
Journal of Geo-information Science >
Research on the Characteristics of Rainfall Events and Rain Pattern Zoning in Hebei based on Data Mining Technology
Received date: 2020-07-03
Request revised date: 2020-09-18
Online published: 2021-07-25
Supported by
National Key R&D Program of China(2017YFC1502505)
Copyright
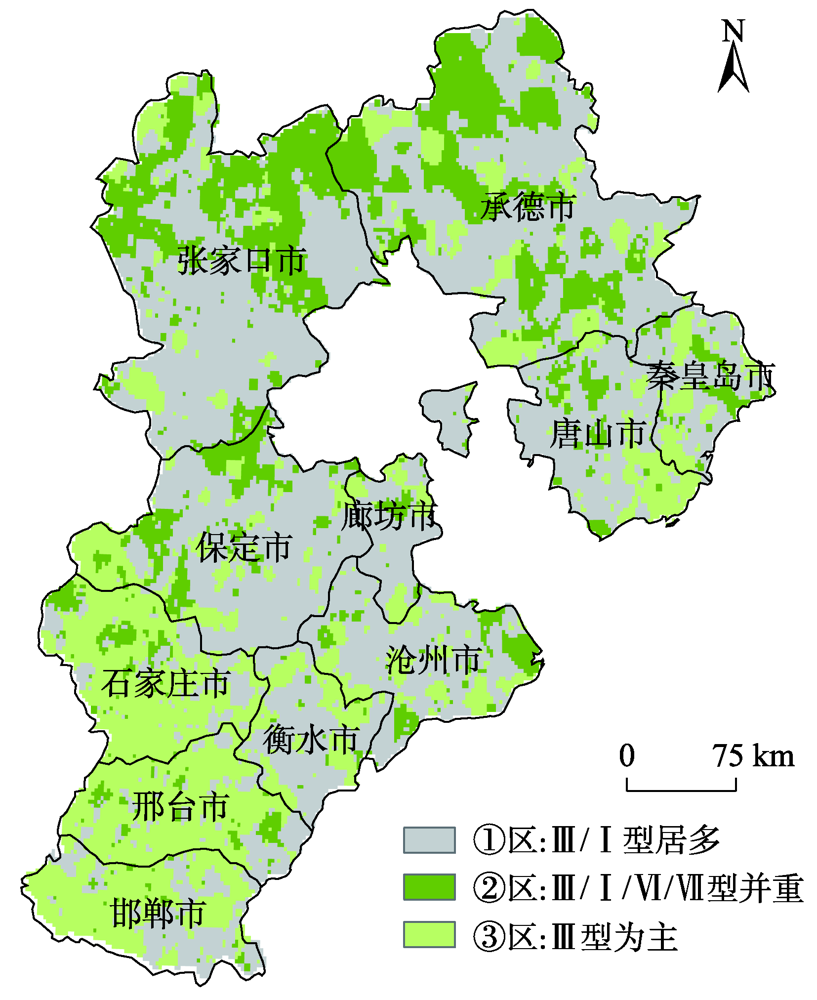
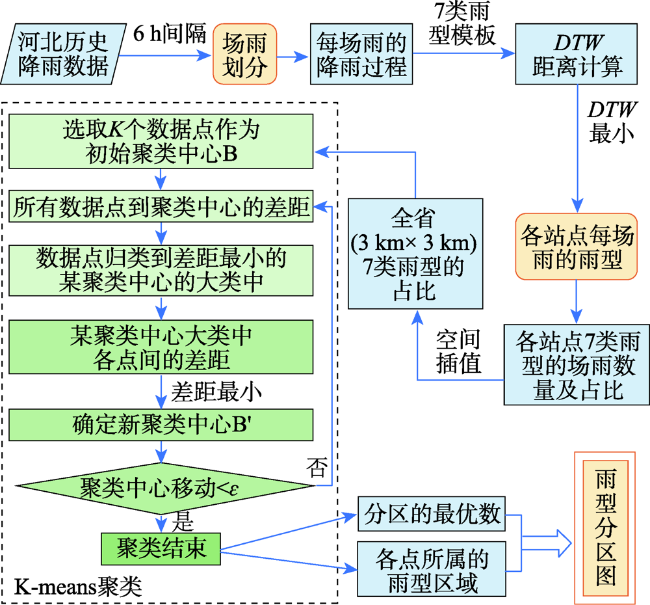
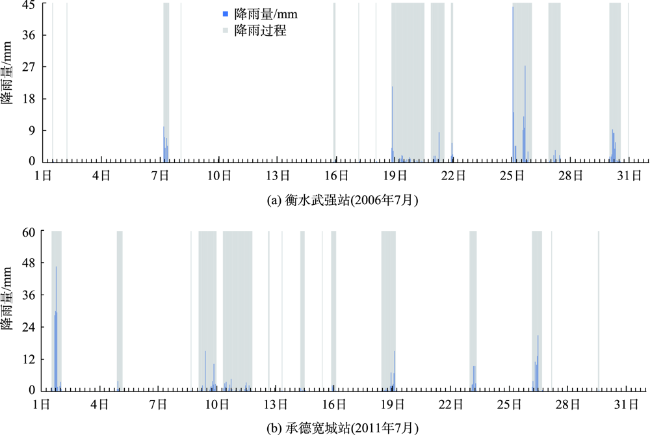
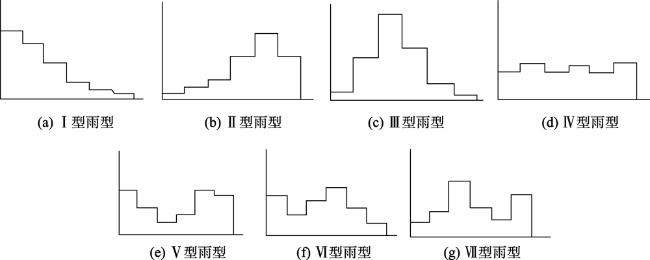
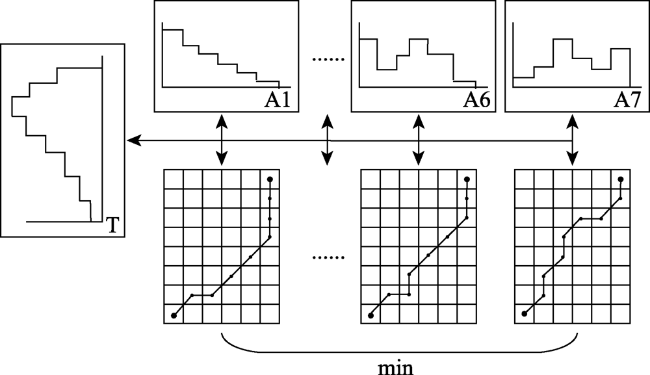
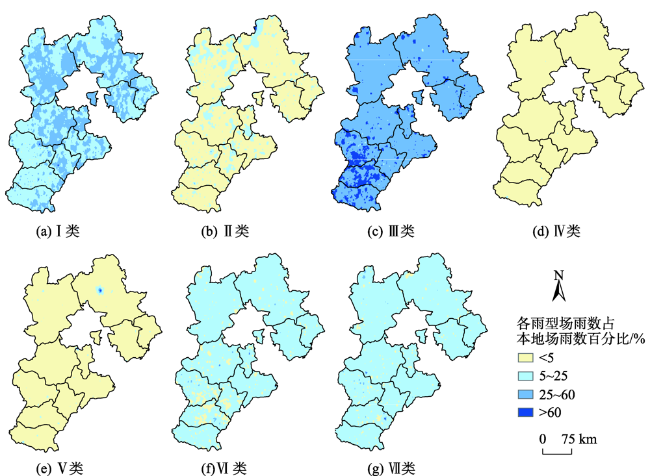
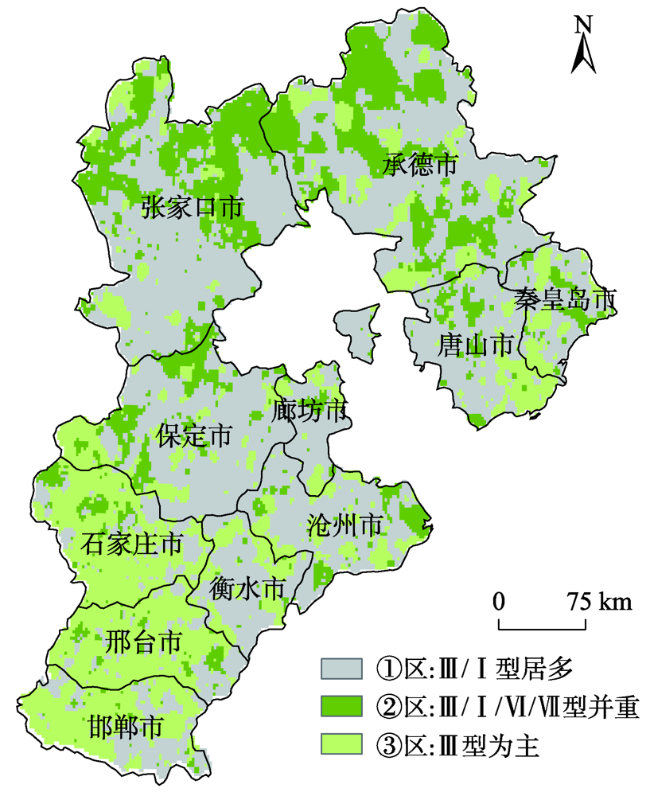
In-depth data mining of rainfall data and characterizing the rainfall events from meteorological records play an important role in formulation of flood disaster warning and mitigation measures. This paper analyzed a large number of hourly rainfall observations to quantify the rainfall pattern, cumulative rainfall, duration, and other indicators of rainfall events in Hebei