
Journal of Geo-information Science >
Word Embedding-based Method for Entity Category Alignment of Geographic Knowledge Base
Received date: 2020-09-29
Request revised date: 2020-12-23
Online published: 2021-10-25
Supported by
General Program of National Natural Science Foundation of China(41771430)
Strategic Priority Research Program of the Chinese Academy of Sciences (Category A)(XDA23100100)
Key Program of National Natural Science Foundation of China(41631177)
Copyright
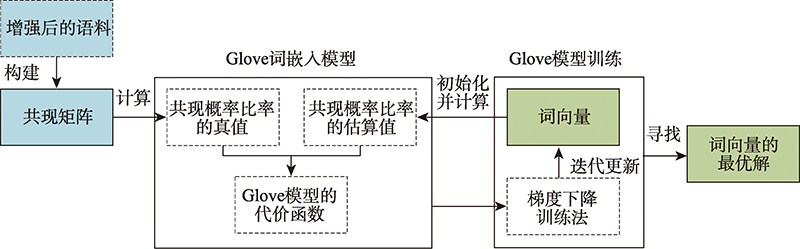
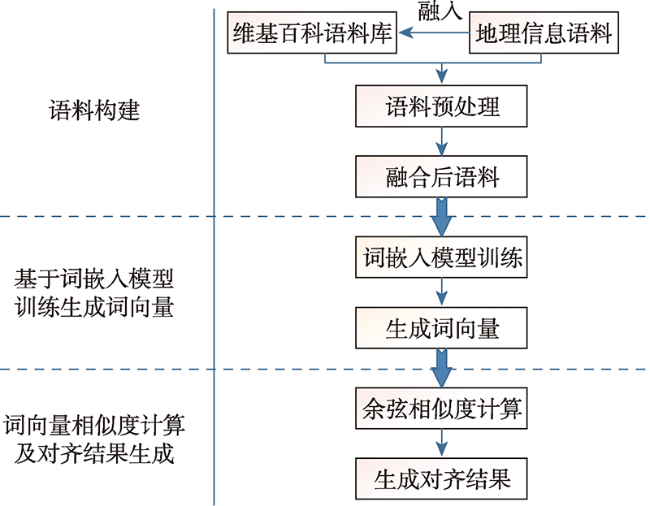
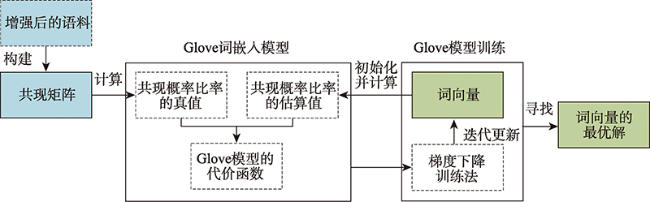
Geographic knowledge base is a collection of geographic entities and the relationships between them, which plays an important role in many applications of knowledge services, such as intelligent search, question answering, and recommendation. However, due to the differences in the data source, data form, and publisher, the existing geographical knowledge bases have the problems of homonym and homographs in the place name, spatial footprint, and feature type. Thus it leads to a barrier of the knowledge sharing and fusion between different geographic knowledge bases. Semantic alignment is an effective way to solve semantic heterogeneity, and the alignment of feature types is very important to further improve the accuracy of the alignments of place names and spatial footprints. The existing methods of feature type alignment mainly rely on the traditional similarity measures of string and structure of feature types that are unable to capture their deep semantic correlation, thereby influencing the alignment accuracy. Therefore, this paper proposes a word embedding based method to align the feature type. The proposed method uses the word embedding model to learn the semantic information of feature type from the corpus and represent the learned information as a vector, so as to capture the deep semantic information of feature type which cannot be obtained by using the existing methods, thereby increasing the alignment accuracy. Meanwhile, this paper enhances the geographic semantics of the corpus by the combination of the corpus of geographic information and the general corpus used in the word embedding model, which can help to more accurately measure the correlation of feature types. In the case study, the method is applied to align the feature types of different geographic knowledge bases. The results show that the averageFl score is up to 0.9568, and indicates the method can effectively capture the deep semantic information of geographic feature types, effectively improving the alignment accuracy of entity categories.
