
Journal of Geo-information Science >
Building Extraction from High-Resolution Remote Sensing Image based on Res_AttentionUnet
Received date: 2021-01-07
Request revised date: 2021-04-03
Online published: 2022-02-25
Supported by
Fujian Natural Science Foundation(2019J01088)
Copyright
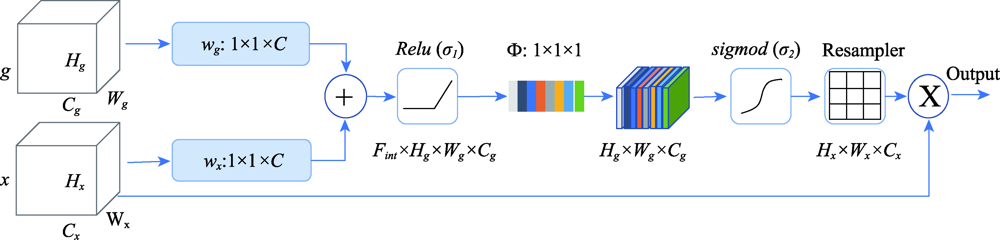
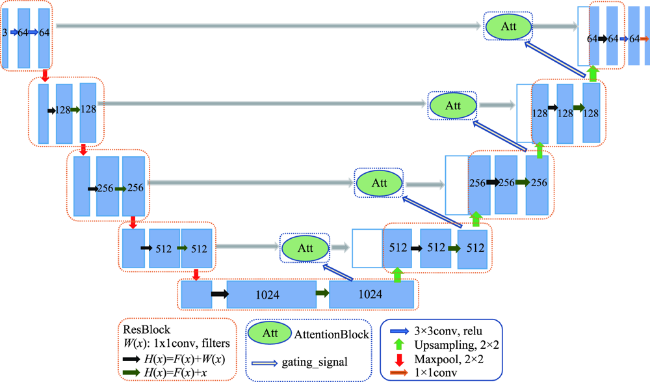
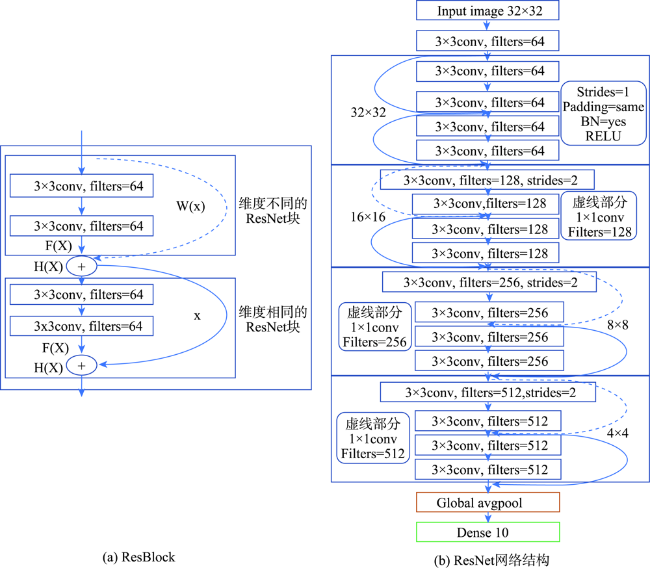
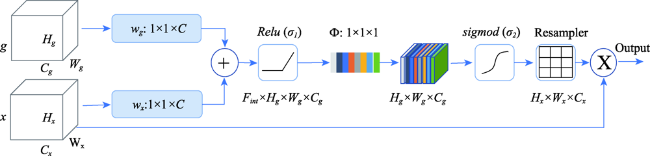
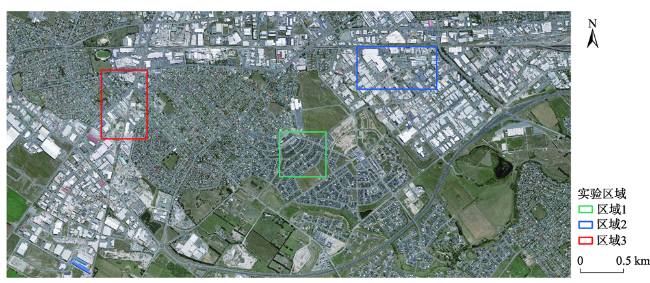
To contribute to the current research of building extraction based on deep learning and high-resolution remote sensing images, we propose an improved Unet network (Res_AttentionUnet), which combines the Residual module of ResNet and Attention mechanism. We apply the Unet network to the extraction of buildings from high-resolution remote sensing images, which effectively improves the extraction accuracy of buildings. The specific optimization method can be divided into three parts. Firstly, in the traditional Unet semantic segmentation network convolution layer, the ResBlock module is added to enhance the extraction of low-level and high-level features. Meanwhile, the Attention mechanism module is added to the network step connection part. Secondly, in the whole net, the ResBlock module enables the convoluted feature map to obtain more bottom information and enhance the robustness of the convolution structure, so as to prevent underfitting. Thirdly, the Attention mechanism can enhance the feature learning of building area pixels, making feature extraction more complete, so as to improve the accuracy of building extraction. In this study, we use the open data set (WHU Building Dataset), provided by Ji Shunping team of Wuhan University, as the experimental data and select three experimental areas with different building characteristics and representativeness. Then, we preprocess the different experimental areas (including sliding, cropping, and image enhancement, etc.). Finally, we use four different network models of Unet, ResUnet, AttentionUnet, and Res_AttentionUnet to extract buildings from three different experimental areas. The experimental results