province. First, we generated independent rainfall events based on the hourly precipitation data of 3189 stations in Hebei from 2005 to 2017. We counted the rainfall events for each station by calculating the time interval between rainfall events. Rainfall events with time interval less than 6h were counted as a single rainfall event. Otherwise, they were regarded as independent rainfall events. Then, we calculated the occurrence time, end time, duration, hourly accumulation, and total accumulation of each rainfall event. Finally, rainfall events were divided into seven types (I-Ⅶ), including three types of single-peak rainfall (i.e. single peak in the front, middle, and end), three types of double-peak rainfall, and uniform rainfall. The Dynamic Time Warping (DTW) algorithm was used for rainfall events classification. The results show that the rainfall in Hebei province was dominated by typeⅠ (single-peak rainfall in the front) and type Ⅲ (single-peak rainfall in the middle), which accounted for more than 70% of the total rainfall events with a significant spatial variation. The type Ⅳ (uniform rainfall) was the least with a proportion of less than 5%. The type Ⅱ (single-peak rainfall in the end) and three types of double-peak rainfall accounted for less than 25%. Through K-means clustering, the Hebei province was divided into 3 rain-type regions: district A, with type I and type Ⅲ rainfall mainly distributed in the Yanshan hilly climate region, the eastern Hebei plain climate region, and the piedmont plain climate region; district B, with type Ⅲ, type Ⅰ, type Ⅵ, and type Ⅶ rainfall scattered in the northern Hebei plateau climate zone and southern Chengde city; and district C, with type Ⅲ rainfall dominated in the southern part of Shijiazhuang City, Handan City, and most of Xingtai City. In this paper, the data mining method that combines DTW similarity algorithm and K-means clustering can be applied in future meteorological big data analysis.
