
Journal of Geo-information Science >
User's Home Location Prediction based on Filtered Text and Social Networks
Received date: 2021-01-17
Request revised date: 2021-03-19
Online published: 2021-12-25
Supported by
National Natural Science Foundation of China(41471322)
Copyright
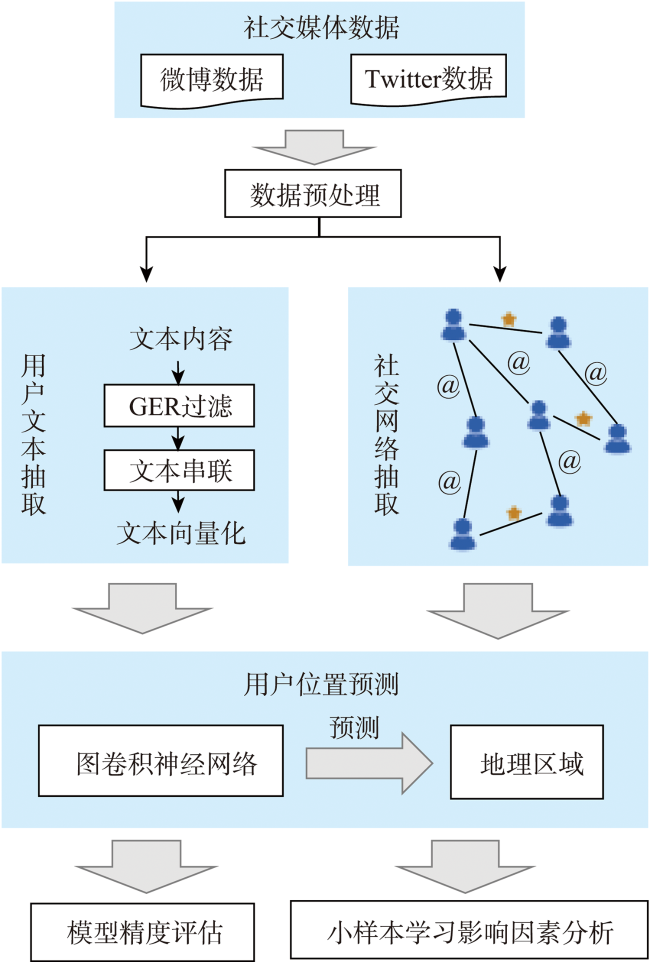
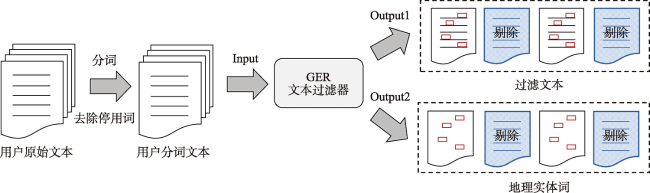
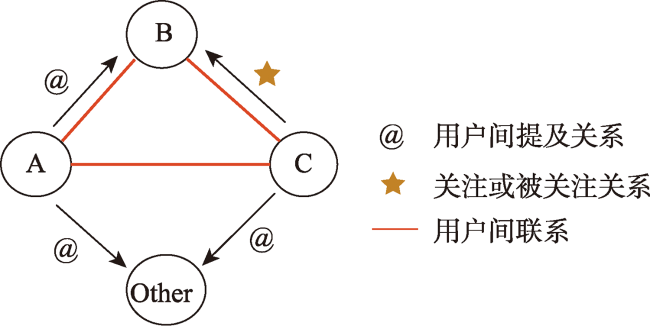
The home locations of social media users are essential for a wide range of applications in real-world. The social media text published by users from different regions possesses quite a few differences in expression mode, semantics, and other contents. In general, users with close social relationships live closer to each other. Therefore, both text and social network can be used to infer the home locations of users. The existing user’s home location prediction methods based on social network and text are not sufficient to mine the location indicative features in user text, while the location indicative information such as toponym in text provides the most useful location signals. Therefore, we proposed a location prediction method for social media users based on Geographic Entity Recognition (GER) and Graph Convolutional Network (GCN). Firstly, the user text was filtered by the geographic entity recognition method to highlight the location indicative words. Then, the social networks were extracted based on mentioned relationships and following relationships. After that, we combined social network and user text content that contains location indicative words. The method based on graph convolutional network was used to predict the user's home location. Finally, we compared the GER-GCN method with the GCN method and the latest research results, and explored the small sample learning ability of the model and its influencing factors. Experiment results based on the GeoText dataset and two datasets of microblog show that, firstly, GER text filtering method can significantly improve the accuracy of user location prediction. The improvement effect of this method is more significant for the dataset with more microblogs of users, which indicates that the GER text filtering method is more suitable for the social media dataset with more microblogs of users. Secondly, in the experiments of different datasets, the prediction accuracy of GER-GCN method is invariably the highest among all methods. In the experiment of GeoText benchmark dataset, the prediction accuracy of GER-GCN method is 1.03% and 1.87% higher than that of GCN and MENET methods, respectively, which indicates that the GER-GCN method is more competitive than the latest research results. Thirdly, in a realistic scenario with minimal supervision, we confirm that the GER-GCN model possesses a certain small sample learning ability, and find that the quality of social networks plays a decisive role in its small sample learning ability. The experimental results demonstrate the excellent performance of the GER-GCN method, and the method is in line with the application requirements of social media in the realistic scenarios.
