山竹”舆情演化时空分析[J/OL]. 山东大学学报(工学版): 1-9[2020-04-10].
[
|
| [19] |
陈兴蜀, 常天祐, 王海舟, 等. 基于微博数据的“新冠肺炎疫情”舆情演化时空分析[J]. 四川大学学报(自然科学版), 2020,57(2):409-416.
[
|
| [20] |
Alves,
|
| [21] |
|
| [22] |
胡赫薇, 冯晓曦. 基于Bi-LSTM的财金文本情感分类研究[J]. 电脑与信息技术, 2020,28(2):35-37.
[
|
| [23] |
|
| [24] |
袁和金, 张旭, 牛为华, 等. 融合注意力机制的多通道卷积与双向GRU模型的文本情感分析研究[J]. 中文信息学报, 2019,33(10):109.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}