
Journal of Geo-information Science >
Deep Learning based on Image Matching Method for Oblique Photogrammetry
Received date: 2021-05-31
Request revised date: 2021-07-02
Online published: 2021-12-25
Supported by
China High-resolution Earth Observation System(42-Y30B04-9001-19/21)
National Natural Science Foundation of China(41971427)
Copyright
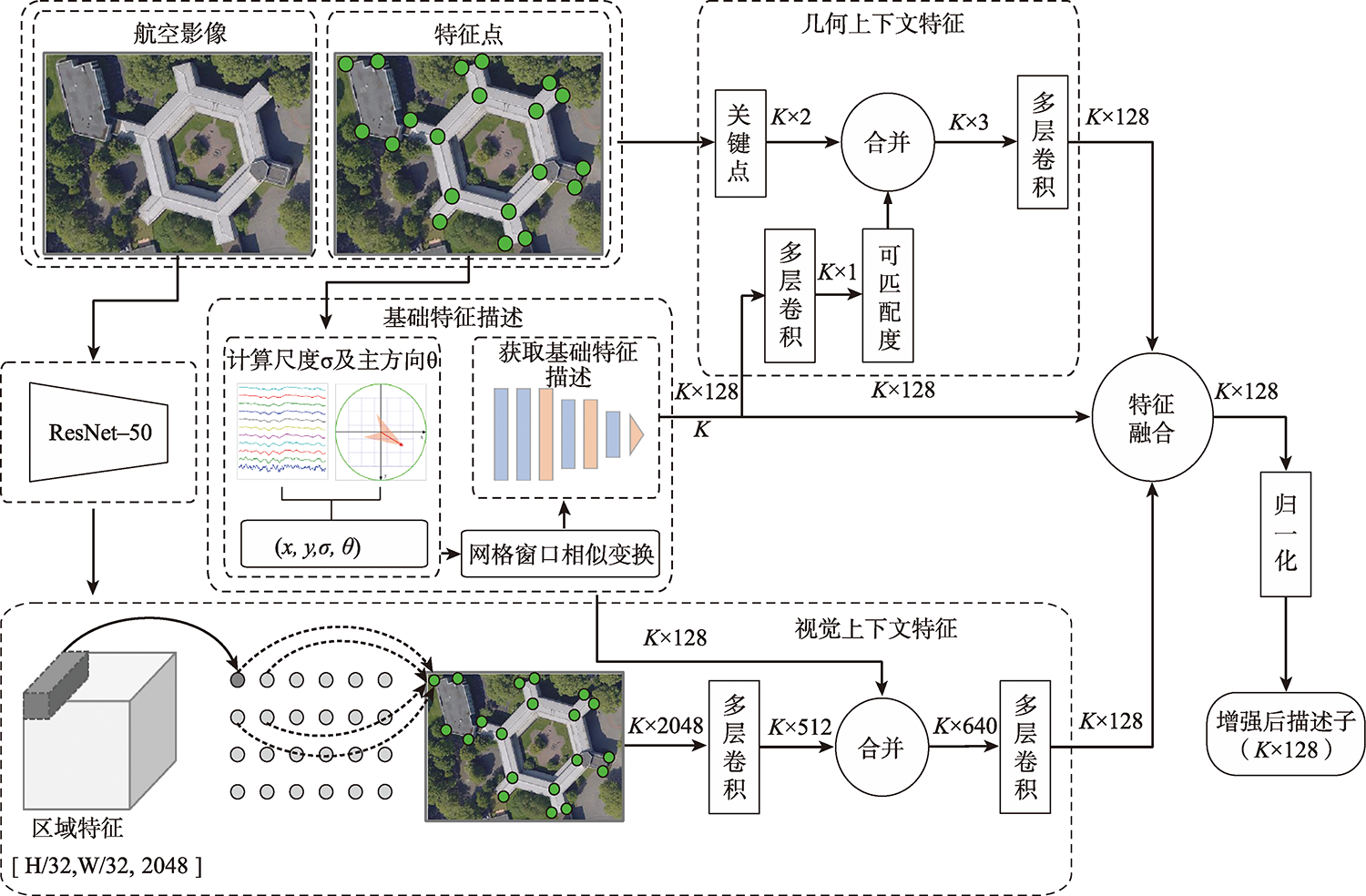
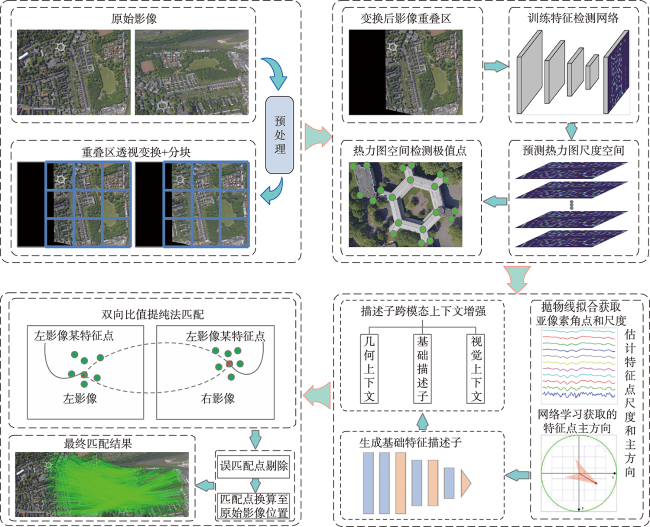
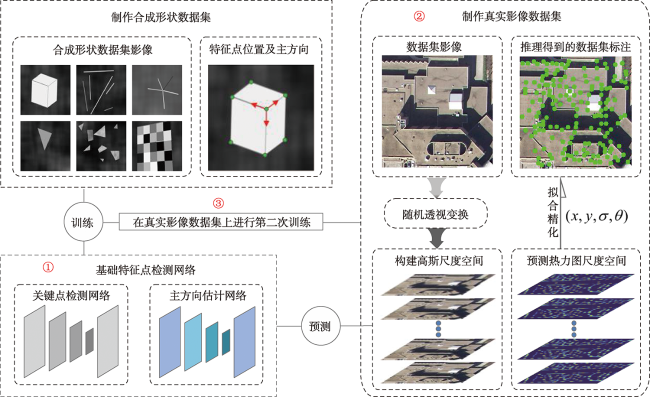
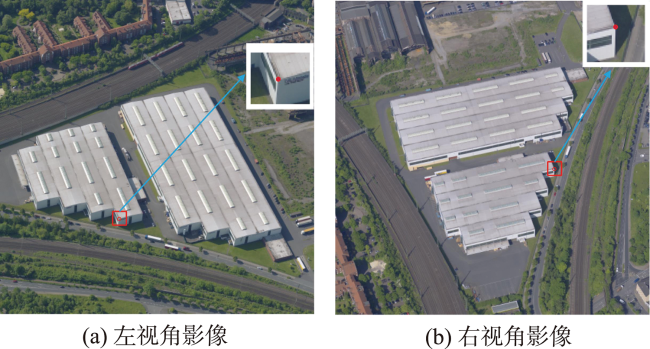
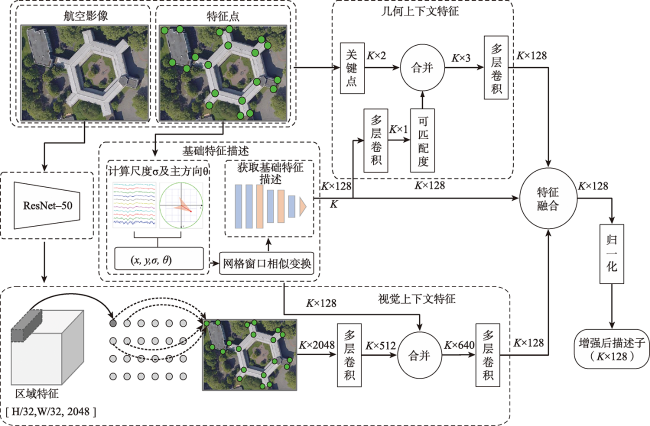
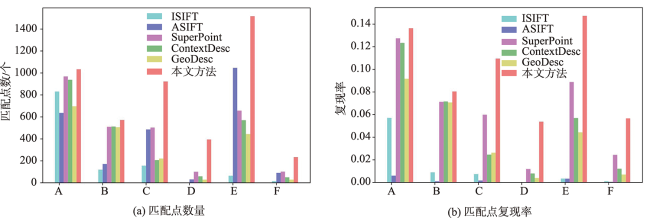
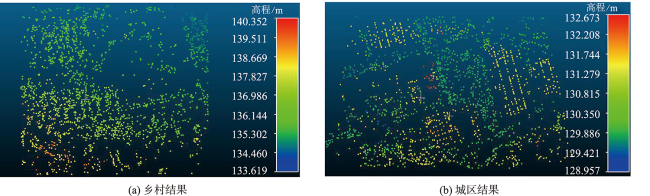
To solve the problem of few points, low recall rate, and low accuracy of feature matching points in oblique image matching by traditional and deep learning methods, we propose a deep learning-based oblique photogrammetry image matching method. Firstly, the oblique image overlapping areas are computed using Position and Orientation System (POS) information. The geometric deformation of the image overlapping areas, caused by large angle change and inconsistent depth of scene, is compensated using perspective transformation. After removing geometric deformation, the transformed images only have small scale rotation changes. Secondly, we trained the feature point detection neural network in two stages to get the multi-scale feature detection network. The pre-trained multi-scale feature detection network is used to infer the Gaussian heat map on the transformed images. The robust sub-pixel feature points are