are cross-compared and analyzed. The experimental results show that, compared with the other three networks, the Res_AttentionUnet proposed in this paper has higher accuracy in the building extraction from high-resolution remote sensing images. The average extraction accuracy of Res_AttentionUnet is 95.81%, which is 17.94% higher than the original Unet network, and 2.19% higher than ResUnet (the Unet with only residual module). The results demonstrate that Res_AttentionUnet can significantly improve the effectiveness of building extraction in high-resolution remote sensing images.
LI Chuanlin , HUANG Fenghua , HU Wei , ZENG Jiangchao . Building Extraction from High-Resolution Remote Sensing Image based on Res_AttentionUnet[J]. Journal of Geo-information Science, 2021 , 23(12) : 2232 -2243 . DOI: 10.12082/dqxxkx.2021.210008
表2 混淆矩阵Tab. 2 obfuscation matrix (个) |
| 检测建筑像元数 | 检测非建筑像元数 | |
|---|---|---|
| 实际建筑像元数 | TP | FN |
| 实际非建筑像元数 | FP | TN |
表3 3个试验区滑动裁剪后部分影像与建筑物标签Tab. 3 Images and building labels in three test regions after sliding clipping |
| 区域影像 | 实际参考建筑物Label | |||
|---|---|---|---|---|
| 区域1 |  |  |  |  |
| 区域2 |  |  |  |  |
| 区域3 |  |  |  |  |
表4 原始影像及建筑物标签与增强后影像及建筑物标签Tab. 4 Original images and building labels and enhanced images and building labels |
| 原始影像 | 水平翻转 | 垂直翻转 | 对角镜像 | |
|---|---|---|---|---|
| 影像 |  |  |  |  |
| 参考建筑物标签 |  |  |  |  |
表5 4种网络训练超参数设定Tab. 5 Super parameter setting of four kinds of network training |
| 参数 | 具体设定 |
|---|---|
| Epoch/轮 | 60 |
| Batchsize/张 | 2 |
| 学习率 | 0.001 |
| 优化器 | Adam |
| 迭代次数/次 | 区域1: 20 640 区域2: 31 560 区域3: 30 960 |
图5 4种网络在区域1—3测试影像中的建筑物提取效果注:A为测试影像;B为真实建筑物参考;C为Unet建筑物提取效果;D为AttentionUnet建筑物提取效果;E为ResUnet建筑物提取效果;F为Res_AttentionUnet建筑物提取效果。 Fig. 5 Building extraction results of four networks in Region1-3 experimental areas |
表6 区域1建筑物提取精度指标Tab. 6 Region1 building extraction accuracy index |
| Unet | ResUnet | AttentionUnet | Res_AttentionUnet | |
|---|---|---|---|---|
| Precision | 0.7780 | 0.8787 | 0.9214 | 0.8541 |
| Recall | 0.3743 | 0.8980 | 0.3158 | 0.9173 |
| F1 | 0.5055 | 0.8883 | 0.4704 | 0.8846 |
| Total Precision | 0.6629 | 0.9510 | 0.5407 | 0.9506 |