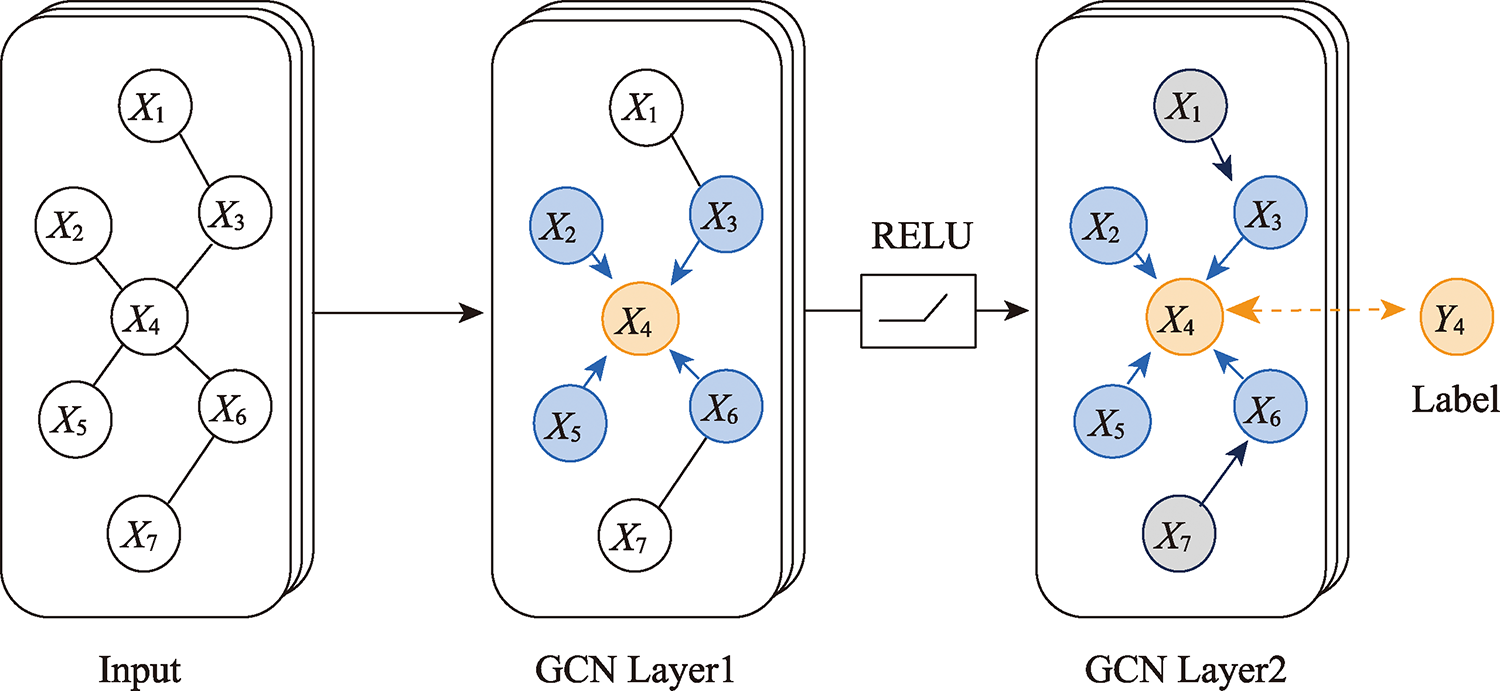
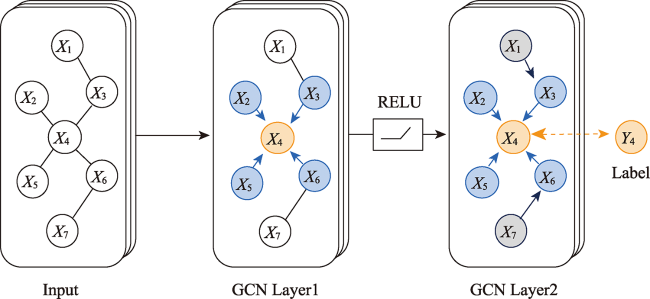
WANG Haiqi , KONG Haoran , LI Xuewei . User's Home Location Prediction based on Filtered Text and Social Networks[J]. Journal of Geo-information Science, 2021 , 23(10) : 1778 -1786 . DOI: 10.12082/dqxxkx.2021.210025
表1 数据详情Tab. 1 Details of the data |
| 数据集 | 平台 | 数据来源 | 真实地理标签 | 文本数量/条 |
|---|---|---|---|---|
| GeoText | GeoText | 签到位置 | 367 993 | |
| Sina2018 | 新浪微博 | 网络爬虫 | 签到位置 | 1 720 236 |
| SMP2016 | 新浪微博 | SMP竞赛 | 主页所在地 | 15 741 075 |
表2 文本过滤结果统计Tab. 2 Statistics of text filtering results |
| 数据集 | 原始文本/条 | GER过滤器 | GER过滤文本/条 | 地理实体词/个 | 唯一实体词/个 | |
|---|---|---|---|---|---|---|
| Sina2018 | 1 720 236 | BERT | 380 553 | 677 332 | 178 358 | |
| SMP2016 | 15 741 075 | BERT | 8 689 359 | 26 413 734 | 3 223 556 | |
| GeoText | 367 993 | NLTK | 103 240 | 139 935 | 48 567 | |
表3 社交网络参数统计Tab. 3 Statistics of social network parameters |
| 数据集 | 文本数/条 | 节点数/个 | 度数阈值/个 | 边数/条 |
|---|---|---|---|---|
| Sina2018 | 1 720 236 | 160 416 | 15 | 187 577 |
| SMP2016 | 15 741 075 | 30 414 | 15 | 332 189 |
| GeoText | 367 993 | 9 326 | 5 | 56 564 |
表4 GCN、GER-GCN和MENET模型用户地理区域精度预测结果Tab. 4 Accuracy prediction results of user geographic area by GCN, GER-GCN and MENET models |
| 数据集 | 方法 | 文本抽取 | 地区/% | 省或州/% | 市/% |
|---|---|---|---|---|---|
| Sina2018 | GCN | 原始文本 | 60.85 | 48.64 | 40.36 |
