
Journal of Geo-information Science >
Remote Sensing Estimation of Grassland Aboveground Biomass based on Random Forest
Received date: 2020-10-15
Request revised date: 2021-01-21
Online published: 2021-09-25
Supported by
National Key Research and Development Program of China(2017YFC0506504)
National Natural Science Foundation of China(41571105)
Copyright
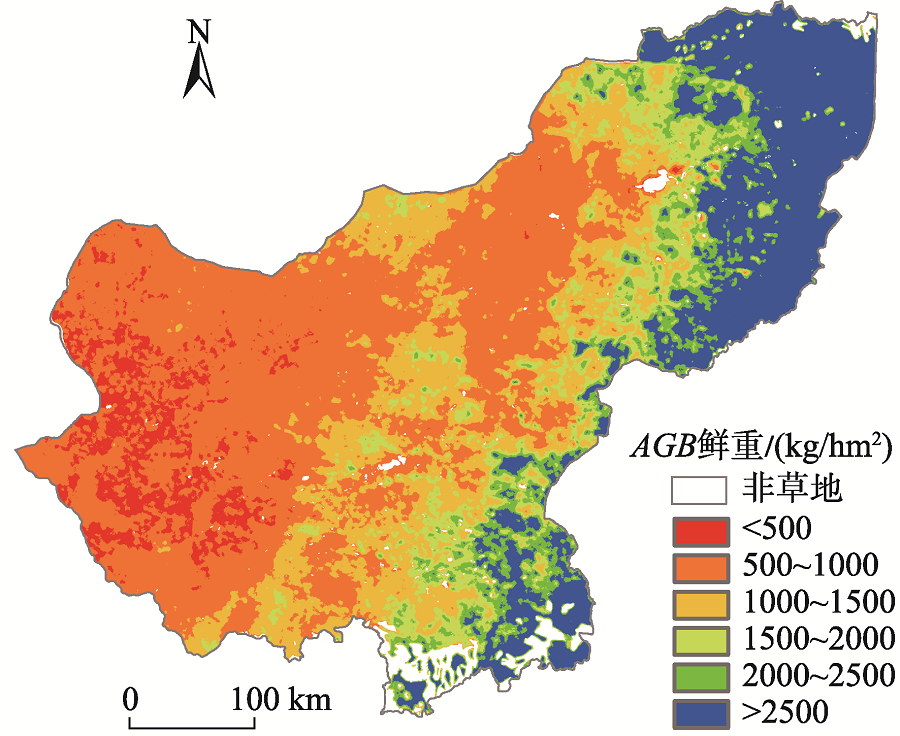
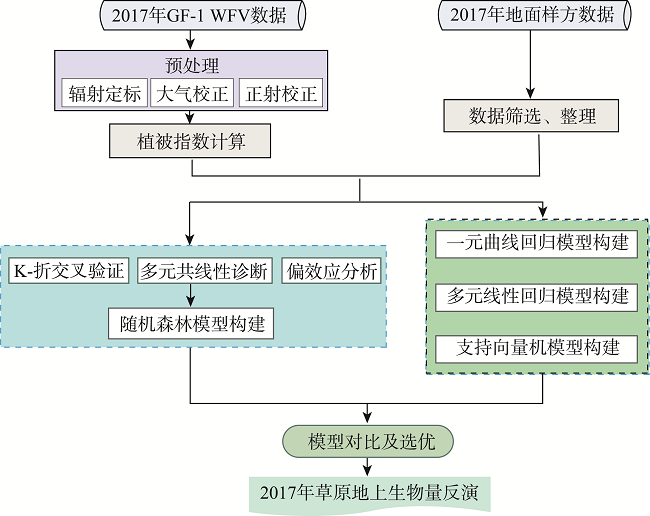
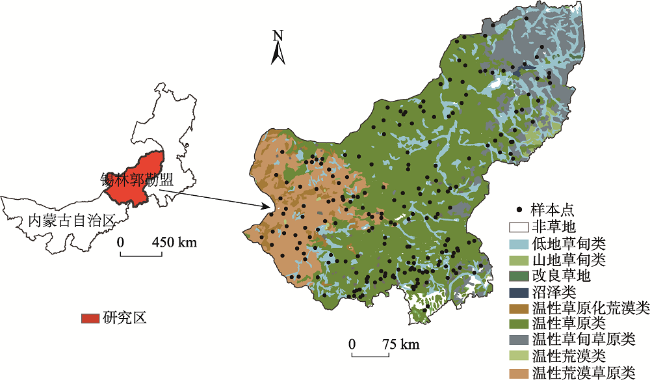
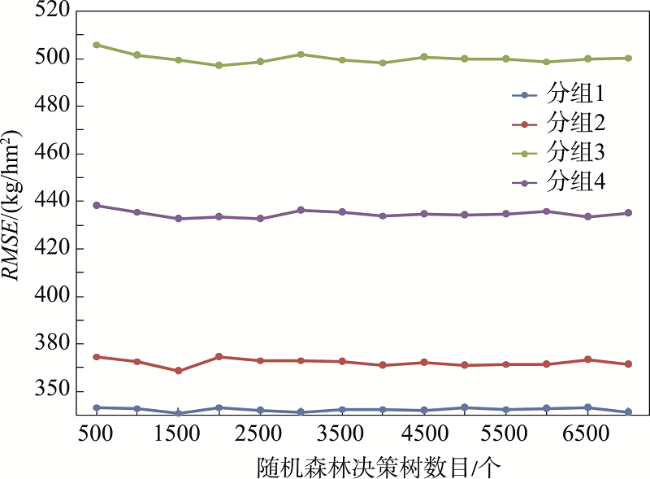
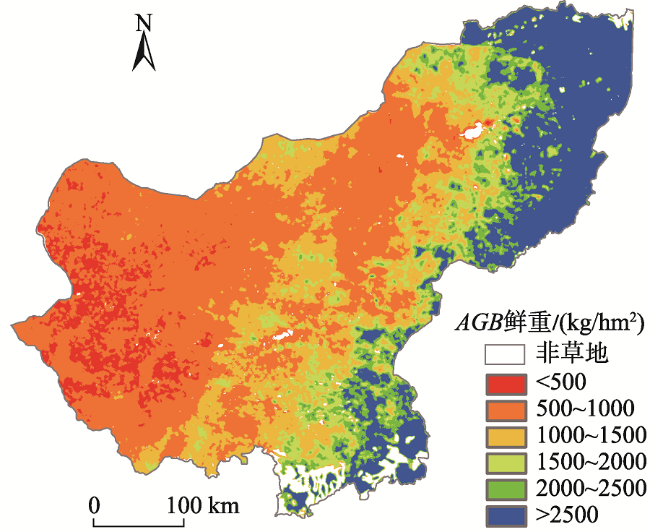
Grassland is the largest terrestrial ecosystem in China. Biomass is a key indicator of ecosystem quality and ecosystem function. It is of great significance for us to accurately estimate the grassland biomass for the effective and rational use of grassland resources, the restoration of damaged grassland ecosystem, and the high-quality development of animal husbandry. In this study, we took Xilinguole league of Inner Mongolia autonomous region as the research area. We used GF-1 satellite images, ground sample data of 216 sites, and Random Forest (RF) algorithm to estimate Grassland Aboveground Biomass (AGB) and explore the applicability of the algorithm in grassland biomass estimation. Moreover, in order to evaluate the applicability of random forest algorithm in aboveground biomass estimation, we carried out a series of analysis when using the algorithm, such as k-fold cross validation, multicollinearity diagnosis, partial effect and so on. Based this, we completed the construction of the random forest model and compared the modeling results with those from other models. Then, we selected the best model to realize the inversion estimation of grassland aboveground biomass in Xilinguole league. The main conclusions are as follows: (1) In the process of biomass model construction in Xilinguole league, random forest algorithm can avoid multicollinearity problem if there are multiple input variables; (2) The random forest model has better applicability than other models in the estimation of grassland biomass. The accuracy of the random forest model is 85% while the RMSE is 202.13 kg/hm2; (3) Using the random forest model, we estimated the grassland aboveground biomass of the whole study area in 2017. The results indicated that the spatial distribution had a decreasing trend from east to west. When grassland types are concerned, the grassland aboveground biomass yield of mountain meadow was the highest among all grassland types while the total yield of temperate grassland was the highest among all grassland types. The results are not only beneficial to the monitoring and evaluation of grassland ecosystem, but also have a certain reference value for grassland macro management.