detected in the extreme scale space of the Gauss heat maps, which effectively avoids the influence of image-scale changes. In order to assist feature points description, the feature points scale and direction are obtained based on the pre-trained self-supervised principal feature direction network. In the feature description stage, the scale and rotation invariant GeoDesc descriptor information is obtained by self-supervised feature detection and principal feature direction network. The feature descriptor is enhanced by considering the image geometric and visual context information, which is useful to describe oblique images with large angle change and those with less texture information. Finally, the initial matching points are obtained by a two-stage ratio purification method, which ensures that not many gross errors in the initial points. The mismatches of initial matching points are further removed by fundamental-based Random Sample Consensus (RANSAC) algorithm and geometry-based graph constraint method, which guarantees that the final obtained matching points accuracy is reliable for bundle block adjustment. In order to verify the matching effect of the proposed method, the two typical rural and city area oblique images in ISPRS oblique photogrammetry datasets are selected to qualitatively and quantitatively analyze the matching results of all methods. The experimental results show that our proposed method can obtain lots of uniformly distributed matching points in large scale perspective and poor-texture oblique images. Compared with SIFT, Affine SIFT (ASIFT), SuperPoint, GeoDesc, and ContextDesc algorithms, our proposed method can acquire more robust feature points in scale space of the Gauss heat maps, which is helpful to increase the matching recall rate and accuracy.
YANG Jiabin , FAN Dazhao , YANG Xingbin , JI Song , LEI Rong . Deep Learning based on Image Matching Method for Oblique Photogrammetry[J]. Journal of Geo-information Science, 2021 , 23(10) : 1823 -1837 . DOI: 10.12082/dqxxkx.2021.210305
表1 相机检校参数Tab. 1 Camera calibration parameters |
| 相机 | 焦距/mm | x0/mm | y0/mm | 影像大小/pixel | Roll/(°) | Pitch/(°) | Yaw/(°) |
|---|---|---|---|---|---|---|---|
| 163 | 50.193 | 50.193 | 18.345 | 6132×8176 | -0.110 | 0.119 | 0.276 |
| 148 | 81.938 | 81.938 | 24.186 | 8176×6132 | -0.243 | 45.134 | -0.035 |
| 147 | 82.045 | 82.045 | 24.335 | 8176×6132 | -0.506 | -44.944 | 0.692 |
| 159 | 81.860 | 81.860 | 24.348 | 8176×6132 | 44.926 | 0.210 | 0.009 |
| 145 | 82.037 | 82.037 | 24.419 | 8176×6132 | -45.198 | -0.025 | -0.085 |
表2 局部影像块描述Tab. 2 Comparison of computing time |
| 影像组 | 局部影像块描述 | 视角关系 |
|---|---|---|
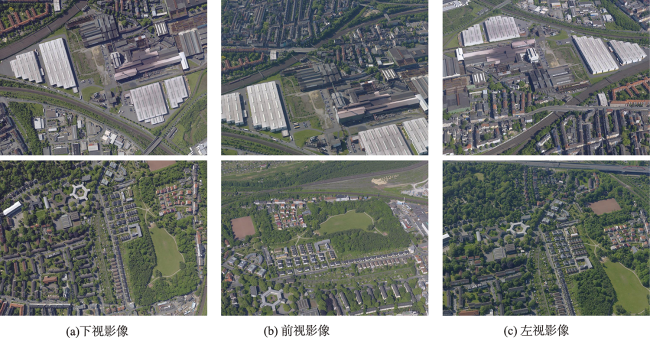
| A | 大型建筑物区域1 | 下视-前视 |
| B | 大视角建筑物区域2 | 前视-左视 |
| C | 建筑物密集区1 | 下视-左视 |
| D | 大视角建筑物密集区2 | 前视-左视 |
| E | 建筑物+平坦区域 | 下视-前视 |
| F | 平坦区域 | 前视-左视 |
图12 城区下视-前视倾斜影像匹配点与匹配连线结果Fig. 12 The matching points and connection line of nadia-front image in urban area |
图13 城区前视-左视倾斜影像匹配点与匹配连线结果Fig. 13 The matching points and connection line of front-left image in urban area |