| GER-GCN | GER过滤文本 | 64.12 | 53.28 | 43.94 | |
| GER-GCN | GER地理实体词 | 63.06 | 53.39 | 41.69 | |
| SMP2016 | GCN | 原始文本 | 56.55 | 47.21 | 36.02 |
| GER-GCN | GER过滤文本 | 60.85 | 48.64 | 40.36 | |
| GER-GCN | GER地理实体词 | 61.17 | 54.36 | 42.86 | |
| GeoText | GCN[23] | 原始文本 | - | 65.64 | - |
| GER-GCN | GER过滤文本 | - | 66.67 | - | |
| GER-GCN | GER地理实体词 | - | 66.13 | - | |
| MENET[22] | - | 64.80 | - | ||
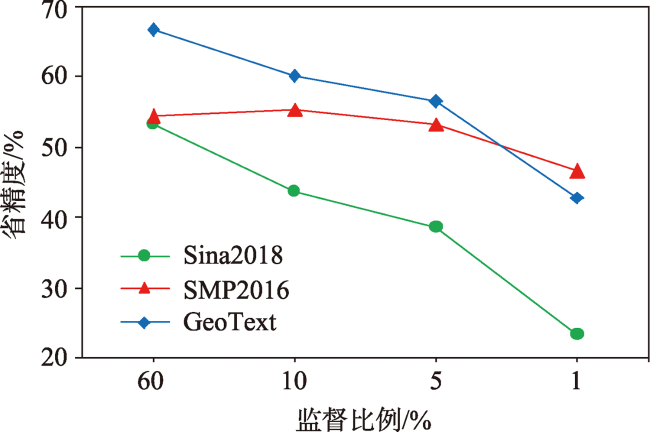
表5 GER-GCN模型不同监督比例的用户地理区域精度预测结果Tab. 5 Accuracy prediction results of user geographic area at different supervision proportions of GER-GCN model |
| 数据集 | 模型 | Train/Val/Test | 地区/% | 省或州/% | 市/% |
|---|---|---|---|---|---|
| Sina2018 | GER-GCN(过滤文本) | 60%/20%/20% | 64.12 | 53.28 | 43.94 |
| GER-GCN(过滤文本) | 10%/10%/80% | 57.00 | 43.65 | 32.15 | |
| GER-GCN(过滤文本) | 5% / 5% / 90% | 52.84 | 38.46 | 26.63 | |
| GER-GCN(过滤文本) | 1% / 1% / 98% | 41.12 | 23.21 | 17.09 | |
| SMP2016 | GER-GCN(地理实体词) | 60%/20%/20% | 61.17 | 54.36 | 42.86 |
| GER-GCN(地理实体词) | 10%/10%/80% | 63.51 | 55.47 | 43.97 | |
| GER-GCN(地理实体词) | 5% / 5% / 90% | 63.02 | 53.38 | 43.28 | |
| GER-GCN(地理实体词) | 1% / 1% / 98% | 57.36 | 46.51 | 37.67 | |
| GeoText | GER-GCN(过滤文本) | 60%/20%/20% | - | 66.67 | - |
| GER-GCN(过滤文本) | 10%/10%/80% | - | 60.09 | - | |
| GER-GCN(过滤文本) | 5% / 5% / 90% | - | 56.45 | - | |
| GER-GCN(过滤文本) | 1% / 1% / 98% | - | 42.85 | - |
