
Journal of Geo-information Science >
A Lightweight Dual Attention and Feature Compensated Residual Network Model for Road Extraction from High-Resolution Remote Sensing Images
Received date: 2021-09-30
Request revised date: 2021-12-03
Online published: 2022-07-25
Supported by
National Natural Science Foundation of China(42071446)
Commissioning Project of Unicom (Fujian) Industrial Internet Co., Ltd.,(JC21-3502-2020-000559)
Copyright
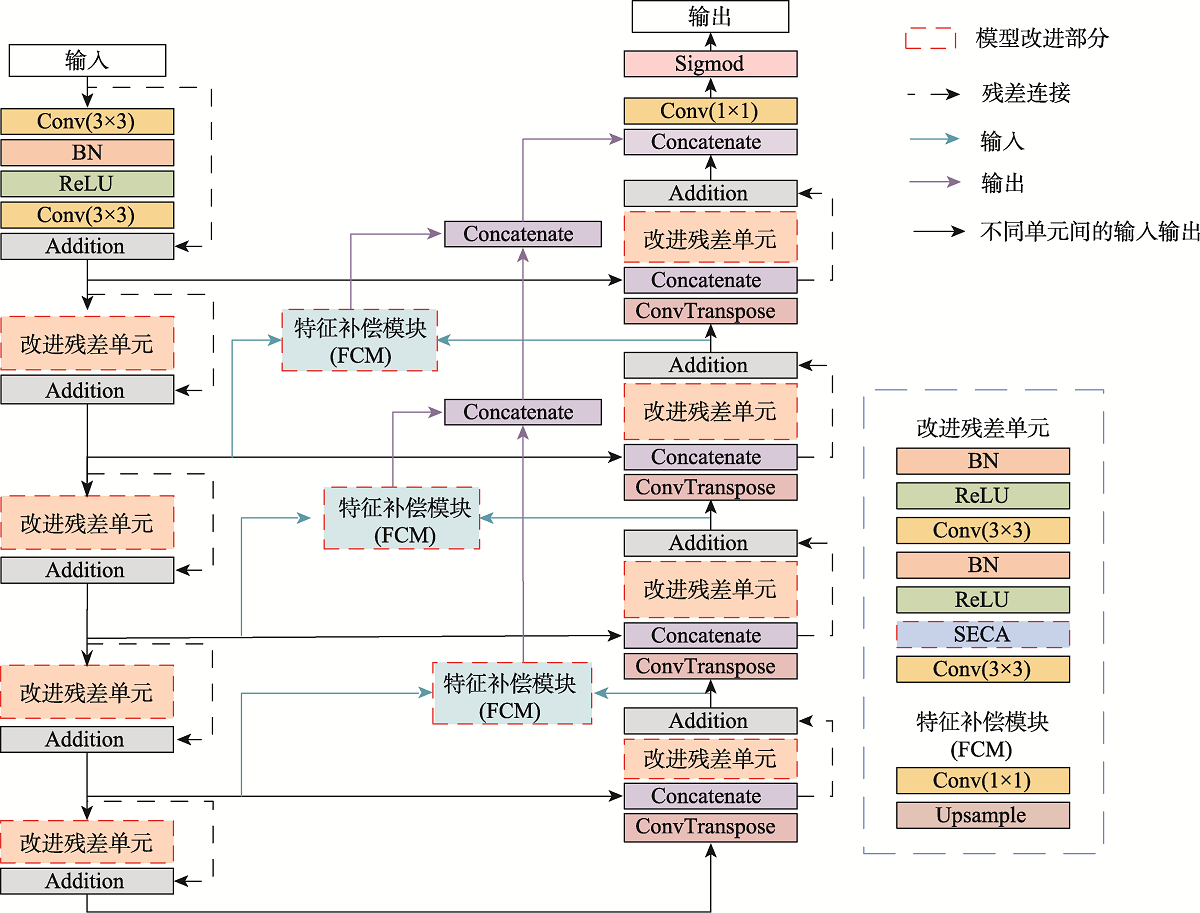
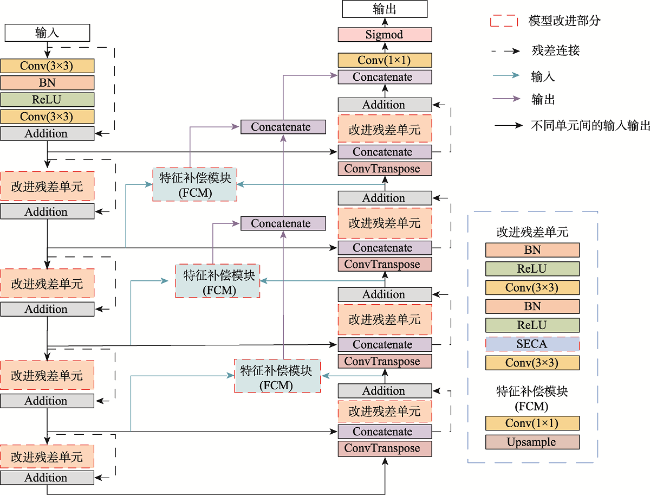
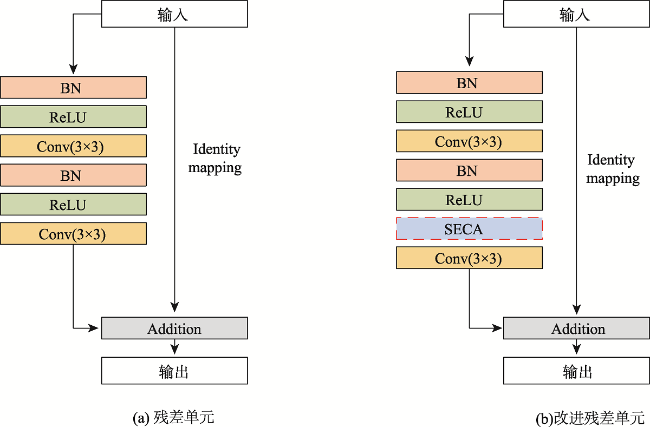
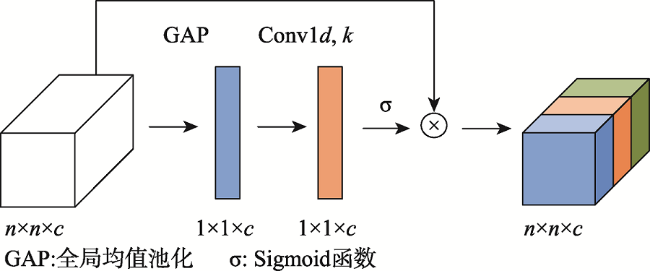
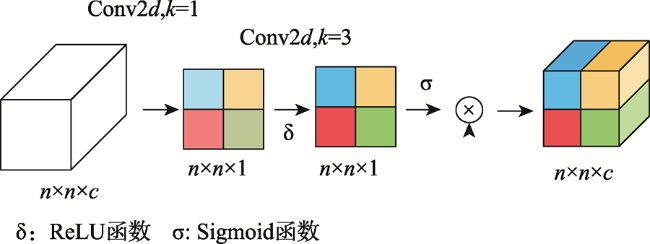
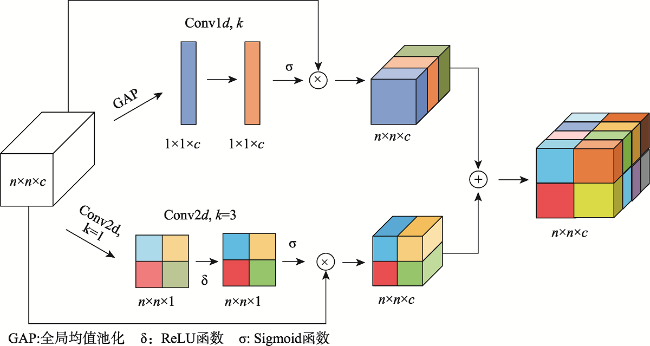
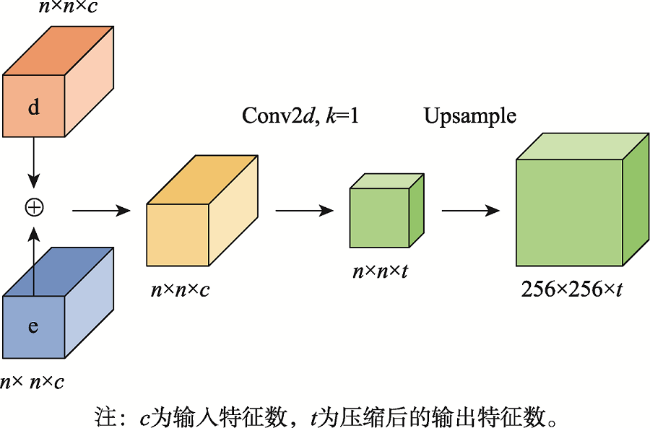
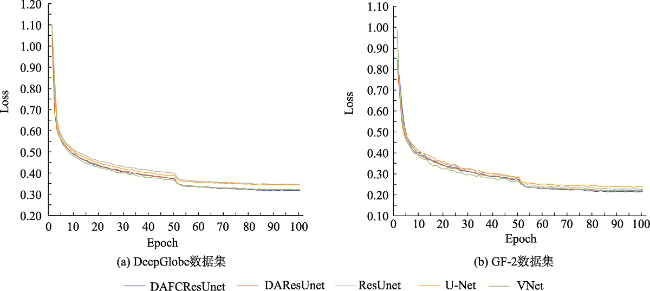
Aiming at the problem that the background of high-resolution remote sensing images is complex and road extraction is easily disturbed by background information such as shadows, buildings, and railroads, the DAFCResUnet model with lightweight dual attention and feature compensation mechanism is proposed in this study. The model is based on ResUnet and achieves a balance between model performance and spatiotemporal complexity by adding lightweight dual attention and feature compensation modules. The dual attention module enhances the feature extraction capability of the model, and the feature compensation module can fuse