图14 乡村下视-前视倾斜影像匹配点与匹配连线结果Fig. 14 The matching points and connection line of nadia-front image in rural area |
图15 乡村前视-左视倾斜影像匹配点与匹配连线结果Fig. 15 The matching points and connection line of front-left image in urban area |
表3 匹配点对比结果Tab. 3 Comparison results of matching points |
| 像对 | 本文方法 | COLMAP | Visual SFM | Photoscan | ||
|---|---|---|---|---|---|---|
| 匹配点/提取点 | 误匹配点 | 匹配点 | 匹配点 | 匹配点 | ||
| 乡村下视-前视 | 1589/15 747 | 21 | 115 | 71 | 187 | |
| 乡村前视-左视 | 599/12 134 | 13 | 21 | 22 | 12 | |
| 城区下视-前视 | 1603/9805 | 17 | 466 | 270 | 753 | |
| 城区前视-左视 | 998/14 949 | 8 | 151 | 80 | 302 | |
表4 匹配点误差统计结果Tab. 4 Statistical results of matching points error |
| 倾斜像对 | 误差绝对值均值/像素 | 均方根误差/像素 | |||
|---|---|---|---|---|---|
| X方向 | Y方向 | X方向 | Y方向 | ||
| 城区下视-前视 | 0.3342 | 0.3432 | 0.2381 | 0.2422 | |
| 城区前视-左视 | 0.3206 | 0.3279 | 0.223 | 0.2233 | |
| 乡村下视-前视 | 0.3052 | 0.3088 | 0.2162 | 0.2207 | |
| 乡村前视-左视 | 0.3188 | 0.3146 | 0.2283 | 0.2215 | |
| [1] |
闫利, 费亮, 陈长海, 等. 利用网络图进行高分辨率航空多视影像密集匹配[J]. 测绘学报, 2016, 45(10):1171-1181.
[
|
| [2] |
陈敏, 朱庆, 何海清, 等. 面向城区宽基线立体像对视角变化的结构自适应特征点匹配[J]. 测绘学报, 2019, 48(9):1129-1140.
[
|
| [3] |
|
| [4] |
|
| [5] |
张力, 艾海滨, 许彪, 等. 基于多视影像匹配模型的倾斜航空影像自动连接点提取及区域网平差方法[J]. 测绘学报, 2017, 46(5):554-564.
[
|
| [6] |
赵霞, 朱庆, 肖雄武, 等. 基于同形变换的航空倾斜影像自动匹配方法[J]. 计算机应用, 2015, 35(6):1720-1725.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
龚健雅, 季顺平. 摄影测量与深度学习[J]. 测绘学报, 2018, 47(6):693-704.
[
|
| [26] |
|
| [27] |
肖雄武, 李德仁, 郭丙轩, 等. 一种具有视点不变性的倾斜影像快速匹配方法[J]. 武汉大学学报·信息科学版, 2016, 41(9):1151-1159.
[
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}