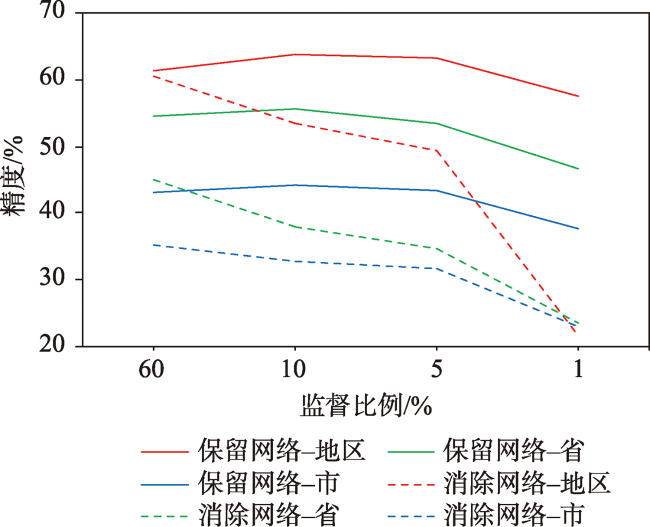
表6 保留或消除网络后GER-GCN模型不同监督比例的地区、省和市精度预测结果Tab. 6 Regional, provincial and municipal prediction accuracy results at different supervisory proportions of GER-GCN model after the network were retained or eliminated |
| 社交网络 | 模型 | Train/Val/Test | 地区/% | 省/% | 市/% |
|---|---|---|---|---|---|
| 保留 | GER-GCN(地理实体词) | 60%/20%/20% | 61.17 | 54.36 | 42.86 |
| 保留 | GER-GCN(地理实体词) | 10%/10%/80% | 63.51 | 55.47 | 43.97 |
| 保留 | GER-GCN(地理实体词) | 5% / 5% / 90% | 63.02 | 53.38 | 43.28 |
| 保留 | GER-GCN(地理实体词) | 1% / 1% / 98% | 57.36 | 46.51 | 37.67 |
| 消除 | GER-GCN(地理实体词) | 60%/20%/20% | 60.41 | 44.99 | 35.08 |
| 消除 | GER-GCN(地理实体词) | 10%/10%/80% | 53.37 | 37.93 | 32.52 |
| 消除 | GER-GCN(地理实体词) | 5% / 5% / 90% | 49.17 | 34.45 | 31.68 |
| 消除 | GER-GCN(地理实体词) | 1% / 1% / 98% | 21.61 | 23.41 | 22.91 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
梁春阳, 林广发, 张明锋, 等. 社交媒体数据对反映台风灾害时空分布的有效性研究[J]. 地球信息科学学报, 2018, 20(6):807-816.
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
中国中文信息学会社会媒体处理专业委员会. 微博用户画像数据[EB/OL]. http://www.cips-smp.org/smp_data/1 2016-09-20.
[ Social Media Processing Professional Committee of Chinese Information Processing Society of China. Microblog user profiling data[EB/OL]. http://www.cips-smp.org/smp_data/1 2016-09-20. ]
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}