
Journal of Geo-information Science >
VCS Optimization Method of Vatti Algorithm for Polygon Overlay and Parallelization Using GPU
Received date: 2021-07-18
Request revised date: 2021-08-19
Online published: 2022-05-25
Supported by
National Natural Science Foundation of China(42171413)
National Key R&D Program of China(2017YFB0503500)
Natural Science Foundation of Shandong Province(ZR2020MD015)
Natural Science Foundation of Shandong Province(ZR2020MD018)
Major Scientific And Technological Innovation Projects of Shandong Province(2019JZZY020103)
Young Teacher Development Support Program of Shandong University of Technology(4072-115016)
Copyright
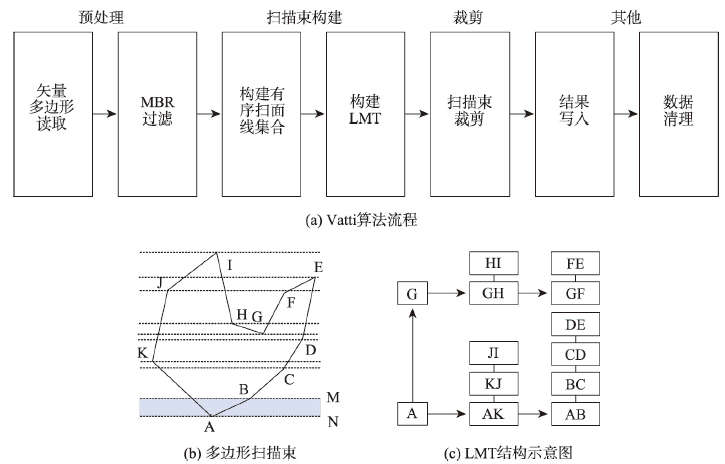
Vatti algorithm is one of the widely used vector polygon clipping algorithms. In the process of intersection calculation based on the construction of scanning beams, the data structure of binary tree and recursive calculation method lead to an obvious increase in time consumption when dealing with polygons with plenty of vertices. The calculation efficiency of the algorithm is significantly affected by the boundary vertex number of the overlapping polygons. Aiming at the efficiency improvement of the time-consuming scanning beam construction process of Vatti algorithm, this paper proposes an optimization approach based on polygon boundary vertex pre-sorting method, which is named VCS (Vertex Coordinate Pre-Sorting) method, and realizes a fine-grained level parallel Vatti algorithm on GPU device based on CUDA. The VCS method replaces the original binary tree data structure of Vatti algorithm with a double linked list, and obtains an obvious efficiency improvement on polygon boundary vertex information searching process with a smaller additional storage space. In GPU environment, the bitonic sorting method is used to sort the elements of polygon boundary vertex array in parallel and filter out the valid values, which overcomes the defect of low efficiency caused by the original algorithm using binary tree data structure. Experimental results show that the improved algorithm presents higher efficiency with the same calculation accuracy as the original algorithm. When the number of polygon vertices is 920 000 and the number of threads in each thread block is 32, compared with the serial algorithm which builds scan beams using CPU, the VCS optimization method with GPU-based parallel polygon clipping algorithm obtains a relative acceleration ratio of 39.6 times, and the efficiency of vector polygon superposition analysis algorithm is improved by 4.9 times overall.
ZHANG Zhikun , FAN Junfu , XU Shaobo , CHEN Zheng . VCS Optimization Method of Vatti Algorithm for Polygon Overlay and Parallelization Using GPU[J]. Journal of Geo-information Science, 2022 , 24(3) : 437 -447 . DOI: 10.12082/dqxxkx.2022.210409
表1 实验数据详细信息Tab. 1 Details of experimental data |
| 年份 | 多边形数/个 | 顶点数/个 | 单个多边形最大顶点数/个 |
|---|---|---|---|
| 2009 | 9129 | 856 238 | 9475 |
| 2010 | 9383 | 832 827 | 9472 |
图3 原始算法与VCS优化方法的扫描线赋值、边界线位置查询过程Fig. 3 The process of scan line assignment and boundary line position query between the original algorithm and VCS optimization method |
表2 实验环境配置Tab. 2 Experimental environment configuration |
| 设备型号 | CPU | GPU | CUDA处理器核心数/个 | 显存位宽 /位 | 显存频率 / MHz | 内存 /GB | 外部存储 / GB SSD | 操作系统 | 编译器 |
|---|---|---|---|---|---|---|---|---|---|
| HP Pavilion 15-ak004TX | Intel Core i7-6700HQ四核2.6 GHz | NVIDIA GTX 950 M | 640 | 128 | 1000 | 8 | 128 | Windows 10 | Visual Studio 2017 |
| [1] |
王结臣, 王豹, 胡玮, 等. 并行空间分析算法研究进展及评述[J]. 地理与地理信息科学, 2011, 27(6):1-5.