| IoU | 0.3382 | 0.7990 | 0.3075 | 0.7931 |
| mIoU | 0.4655 | 0.8691 | 0.3652 | 0.9068 |
表7 区域2建筑物提取精度指标Tab. 7 Region 2 Indexes of Building extraction accuracy |
| Unet | ResUnet | AttentionUnet | Res_AttentionUnet | |
|---|---|---|---|---|
| Precision | 0.6344 | 0.9118 | 0.8597 | 0.9600 |
| Recall | 0.8961 | 0.9753 | 0.7209 | 0.9636 |
| F1 | 0.7429 | 0.9425 | 0.7842 | 0.9618 |
| Total Precision | 0.8508 | 0.9621 | 0.8392 | 0.9740 |
| IOU | 0.5910 | 0.8912 | 0.6450 | 0.9264 |
| mIOU | 0.7003 | 0.9183 | 0.7090 | 0.9440 |
表8 区域3建筑物提取精度指标Tab. 8 Region 3 Building extraction accuracy Index |
| Unet | ResUnet | AttentionUnet | Res_AttentionUnet | |
|---|---|---|---|---|
| Precision | 0.7781 | 0.6203 | 0.9403 | 0.8734 |
| Recall | 0.6341 | 0.9770 | 0.3921 | 0.9327 |
| F1 | 0.6988 | 0.7588 | 0.5534 | 0.9021 |
| Total Precision | 0.8223 | 0.8956 | 0.5981 | 0.9498 |
| IOU | 0.5370 | 0.6114 | 0.3826 | 0.8216 |
| mIOU | 0.6566 | 0.7433 | 0.4237 | 0.8782 |
表9 区域 1-3建筑物提取精度指标均值Tab. 9 Region 1-3 average accuracy index of building extraction |
| Unet | ResUnet | AttentionUnet | Res_AttentionUnet | |
|---|---|---|---|---|
| Precision | 0.7302 | 0.8036 | 0.9071 | 0.8958 |
| Recall | 0.6348 | 0.9501 | 0.4763 | 0.9379 |
| F1 | 0.6491 | 0.8632 | 0.6027 | 0.9162 |
| Total Precision | 0.7787 | 0.9362 | 0.6593 | 0.9581 |
| IOU | 0.4887 | 0.7672 | 0.4450 | 0.8470 |
| mIOU | 0.6075 | 0.8436 | 0.4993 | 0.9097 |
| [1] |
杨州, 慕晓冬, 王舒洋, 等. 基于多尺度特征融合的遥感图像场景分类[J]. 光学精密工程, 2018, 26(12):3099-3107.
[
|
| [2] |
付秀丽, 黎玲萍, 毛克彪, 等. 基于卷积神经网络模型的遥感图像分类[J]. 高技术通讯, 2017, 27(3):203-212.
[
|
| [3] |
苏健民, 杨岚心, 景维鹏. 基于U-Net的高分辨率遥感图像语义分割方法[J]. 计算机工程与应用, 2019, 55(7):207-213.
[
|
| [4] |
|
| [5] |
|
| [6] |
顾炼, 许诗起, 竺乐庆. 基于FlowS-Unet的遥感图像建筑物变化检测[J]. 自动化学报, 2020, 46(6):1291-1300.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
刘文涛, 李世华, 覃驭楚. 基于全卷积神经网络的建筑物屋顶自动提取[J]. 地球信息科学学报, 2018, 20(11):1562-1570.
[
|
| [12] |
张华博. 基于深度学习的图像分割研究与应用[D]. 成都:电子科技大学, 2018.
[
|
| [13] |
唐文博. 基于卷积神经网络的高分辨率多光谱遥感图像上的城区建筑物变化检测技术[D]. 杭州:浙江大学, 2019.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
季顺平, 魏世清. 遥感影像建筑物提取的卷积神经元网络与开源数据集方法[J]. 测绘学报, 2019, 48(4):448-459.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}