XU Zhaohua , ZHU Yunqiang , SONG Jia , SUN Kai , WANG Shu . Word Embedding-based Method for Entity Category Alignment of Geographic Knowledge Base[J]. Journal of Geo-information Science, 2021 , 23(8) : 1372 -1381 . DOI: 10.12082/dqxxkx.2021.200566
表1 地理信息语义增强前与增强后语料对比Tab. 1 Corpora comparison between wikipedia and geo-infromation enhanced wikipedia |
| 语料 | 地理语义相关语料/万句 | 总语料/万句 | 地理语义相关语料占比/% | |
|---|---|---|---|---|
| 增强前语料 | 维基百科 | 101 | 1300 | 7.8 |
| 维基百科 | ||||
| COCA | ||||
| 增强后语料 | ADL | 461.3 | 1660.3 | 27.8 |
| GeoNames | ||||
| OpenStreetMap |
表2 中心词与上下文词共现概率及其比率示例Tab. 2 The example of co-occurrence probability and their ratio between central words and their contextual word |
| 共现概率和共现概率比率 | ||||
|---|---|---|---|---|
| worship | medical | building | stream | |
| 3.6×10-3 | 5.1×10-4 | 2.3×10-3 | 4.8×10-5 | |
| 7.4×10-5 | 4.5×10-2 | 1.9×10-3 | 5.3×10-5 | |
| 48.65 | 1.13×10-2 | 1.21 | 0.91 | |
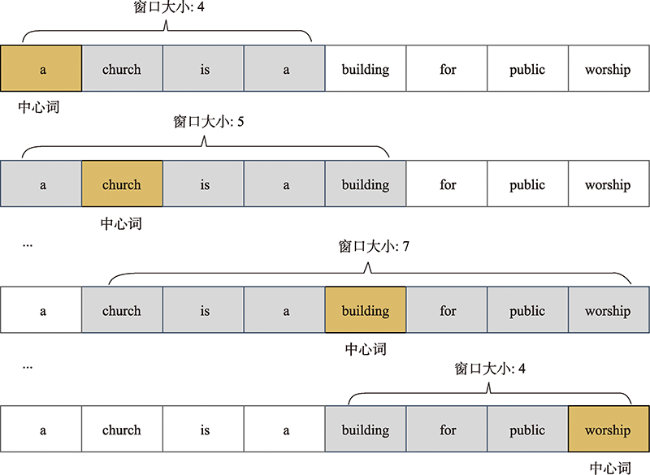
图4 基于上下文窗口滑动构造共现矩阵的过程Fig. 4 The process of constructing co-occurrence matrix by moving the context window |
表3 基于语料构建共现矩阵示例Tab.3 The example of co-occurrence matrix is constructed based on corpus |
| 共现次数 | a | church | is | building | for | public | worship |
|---|---|---|---|---|---|---|---|
| a | 0 | 2 | 2 | 1 | 1 | 1 | 0 |
| church | 2 | 0 | 1 | 1 | 0 | 0 | 0 |
| is | 2 | 1 | 0 | 1 | 1 | 0 | 0 |
| building | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| for | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| public | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
| worship | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
表4 基于通用语料获取的地理实体类别词向量(100维)Tab. 4 The word vectors of geographic feature types based on the general corpus (100 dimensions) |
| 实体类别 | 词向量 |
|---|---|
| oasis | -0.580 40, 0.148 84, -0.454 19, -0.300 85, -0.554 18, -0.018 43, 0.351 84, 0.408 83, -0.404 40… |
| park | -1.095 60, -0.155 51, -0.972 22, -1.818 40, -0.598 84, 0.344 45, -0.099 34, 1.859 00, 0.853 13… |
| administrative | 0.066 86, -0.268 48, -3.086 20, 0.268 34, 0.436 32, -0.222 43, 3.822 60, 0.232 78, 0.286 44… |
| coalfield | -0.165 19, -0.702 90, -0.065 52, 0.517 61, 0.911 22, -1.699 70, -0.621 05, 0.115 77, 0.970 76… |
| sea | 0.430 72, 0.001 32 0.017 85, -0.515 49, -0.544 66, -0.251 15, -0.376 32, 0.409 69, 0.070 36… |
| port | 3.260 20, 0.402 33, -0.378 02, 0.746 37, -0.283 72, -3.044 60, -0.688 62, 0.387 26, 0.226 82 … |
| zone | -0.342 23, -0.023 63, 0.070 36, 0.640 23, -0.023 48, -3.332 00, -0.204 02, -0.236 04, 0.423 27… |
| gasfield | 0.557 30, -0.371 48, 0.221 42, -0.185 06, -0.058 73, -0.036 90, -0.585 59, 0.514 58, -0.128 90… |