[
|
| [2] |
左尧, 王少华, 钟耳顺, 等. 高性能GIS研究进展及评述[J]. 地球信息科学学报, 2017, 19(4):437-446.
[
|
| [3] |
赵银利, 范俊甫, 王崇倡. GIS典型几何计算算法的并行化及优化研究[J]. 测绘与空间地理信息, 2017, 40(7):163-166.
[
|
| [4] |
邱强, 秦承志, 朱效民, 等. 全空间下并行矢量空间分析研究综述与展望[J]. 地球信息科学学报, 2017, 19(9):1217-1227.
[
|
| [5] |
范俊甫. 并行化矢量多边形叠加算法研究[J]. 测绘学报, 2016, 45(4):502.
[
|
| [6] |
彭志云, 王惜民, 赖美森, 等. 并行计算时代:基于CUDA的通用GPU计算的发展[J]. 科技与企业, 2016, 11:80.
[
|
| [7] |
姚晓, 邱强, 肖茁建, 等. Spark框架下矢量多边形求交算法研究[J]. 高技术通讯, 2018, 28(6):500-507.
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
苏诚, 韩俊刚. Sutherland-Hodgman裁剪算法的改进[J]. 西安邮电大学学报, 2013, 18(3):80-82.
[
|
| [13] |
白晨. 一种任意多边形的裁剪算法[D]. 电子科技大学, 2012.
[
|
| [14] |
刘勇奎, 高云, 黄有群. 一个有效的多边形裁剪算法[J]. 软件学报, 2003, 14(4):845-856.
[
|
| [15] |
范俊甫. 并行化矢量多边形叠加算法研究[D]. 北京:中国科学院大学, 2014.
[
|
| [16] |
彭杰, 刘南, 唐远彬, 等. 一种基于交点排序的高效多边形裁剪算法[J]. 浙江大学学报(理学版), 2012, 39(1):107-111,122.
[
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
范俊甫, 孔维华, 马廷, 等. RaPC:一种基于栅格化思想的多边形裁剪算法及其误差分析[J]. 测绘学报, 2015, 44(3):338-345.
[
|
| [25] |
|
| [26] |
张鹏, 俞宵, 马子云, 等. 统一计算设备架构的D8算法并行化研究[J]. 测绘科学, 2020, 45(3):163-169.
[
|
| [27] |
吴旭桥, 吴烨, 陈荦, 等. 面向大规模DEM数据的并行填挖算法[J]. 地理信息世界, 2019, 26(6):21-25.
[
|
| [28] |
|
| [29] |
|
| [30] |
陈达伦, 陈荣国, 谢炯. 基于MPP架构的并行空间数据库原型系统的设计与实现[J]. 地球信息科学学报, 2016, 18(2):151-159.
[
|
| [31] |
范俊甫, 马廷, 周成虎, 等. 几何部件缓冲区域合并的Buffer算法及其并行优化方法[J]. 测绘学报, 2014, 43(9):969-975.
[
|
| [32] |
范俊甫, 马廷, 周成虎, 等. 基于集群MPI的图层级多边形并行合并算法[J]. 地球信息科学学报, 2014, 16(4):517-523.
[
|
| [33] |
|
| [34] |
|
| [35] |
张林波. 并行计算导论[M]. 北京: 清华大学出版社, 2006.
[
|
| [36] |
|
| [37] |
|
/
| 〈 |
|
〉 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}