the road features from deep and shallow layers in the network. The experimental results using DeepGlobe and GF-2 road datasets show that the IoU of the DAFCResUnet model can reach 0.6713, 0.8033, respectively, and the F1-score is 0.7402, 0.8507, respectively. The overall accuracy of the model is higher than that of U-Net, ResUnet, and VNet models. Compared with the U-Net and ResUnet models, the DAFCResUnet model only increases a small amount of computation and number of parameters, but the IoU and F1-score are improved substantially. Compared with the VNet model, the DAFCResUnet model achieves a higher accuracy with much lower computation and smaller number of parameters, and the model has advantages in both accuracy and spatiotemporal complexity. Compared with the other models, the DAFCResUnet model has stronger feature extraction and anti-interference ability, which can better solve the commission and omission caused by interfering objects on the road, ground features similar to roads, tree shade or shadow shading, etc.
CHEN Zhen , CHEN Yunzhi , WU Ting , LI Jiayou . A Lightweight Dual Attention and Feature Compensated Residual Network Model for Road Extraction from High-Resolution Remote Sensing Images[J]. Journal of Geo-information Science, 2022 , 24(5) : 949 -961 . DOI: 10.12082/dqxxkx.2022.210597
表1 DAFCResUnet网络各层的参数及输出特征图尺寸Tab. 1 Parameters and output feature map size of each layer in DAFCResUnet network |