XING Xiaoyu , YANG Xiuchun , XU Bin , JIN Yunxiang , GUO Jian , CHEN Ang , YANG Dong , WANG Ping , ZHU Libo . Remote Sensing Estimation of Grassland Aboveground Biomass based on Random Forest[J]. Journal of Geo-information Science, 2021 , 23(7) : 1312 -1324 . DOI: 10.12082/dqxxkx.2021.200605
表1 GF-1影像数据信息Tab. 1 GF-1 data information |
| 采集时间 | 云量覆盖/% | 传感器标识 | 景序列号 | 采集时间 | 云量覆盖/% | 传感器标识 | 景序列号 |
|---|---|---|---|---|---|---|---|
| 2017-07-17 | 0 | WFV1 | 3893398 | 2017-07-17 | 0 | WFV3 | 3892267 |
| 2017-07-17 | 0 | WFV1 | 3893464 | 2017-07-17 | 0 | WFV4 | 3892289 |
| 2017-07-17 | 0 | WFV2 | 3893487 | 2017-08-05 | 0 | WFV1 | 3961704 |
| 2017-07-17 | 0 | WFV2 | 3893486 | 2017-08-30 | 0 | WFV2 | 4048027 |
| 2017-07-17 | 0 | WFV2 | 3893485 | 2017-08-31 | 0 | WFV3 | 4053670 |
| 2017-07-17 | 0 | WFV3 | 3892265 | 2017-08-31 | 0 | WFV4 | 4053690 |
| 2017-07-17 | 0 | WFV3 | 3892266 |
表2 植被指数计算方法Tab. 2 Calculation formula of vegetation index |
| 植被指数 | 计算方法 | 公式编号 | 优缺点 |
|---|---|---|---|
| NDVI | NDVI= | (4) | 反映地表植被状况以及植被空间分布密度,但易饱和 |
| RVI | RVI= | (5) | 在植被密集的区域,比NDVI的灵敏度更高 |
| EVI | EVI= | (6) | 能够减少残留气溶胶污染、不易饱和 |
| SAVI | SAVI= | (7) | 修正了NDVI对土壤背景敏感性 |
| OSAVI | OSAVI= | (8) | 修正了NDVI对土壤背景敏感性,把参数值进行了固定 |
注: 为近红外波段反射率; 为红光波段反射率; 为蓝光波段反射率;L为土壤调节系数。 |
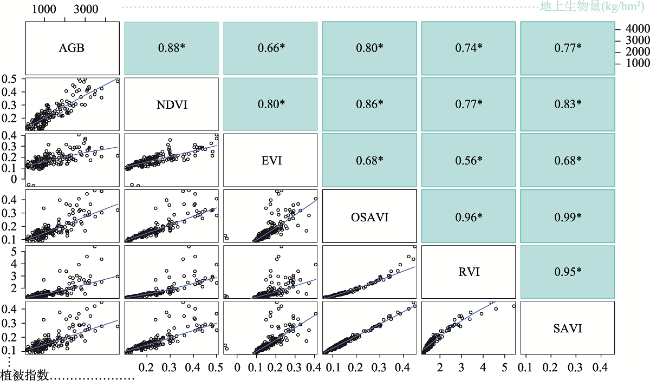
图4 训练集草原AGB与植被指数相关系数示意注: *表示显著相关。 Fig. 4 Correlation coefficient between grassland AGB and vegetation index in training set |
表4 植被指数共线性诊断结果Tab. 4 Co-linear diagnosis results of vegetation index |
| 维数 | 特征值 | 条件指标 | 方差比例 | |||||
|---|---|---|---|---|---|---|---|---|
| 常量 | NDVI | EVI | OSAVI | RVI | SAVI | |||
| 1 | 5.79 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 0.11 | 7.14 | 0.17 | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 |