| stream | 0.062 51, 0.973 83, 1.863 10, -0.659 92, 0.014 52, -0.326 38, -0.071 11, -0.182 26, -0.431 97… |
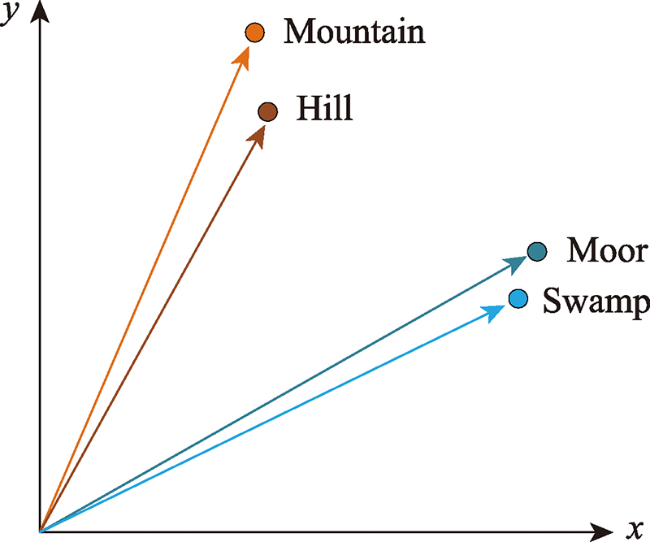
表5 基于通用和地理信息语义增强语料库的实体类别相似度结果对比(以swamp为例)Tab. 5 Comparison of feature types similarity based on the general corpus and geo-information enhanced corpus (taking "swamp" as an example) |
| 序号 | 基于通用语料库计算的相似度 | 序号 | 基于地理信息语义增强语料库的相似度 | ||||
|---|---|---|---|---|---|---|---|
| s | s | ||||||
| 1 | swamp | wetland | 0.9255 | 1 | swamp | moor | 0.9801 |
| 2 | swamp | mud-flat | 0.9067 | 2 | swamp | marsh | 0.9772 |
| 3 | swamp | moor | 0.8891 | 3 | swamp | wetland | 0.9364 |
| 4 | swamp | marsh | 0.8743 | 4 | swamp | mud-flat | 0.9105 |
| … | swamp | … | … | … | swamp | … | … |
表6 基于通用语料库与地理信息语义增强语料库的实体类别对齐结果(200维)Tab. 6 Alignment results of feature types based on general corpus and geo-information enhanced corpus (200 dimensions) |
| 序号 | 基于通用语料库计算的相似度 | 序号 | 基于地理信息语义增强语料库的相似度 | ||||
|---|---|---|---|---|---|---|---|
| s | s | ||||||
| 1 | wells | blowhole | 0.6355 | 1 | wells | spring | 0.9127 |
| 2 | caldera | peak | 0.6187 | 2 | caldera | volcano | 0.9187 |
| 3 | islet | island | 0.9345 | 3 | islet | island | 0.9864 |
| 4 | channel | bay | 0.6561 | 4 | channel | strait | 0.8548 |
| 5 | oilfield | farmland | 0.2718 | 5 | oilfield | fuel | 0.6744 |
| 6 | field(s) | greenfield | 0.4481 | 6 | field(s) | meadow | 0.9133 |
| 7 | promenade | path | 0.7213 | 7 | promenade | corridor | 0.8691 |
| 8 | swamp | wetland | 0.9376 | 8 | swamp | moor | 0.9835 |
| 9 | sill | ridge | 0.6755 | 9 | sill | stone | 0.7591 |
| 10 | portage | transport | 0.8366 | 10 | portage | transport | 0.9185 |
| 11 | gulf | coastline | 0.5738 | 11 | gulf | bay | 0.9313 |
| 12 | area | range | 0.8746 | 12 | area | district | 0.9218 |
| 13 | harbor(s) | bay | 0.7312 | 13 | harbor(s) | port | 0.9865 |
| 14 | watercourse | waterway | 0.8067 | 14 | watercourse | waterway | 0.9822 |
| 15 | desert | dune | 0.8367 | 15 | desert | sand | 0.9763 |
| … | … | … | … | … | … | … | … |
表7 基于通用语料库和地理信息增强语料库的对齐结果精度评价Tab. 7 The accuracy evaluation of alignment results based on general corpus and geo-information enhanced corpus |
| 维度(d) | 基于通用语料库 | 基于地理信息语义增强的语料库 | |||||
|---|---|---|---|---|---|---|---|
| 50 | 0.8462 | 0.8652 | 0.8556 | 0.9355 | 0.9775 | 0.9560 | |
| 100 | 0.8720 | 0.8427 | 0.8571 | 0.9659 | 0.9551 | 0.9605 | |
| 200 | 0.8861 | 0.7865 | 0.8333 | 0.9765 | 0.9326 | 0.9540 | |
| 平均值 | 0.8681 | 0.8315 | 0.8487 | 0.9593 | 0.9551 | 0.9568 | |
注:蓝色数值代表在3种维度下该列指标取得最好结果时对应的某一维度的指标值。 |
| [1] |
诸云强, 孙九林, 廖顺宝, 等. 地球系统科学数据共享研究与实践[J]. 地球信息科学学报, 2010, 12(1):1-8.
