
Journal of Geo-information Science >
Parallel Ripley's K Function based on Hilbert Spatial Partitioning and Geohash Indexing
Received date: 2021-08-04
Revised date: 2021-08-27
Online published: 2022-03-25
Supported by
National Key Research and Development Program of China(2018YFC0809806)
National Key Research and Development Program of China(2017YFB0503704)
National Natural Science Foundation of China(41971349)
National Natural Science Foundation of China(42090010)
Copyright
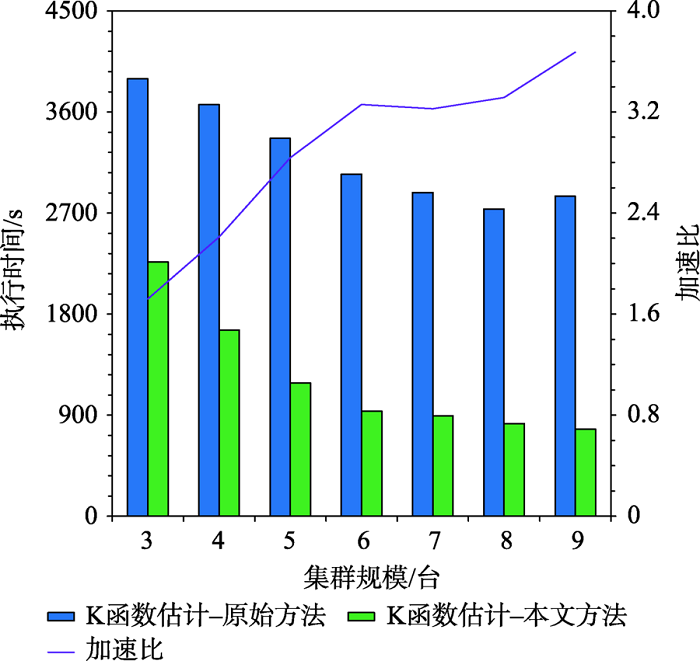
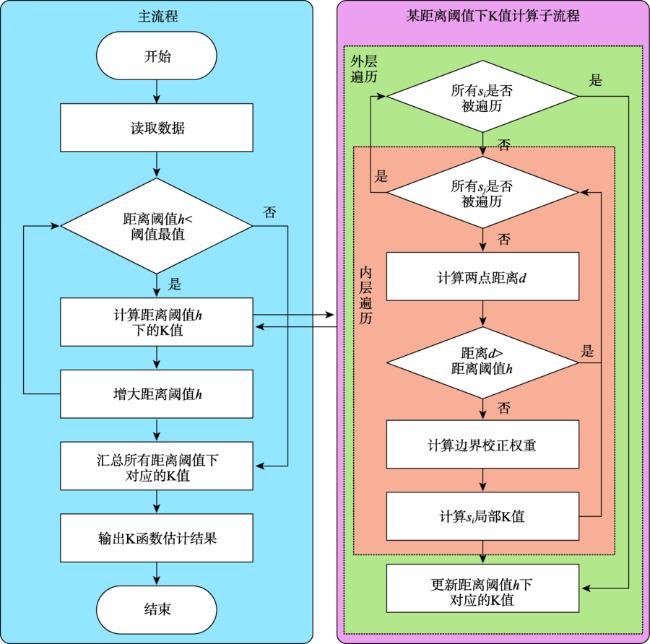
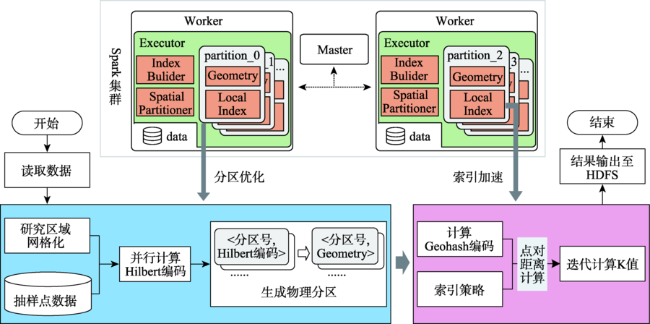
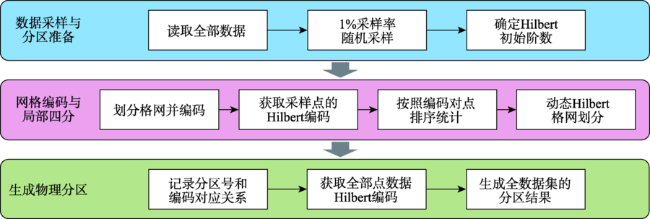
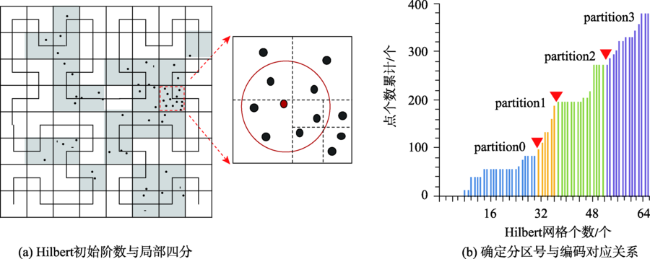
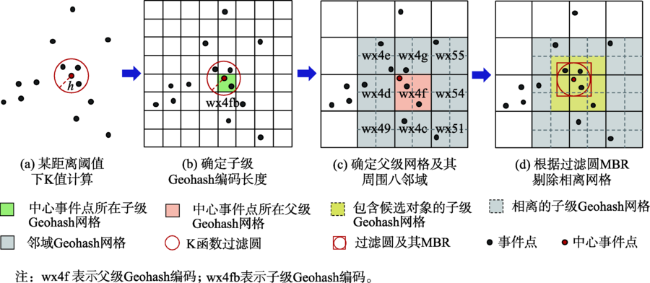
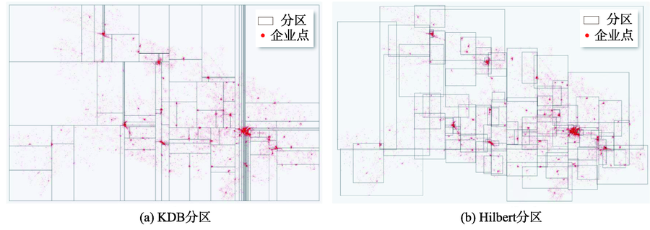
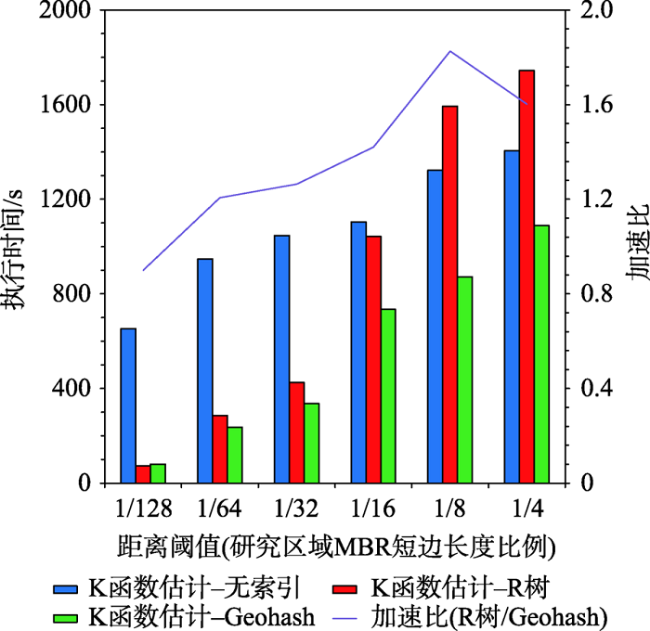
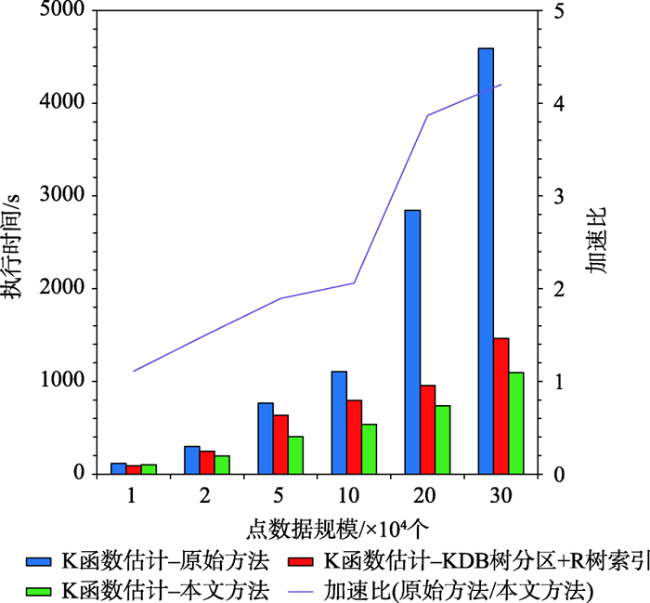
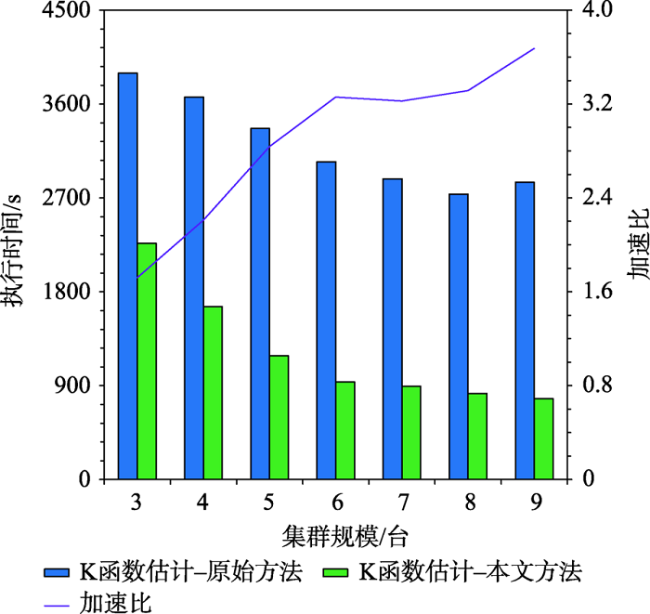
As a second-order analysis method of spatial point patterns, Ripley's K function (K function for short) uses distance as an independent variable to detect the distribution patterns of points under different spatial scales, which has been widely used in distinct fields such as ecology, economics, and geography. However, the applications of K function are limited due to the sharply increased computational cost of nested traversals on the point-pair distance measurements in both estimation and simulation phases when the point size getting larger. Therefore, the