| 3 | 0.06 | 9.54 | 0.06 | 0.02 | 0.26 | 0.00 | 0.02 | 0.00 |
| 4 | 0.01 | 17.38 | 0.01 | 0.38 | 0.44 | 0.00 | 0.00 | 0.00 |
| 5 | 0.00 | 31.52 | 0.14 | 0.00 | 0.14 | 0.01 | 0.64 | 0.05 |
| 6 | 0.00 | 118.62 | 0.62 | 0.59 | 0.15 | 0.99 | 0.34 | 0.94 |
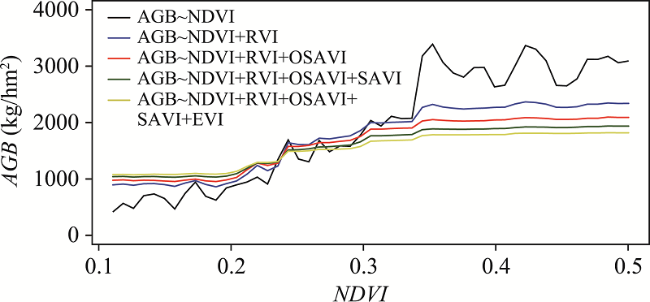
表5 随机森林模型构建结果Tab. 5 Results of random forest model |
| 模型 | 特征变量 | 解释方差百分比/% | 模型 | 特征变量 | 解释方差百分比/% |
|---|---|---|---|---|---|
| 1 | NDVI、RVI | 75.08 | 14 | NDVI、RVI、SAVI | 76.43 |
| 2 | NDVI、EVI | 72.66 | 15 | NDVI、OSAVI、SAVI | 74.93 |
| 3 | NDVI、SAVI | 75.45 | 16 | NDVI、OSAVI、EVI | 75.47 |
| 4 | NDVI、OSAVI | 72.74 | 17 | RVI、OSAVI、SAVI | 67.32 |
| 5 | EVI、OSAVI | 67.33 | 18 | RVI、EVI、SAVI | 70.72 |
| 6 | RVI、EVI | 70.35 | 19 | RVI、OSAVI、EVI | 69.81 |
| 7 | RVI、SAVI | 68.05 | 20 | OSAVI、EVI、SAVI | 68.11 |
| 8 | RVI、OSAVI | 65.69 | 21 | NDVI、RVI、OSAVI、EVI | 75.57 |
| 9 | SAVI、EVI | 64.04 | 22 | NDVI、RVI、OSAVI、SAVI | 75.40 |
| 10 | SAVI、OSAVI | 66.12 | 23 | NDVI、RVI、EVI、SAVI | 76.40 |
| 11 | NDVI、EVI、SAVI | 75.26 | 24 | NDVI、OSAVI、EVI、SAVI | 75.75 |
| 12 | NDVI、RVI、OSAVI | 74.60 | 25 | RVI、OSAVI、EVI、SAVI | 69.70 |
| 13 | NDVI、RVI、EVI | 75.50 | 26 | NDVI、RVI、OSAVI、EVI、SAVI | 74.98 |
表6 一元曲线回归建模结果Tab. 6 Results of UCR |
| 自变量x | 函数 | 方程 | R2 | F |
|---|---|---|---|---|
| NDVI | 线性函数 | y=8578.34x-682.73 | 0.77 | 535.69 |
| 指数函数 | y=220.71e6.57x | 0.64 | 281.28 | |
| 幂函数 | y=13601.63x1.70 | 0.69 | 352.18 | |
| RVI | 线性函数 | y=1053.71x-513.01 | 0.55 | 197.42 |
| 指数函数 | y=282.33e0.74x | 0.39 | 99.96 | |
| 幂函数 | y=380.49x1.95 | 0.50 | 158.87 | |
| EVI | 线性函数 | y=9308.95x-301.56 | 0.43 | 122.90 |
| 指数函数 | y=272.34e7.60x | 0.41 | 110.52 | |
| 幂函数 | - | - | - | |
| OSAVI | 线性函数 | y=9214.90x-321.26 | 0.65 | 291.12 |
| 指数函数 | y=301.50e6.86x | 0.51 | 163.04 | |