[
|
| [2] |
闾国年, 俞肇元, 周良辰, 等. 地理实体分类与编码体系的构建[J]. 现代测绘, 2019, 42(1):1-6.
[
|
| [3] |
罗斌. 关于维基百科中的实体类别推断方法的研究[D]. 南京:东南大学, 2017.
[
|
| [4] |
|
| [5] |
王汀, 高迎, 刘经纬. 一种面向中文本体模式的本体对齐框架[J]. 数据分析与知识发现, 2017, 1(2):47-57.
[
|
| [6] |
俞婷婷, 徐彭娜, 江育娥, 等. 基于改进的Jaccard系数文档相似度计算方法[J]. 计算机系统应用, 2017, 26(12):137-142.
[
|
| [7] |
尹康银, 宋自林, 乔可春, 等. 基于树结构RDF闭包生成算法研究[J]. 系统仿真学报, 2008, 20(4):1072-1075,1079.
[
|
| [8] |
姜华, 韩安琪, 王美佳, 等. 基于改进编辑距离的字符串相似度求解算法[J]. 计算机工程, 2014, 40(1):222-227.
[
|
| [9] |
于永彦. 基于Jaccard距离与概念聚类的多模型估计[J]. 计算机工程, 2012, 38(10):22-26.
[
|
| [10] |
徐爽, 张谦, 李琰, 等. 基于距离类别的多源兴趣点融合算法[J]. 计算机应用, 2018, 38(5):118-122.
[
|
| [11] |
江铭虎. 自然语言处理[M]. 北京: 高等教育出版社, 2007.
[
|
| [12] |
|
| [13] |
邓晓衡, 杨子荣, 关培源. 一种基于词义和词频的向量空间模型改进方法[J]. 计算机应用研究, 2019, 36(5):1390-1395.
[
|
| [14] |
|
| [15] |
|
| [16] |
赵飞, 周涛, 张良, 等. 维基百科研究综述[J]. 电子科技大学学报, 2010, 39(3):321-334.
[
|
| [17] |
|
| [18] |
Wikipedia Cprpus[DB/OL]. https://dumps.wikimedia.org/enwiki/, 2019- 6- 7
|
| [19] |
Corpus of Contemporary American English[DB/OL]. https://www.english-corpora.org/coca/, 2019- 8- 16
|
| [20] |
Alexandria Digital Library[EB/OL]. http://legacy.alexandria.ucsb.edu/, 2019- 10- 11
|
| [21] |
GeoNames[EB/OL]. http://www.geonames.org/export/codes.html, 2019- 11- 14
|
| [22] |
OpenStreetMap[EB/OL]. https://wiki.openstreetmap.org/wiki/Map_Features, 2019- 12- 21
|
| [23] |
|
| [24] |
|
| [25] |
徐帆. Word Embedding方法的研究及应用[D]. 沈阳:沈阳航空航天大学, 2018.
[
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
刘瑞元. 加权欧氏距离及其应用[J]. 数理统计与管理, 2002, 21(5):17-19.
[
|
| [33] |
张振亚, 王进, 程红梅, 等. 基于余弦相似度的文本空间索引方法研究[J]. 计算机科学, 2005, 32(9):160-163.
[
|
| [34] |
苏佳林, 王元卓, 靳小龙, 等. 融合语义和结构信息的知识图谱实体对齐[J]. 山西大学学报(自然科学版), 2019, 42(1):23-30.
[
|
| [35] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}