optimization of algorithm workflow and parallel acceleration have become the key technologies for tackling the performance bottleneck and computability problem of K function. Among these solutions, hash-based partitioning has been widely adopted in parallel computing frameworks for enabling data decomposition, while R-tree indexes have been proposed to reduce the computational cost of point-pair distance measurements by using spatial query instead. However, default hash-based partitioning methods ignore the spatial proximity of data distributions, while R-tree indexes fail to save query time of neighboring points under large spatial distance threshold comparing with pointwise distance calculation. In order to address these issues, this paper proposes an acceleration method for K function based on the space filling curves. Specifically, the Hilbert curve is adopted to achieve spatial partitioning, which reduces the data tilt and communication cost between partitions by better considering the spatial proximity. Upon the partition result, local indexing based on Geohash code is further developed to improve the spatial indexing strategy, which embeds spatial information in codes for achieving quick distance filtering, in turn accelerates the pointwise distance measurements. To verify the effectiveness of the proposed method, it is compared with two optimization methods adopted in previous studies, i.e., default partition without indexing, and KDB-tree partition with R-tree indexing, by analyzing the calculation time of K function for point of interests (POIs) of enterprise registration data in Hubei province, China under different data sizes, spatial distance thresholds, and computing nodes in a computing cluster. Experimental results indicate that the time cost of the proposed method is about 1/4 of that for default partition without indexing under the data scale of 300 000 points. Besides, the speedup ratio is larger than 3.6 times under 9 nodes. Therefore, the proposed method can improve performance of K function effectively in a distributed environment and has a promising scalability and could provide a reference for accelerating other spatial patterns analysis algorithms as well.
KANG Yangxiao , GUI Zhipeng , DING Jinchen , WU Jinghang , WU Huayi . Parallel Ripley's K Function based on Hilbert Spatial Partitioning and Geohash Indexing[J]. Journal of Geo-information Science, 2022 , 24(1) : 74 -86 . DOI: 10.12082/dqxxkx.2022.210457
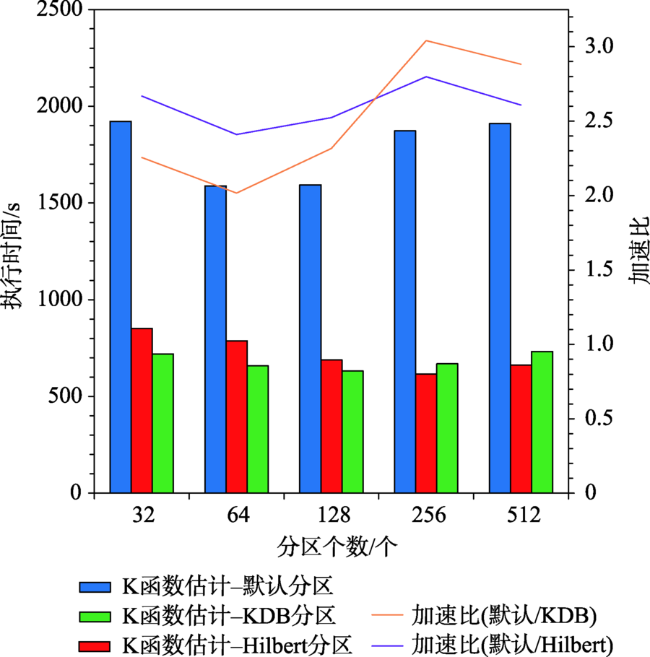
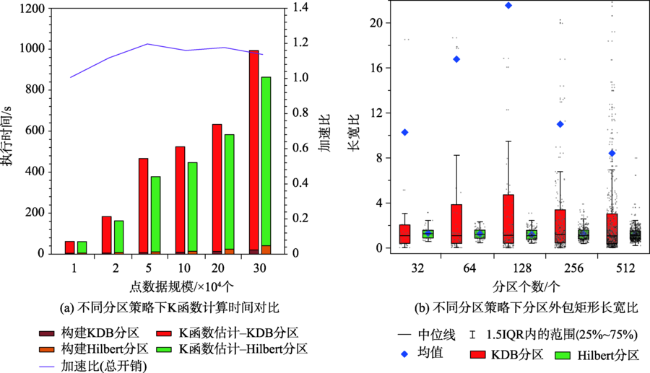
图7 不同分区策略下K函数计算时间随分区规模增大的对比Fig. 7 Comparison of execution times of Ripley's K functions equipped with different partition methods as the partition size increases |
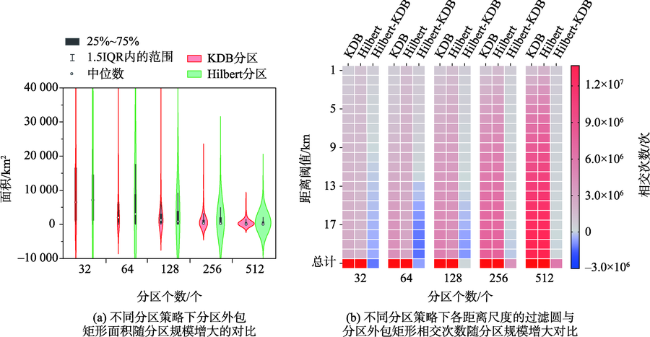
图9 不同分区策略下K函数计算时间及分区长宽比对比Fig. 9 Comparison of execution times of Ripley's K functions and the length-width ratios of partitions for different partition methods |