| 编码器 | 解码器 | ||||||
|---|---|---|---|---|---|---|---|
| 层号 | 网络层 | 步长 | 输出特征图尺寸 | 层号 | 网络层 | 步长 | 输出特征图尺寸 |
| 1 | Conv 3 3 | 1 | 256 256 32 | 1 | T-Conv 2 2 | 2 | 32 32 256 |
| 2 | Conv 3 3 | 1 | 256 256 32 | 2 | Conv 3 3 | 1 | 32 32 256 |
| 3 | Conv 3 3 | 2 | 128 128 64 | 3 | Conv 3 3 | 1 | 32 32 256 |
| 4 | Conv 3 3 | 1 | 128 128 64 | 4 | T-Conv 2 2 | 2 | 64 64 128 |
| 5 | Conv 3 3 | 2 | 64 64 128 | 5 | Conv 3 3 | 1 | 64 64 128 |
| 6 | Conv 3 3 | 1 | 64 64 128 | 6 | Conv 3 3 | 1 | 64 64 128 |
| 7 | Conv 3 3 | 2 | 32 32 256 | 7 | T-Conv 2 2 | 2 | 128 128 64 |
| 8 | Conv 3 3 | 1 | 32 32 256 | 8 | Conv 3 3 | 1 | 128 128 64 |
| 9 | Conv 3 3 | 2 | 16 16 512 | 9 | Conv 3 3 | 1 | 128 128 64 |
| 10 | Conv 3 3 | 1 | 16 16 512 | 10 | T-Conv 2 2 | 2 | 256 256 32 |
| 11 | Conv 3 3 | 1 | 256 256 32 | ||||
| 12 | Conv 3 3 | 1 | 256 256 32 | ||||
| 13 | Conv 1 1 | 1 | 256 256 1 | ||||
注:输入图像尺寸为256×256×3;Conv 3 3代表卷积核为3的卷积层;T-Conv 2 2代表卷积核为2的反卷积层。 |
表2 在DeepGlobe测试集上的精度对比Tab. 2 Accuracy comparison on DeepGlobe test set |
| 模型 | IoU | Recall | Precision | F1-score | FLOPs(G) | Params(M) |
|---|---|---|---|---|---|---|
| U-Net[12] | 0.6521 | 0.7750 | 0.8044 | 0.7894 | 13.73 | 7.77 |
| ResUnet[10] | 0.6498 | 0.7748 | 0.8011 | 0.7877 | 14.43 | 8.12 |
| VNet[17] | 0.6686 | 0.7938 | 0.8091 | 0.8014 | 44.85 | 36.00 |