| 幂函数 | y=16726.34x1.55 | 0.60 | 234.53 | |
| SAVI | 线性函数 | y=10055.66x-407.66 | 0.60 | 231.82 |
| 指数函数 | y=284.69e7.44x | 0.46 | 135.05 | |
| 幂函数 | y=19424.01x1.61 | 0.53 | 180.02 |
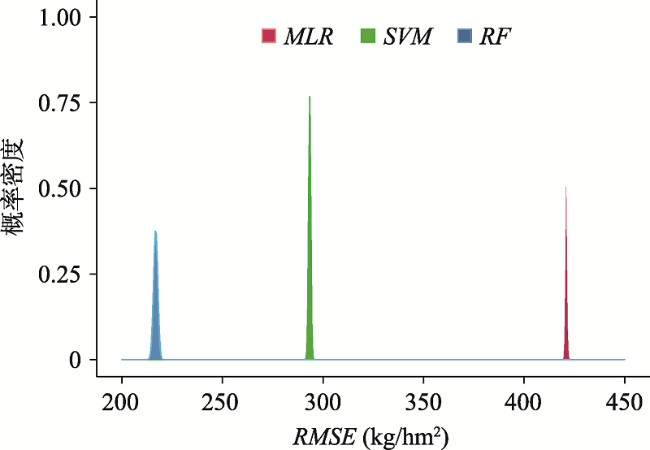
表7 训练集及验证集模型精度评价Tab. 7 Accuracy evaluation of training set and verification set model |
| 模型 | 模型或输入变量 | 训练集 | 验证集 | |||||
|---|---|---|---|---|---|---|---|---|
| RMSE /(kg/hm2) | REE/% | 精度/% | RMSE /(kg/hm2) | REE/% | 精度/% | |||
| RF | NDVI、RVI、SAVI | 202.13 | 15 | 85 | 346.73 | 30 | 70 | |
| SVM | NDVI、RVI、SAVI | 360.38 | 27 | 73 | 413.88 | 36 | 64 | |
| UCR | y=8578.34NDVI-682.73 | 434.46 | 33 | 67 | 401.94 | 35 | 65 | |
| MLR | y=7353.25NDVI+230.05RVI-796.72 | 259.63 | 20 | 80 | 417.99 | 36 | 64 | |
表8 2017年锡盟不同草原类型AGB鲜重单产、总量Tab. 8 Fresh weight per unit area yield and total amount of AGB of different grassland types in Xilinguole in 2017 |
| 草原类型 | 面积/km2 | AGB鲜重 | |
|---|---|---|---|
| 单产/(kg/hm2) | 总产量/t | ||
| 低地草甸类 | 26 014 | 1756.45 | 4 569 384 |
| 山地草甸类 | 1577 | 3029.59 | 477 963 |
| 改良草地 | 473 | 1092.77 | 51 777 |
| 沼泽类 | 334 | 2165.15 | 72 456 |
| 温性草原化荒漠类 | 5122 | 552.77 | 283 132 |
| 温性草原类 | 108 445 | 1249.61 | 13 551 464 |
| 温性草甸草原类 | 24 883 | 2616.22 | 6 510 032 |
| 温性荒漠类 | 142 | 576.49 | 8191 |
| 温性荒漠草原类 | 29 659 | 596.31 | 1 768 611 |
表9 输入单个变量模型精度对比Tab. 9 Precision comparison of input single variable models |
| 模型 | 模型或输入变量 | 验证集 | ||
|---|---|---|---|---|
| RMSE/(kg/hm2) | REE/% | 精度/% | ||
| RF | NDVI | 389.00 | 34 | 66 |
| SVM | NDVI | 381.65 | 33 | 66 |
| UCR | y=8578.34NDVI-682.73 | 401.94 | 35 | 65 |
| [1] |
|
| [2] |
张江, 袁旻舒, 张婧, 等. 近30年来青藏高原高寒草地NDVI动态变化对自然及人为因子的响应[J]. 生态学报, 2020, 40(18):6269-6281.
[
|
| [3] |
|
| [4] |
白永飞, 陈世苹. 中国草地生态系统固碳现状、速率和潜力研究[J]. 植物生态学报, 2018, 42(3):261-264.