Key words: field rain; rainfall type; data mining; DTW; K-means clustering; rainstorm disaster; zoning; Hebei
LI Yuxin , WANG Ying , MA Qingyuan , LIU Tianxue , SI Lili , YU Haiyang . Research on the Characteristics of Rainfall Events and Rain Pattern Zoning in Hebei based on Data Mining Technology[J]. Journal of Geo-information Science, 2021 , 23(5) : 860 -868 . DOI: 10.12082/dqxxkx.2021.200343
表1 2005—2017年河北省7种雨型的场雨数量(按站点统计)Tab. 1 Number of rain events for 7 rain types in Hebei from 2005 to 2017 (statistics by station) |
| 雨型 | |||||||
|---|---|---|---|---|---|---|---|
| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | |
| 数量/个 | 58 300 | 7893 | 128 932 | 522 | 2485 | 20 070 | 23 660 |
| 比例/% | 24.10 | 3.26 | 53.31 | 0.22 | 1.03 | 8.30 | 9.78 |
表2 2005—2017年河北三大雨型区的雨型统计Tab. 2 Rain type statistics of the three major areas in Hebei from 2005 to 2017 |
| 分区名称 | 站点数/个 | 雨型 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Ⅰ型 | Ⅱ型 | Ⅲ型 | Ⅳ型 | Ⅴ型 | Ⅵ型 | Ⅶ型 | |||
| ① 区 | 1620 | 数量/个 | 33 899 | 4062 | 66 669 | 271 | 1340 | 10 569 | 11 747 |
| 比例/% | 26.37 | 3.16 | 51.86 | 0.21 | 1.04 | 8.22 | 9.14 | ||
| ② 区 | 531 | 数量/个 | 9115 | 1607 | 19 086 | 102 | 535 | 3747 | 4521 |
| 比例/% | 23.55 | 4.15 | 49.30 | 0.26 | 1.38 | 9.68 | 11.68 | ||
| ③ 区 | 1038 | 数量/个 | 15 195 | 2168 | 43 306 | 162 | 584 | 5728 | 7449 |
| 比例/% | 20.37 | 2.91 | 58.06 | 0.22 | 0.78 | 7.68 | 9.99 | ||
表3 河北省历史暴雨的雨型与灾情对照Tab. 3 Comparison of rain types and heavy rain disasters in Hebei |
| 雨型分区 | 场雨信息 | 灾情信息 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 地市 | 区县 | 开始时间 | 历时/h | 雨型 | 累积量/mm | 死亡人数/人 | 受灾面积/hm2 | 直接经济损失/万元 | |
| ① | 保定市 | 定州市 | 2013060711 | 10 | Ⅰ | 97.2 | 1 | 3950.3 | 2735.1 |
| 沧州市 | 黄骅市 | 2010071811 | 20 | Ⅲ | 133.4 | 0 | 2700 | 3700 | |
| 衡水市 | 冀州市 | 2013081403 | 6 | Ⅰ | 30.8 | 0 | 6730 | 21 145 | |
| 秦皇岛市 | 抚宁县 | 2012072601 | 12 | Ⅲ | 52.8 | 2 | 2295 | 2750.5 | |
| 唐山市 | 玉田县 | 2006081003 | 8 | Ⅲ | 133.1 | 0 | 22 400 | 2341 | |
| 唐山市 | 玉田县 | 2009072218 | 2 | Ⅰ | 38.3 | 1 | 7377 | 2266 | |
| 张家口市 | 赤城县 | 2007070314 | 4 | Ⅰ | 16.4 | 6 | 2000 | 568 | |