| [1] |
周成虎. 点模式分析[J]. 地理科学进展, 1989, 8(2):8-11.
[
|
| [2] |
|
| [3] |
|
| [4] |
李智, 李卫红. 点模式条件下的犯罪嫌疑人时空同现模式挖掘与分析[J]. 地球信息科学学报, 2018, 20(6):827-836.
[
|
| [5] |
曾璇, 崔海山, 刘毅华. 基于网络空间点模式的餐饮店空间格局分析[J]. 地球信息科学学报, 2018, 20(6):837-843.
[
|
| [6] |
李清泉, 李德仁. 大数据GIS[J]. 武汉大学学报·信息科学版, 2014, 39(6):641-644.
[
|
| [7] |
崔邹森. 基于交叉Ripley’s K函数的点模式Web可视化分析系统设计与实现[D]. 武汉:武汉大学, 2020.
[
|
| [8] |
|
| [9] |
|
| [10] |
王源. 面向海量点模式分析的时空Ripley's K函数优化与加速[D]. 武汉:武汉大学, 2019.
[
|
| [11] |
向隆刚, 王德浩, 龚健雅. 大规模轨迹数据的Geohash编码组织及高效范围查询[J]. 武汉大学学报·信息科学版, 2017, 42(1):21-27.
[
|
| [12] |
|
| [13] |
|
| [14] |
左尧, 王少华, 钟耳顺, 等. 高性能GIS研究进展及评述[J]. 地球信息科学学报, 2017, 19(4):437-446.
[
|
| [15] |
邱强, 秦承志, 朱效民, 等. 全空间下并行矢量空间分析研究综述与展望[J]. 地球信息科学学报, 2017, 19(9):1217-1227.
[
|
| [16] |
|
| [17] |
高旭, 桂志鹏, 隆玺, 等. KDSG-DBSCAN:一种基于K-D Tree和Spark GraphX的高性能DBSCAN算法[J]. 地理与地理信息科学, 2017, 33(6):1-7,封3.
[
|
| [18] |
|
| [19] |
|
| [20] |
李绍俊, 钟耳顺, 王少华, 等. 基于状态转移矩阵的Hilbert码快速生成算法[J]. 地球信息科学学报, 2014, 16(6):846-851.
[
|
| [21] |
崔登吉. 空间分布模式驱动的空间数据组织与索引研究[D]. 南京:南京师范大学, 2016.
[
|
| [22] |
|
| [23] |
向隆刚, 高萌, 王德浩, 等. Geohash-Trees:一种用于组织大规模轨迹的自适应索引[J]. 武汉大学学报·信息科学版, 2019, 44(3):436-442.
[
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
湛东升, 张文忠, 党云晓, 等. 北京市公共服务设施空间集聚特征分析[J]. 经济地理, 2018, 38(12):76-82.
[
|
| [28] |
|
| [29] |
|
| [30] |
Google. S2 Geometry[EB/OL]. http://s2geometry.io/, 2019-12-18.
|
| [31] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}