[
|
| [5] |
金云翔, 徐斌, 杨秀春, 等. 内蒙古锡林郭勒盟草原产草量动态遥感估算[J]. 中国科学:生命科学, 2011, 41(12):1185-1195.
[
|
| [6] |
|
| [7] |
葛静, 孟宝平, 杨淑霞, 等. 基于ADC和MODIS遥感数据的高寒草地地上生物量监测研究—以黄河源区为例[J]. 草业学报, 2017, 26(7):26-37.
[
|
| [8] |
孟宝平, 陈思宇, 崔霞, 等. 基于多源遥感数据的高寒草地生物量反演模型精度—以夏河县桑科草原试验区为例[J]. 草业科学, 2015, 32(11):1730-1739.
[
|
| [9] |
朴世龙, 方精云, 贺金生, 等. 中国草地植被生物量及其空间分布格局[J]. 植物生态学报, 2004, 28(4):491-498.
[
|
| [10] |
张雅, 尹小君, 王伟强, 等. 基于Landsat 8 OLI遥感影像的天山北坡草地地上生物量估算[J]. 遥感技术与应用, 2017, 32(6):1012-1021.
[
|
| [11] |
|
| [12] |
赖炽敏, 赖日文, 薛娴, 等. 基于植被盖度和高度的不同退化程度高寒草地地上生物量估算[J]. 中国沙漠, 2019, 39(5):127-134.
[
|
| [13] |
孙世泽, 汪传建, 尹小君, 等. 无人机多光谱影像的天然草地生物量估算[J]. 遥感学报, 2018, 22(5):848-856.
[
|
| [14] |
|
| [15] |
徐斌, 杨秀春, 陶伟国, 等. 中国草原产草量遥感监测[J]. 生态学报, 2007, 27(2):405-413.
[
|
| [16] |
|
| [17] |
何清, 李宁, 罗文娟, 等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2014, 27(4):327-336.
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
修晓敏, 周淑芳, 陈黔, 等. 基于Google Earth Engine与机器学习的省级尺度零散分布草地生物量估算[J]. 测绘通报, 2019(3):46-52,75.
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
NY/T 1233-2006,草原资源与生态监测技术规程[S].
[NY/T 1233-2006, Technical rules for monitoring of rangeland resources and ecology[S]. ]
|
| [26] |
杨秀春, 徐斌, 朱晓华, 等. 北方农牧交错带草原产草量遥感监测模型[J]. 地理研究, 2007, 26(2):213-221,425.
[
|
| [27] |
中国资源卫星应用中心. 高分一号WFV数据[DB/OL]. http://218.247.138.119:7777/DSSPlatform/index.html.
[China center for resources satellite data and application. GF-1 WFV dataset[DB/OL]. http://218.247.138.119:7777/DSSPlatform/index.html.]
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
李欣海. 随机森林是特点鲜明的模型,不是万能的模型[J]. 应用昆虫学报, 2019, 56(1):170-179.
[
|
| [36] |
|
| [37] |
姚登举, 杨静, 詹晓娟. 基于随机森林的特征选择算法[J]. 吉林大学学报(工学版), 2014, 44(1):137-141.
[
|
| [38] |
孟杰, 李春林. 基于随机森林模型的分类数据缺失值插补[J]. 统计与信息论坛, 2014, 29(9):86-90.
[
|
| [39] |
张雷, 王琳琳, 张旭东, 等. 随机森林算法基本思想及其在生态学中的应用—以云南松分布模拟为例[J]. 生态学报, 2014, 34(3):650-659.
[
|
| [40] |
|
| [41] |
王建步, 张杰, 马毅, 等. 基于高分一号WFV卫星影像的黄河口湿地草本植被生物量估算模型研究[J]. 激光生物学报, 2014, 23(6):604-608.
[
|
| [42] |
方精云, 刘国华, 徐嵩龄. 中国陆地生态系统的碳库[A]//王庚辰, 温玉璞.温室气体浓度和排放监测及相关过程[C].北京:中国环境科学出版社, 1996. 81-149.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}