| ② | 承德市 | 丰宁县 | 2006062819 | 11 | Ⅶ | 32.0 | 0 | 711 | 746 |
| 承德市 | 丰宁县 | 2009082623 | 1 | Ⅲ | 16.2 | 0 | 1267 | 1160 | |
| 邯郸市 | 武安市 | 2010080416 | 5 | Ⅰ | 48.2 | 0 | 343.3 | 210 | |
| 秦皇岛市 | 昌黎县 | 2012072603 | 11 | Ⅲ | 38.2 | 0 | 9409 | 6082.4 | |
| 石家庄市 | 平山县 | 2009080101 | 3 | Ⅰ | 24.4 | 0 | 3202 | 1538.4 | |
| 邢台市 | 临西县 | 2013071522 | 4 | Ⅵ | 28.9 | 0 | 1413 | 973 | |
| ③ | 保定市 | 唐县 | 2011082504 | 10 | Ⅲ | 27.8 | 0 | 1128 | 2980 |
| 沧州市 | 盐山县 | 2010071910 | 20 | Ⅲ | 155.9 | 0 | 1100 | 417 | |
| 衡水市 | 武强县 | 2013070113 | 12 | Ⅲ | 143.9 | 0 | 919 | 1000 | |
| 秦皇岛市 | 青龙县 | 2012072518 | 15 | Ⅲ | 49.9 | 0 | 4000 | 3500 | |
| 石家庄市 | 赞皇县 | 2009082600 | 11 | Ⅲ | 28.2 | 0 | 590 | 720 | |
| 邢台市 | 新河县 | 2013070116 | 11 | Ⅲ | 136.1 | 0 | 540.6 | 647.1 | |
| [1] |
国家气候中心. GB/T 33680-2017,暴雨灾害等级[S]. 北京: 中国标准出版社, 2017.
[ National Climate Center. GB/T 33680-2017, Rainstorm disaster level[S]. Beijing: Standard Press of China, 2017. ]
|
| [2] |
|
| [3] |
莫洛科夫. 雨水道与合流水道[M]. 北京: 建筑工程出版社, 1959.
[
|
| [4] |
岑国平, 沈晋. 城市设计暴雨雨型研究[J]. 水科学进展, 1998,9(1):41-46.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
张兴奇, 徐鹏程, 顾璟冉. SCS模型在贵州省毕节市石桥小流域坡面产流模拟中的应用[J]. 水土保持通报, 2017,37(3):321-328,333.
[
|
| [9] |
殷水清, 王杨, 谢云, 等. 中国降雨过程时程分型特征[J]. 水科学进展, 2014,25(5):617-624.
[
|
| [10] |
银磊, 陈晓宏, 陈志和, 等. 广州市典型雨量站暴雨雨型研究[J]. 水资源研究, 2013,2(6):409-414.
[
|
| [11] |
|
| [12] |
何清, 李宁, 罗文娟, 等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2014,27(4):327-336.
[
|
| [13] |
|
| [14] |
李进讷. 基于DSCAN优化算法与决策树优化算法的气象时空数据挖掘技术研究[D]. 昆明:云南大学, 2018.
[
|
| [15] |
李正欣, 郭建胜, 王瑛, 等. DTW距离的过滤搜索方法[J]. 控制与决策, 2018,33(7):1277-1281.
[
|
| [16] |
|
| [17] |
王彬雁, 赵琳娜, 巩远发, 等. 北京降雨过程分型特征及短历时降雨重现期研究[J]. 暴雨灾害, 2015,34(4):302-308.
[
|
| [18] |
吴焕丽, 崔可旺, 张馨, 等. 基于改进K-means图像分割算法的细叶作物覆盖度提取[J]. 农业机械学报, 2019,50(1):42-50.
[
|
| [19] |
|
| [20] |
《河北省气象灾害风险地图集》编辑委员会. 河北省气象灾害风险地图集[M]. 北京: 科学出版社, 2018.
[ Editorial committee of the Atlas of meteorological disaster risk in Hebei province. Atlas of meteorological disaster risk in Hebei province[M]. Beijing: Science Press, 2018. ]
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}