| DAResUnet | 0.6690 | 0.7914 | 0.8122 | 0.8016 | 14.44 | 8.12 |
| DAFCResUnet | 0.6713 | 0.7982 | 0.8085 | 0.8033 | 14.46 | 8.12 |
表3 在GF-2测试集上的精度对比Tab. 3 Accuracy comparison on GF-2 test set |
| 模型 | IoU | Recall | Precision | F1-score | FLOPs(G) | Params(M) |
|---|---|---|---|---|---|---|
| U-Net[12] | 0.7182 | 0.8050 | 0.8695 | 0.8360 | 13.73 | 7.77 |
| ResUnet[10] | 0.7272 | 0.8109 | 0.8756 | 0.8420 | 14.43 | 8.12 |
| VNet[17] | 0.7330 | 0.8196 | 0.8741 | 0.8460 | 44.85 | 36.00 |
| DAResUnet | 0.7383 | 0.8258 | 0.8745 | 0.8494 | 14.44 | 8.12 |
| DAFCResUnet | 0.7402 | 0.8226 | 0.8808 | 0.8507 | 14.46 | 8.12 |
| [1] |
赫晓慧, 李代栋, 李盼乐, 等. 基于EDRNet模型的高分辨率遥感影像道路提取[J]. 计算机工程, 2021, 47(9):297-303,312.
[
|
| [2] |
贺浩, 王仕成, 杨东方, 等. 基于Encoder-Decoder网络的遥感影像道路提取方法[J]. 测绘学报, 2019, 48(3):330-338.
[
|
| [3] |
罗庆洲, 尹球, 匡定波. 光谱与形状特征相结合的道路提取方法研究[J]. 遥感技术与应用, 2007(3):339-344.
[
|
| [4] |
吴学文, 徐涵秋. 一种基于水平集方法提取高分辨率遥感影像中主要道路信息的算法[J]. 宇航学报, 2010, 31(5):1495-1502.
[
|
| [5] |
赵文智, 雒立群, 郭舟, 等. 光谱特征分析的城市道路提取[J]. 光谱学与光谱分析, 2015, 35(10):2814-2819.
[
|
| [6] |
王建华, 秦其明, 高中灵, 等. 加入空间纹理信息的遥感图像道路提取[J]. 湖南大学学报(自然科学版), 2016, 43(4):153-156.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
金飞, 王龙飞, 刘智, 等. 一种双U-Net的遥感影像道路提取方法[J]. 测绘科学技术学报, 2019,36(4):377-381+387.
[
|
| [17] |
|
| [18] |
|
| [19] |
肖昌城, 吴锡. 基于门控卷积残差网络的卫星图像道路提取[J]. 计算机应用研究, 2021, 38(12):3820-3825.
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
宋廷强, 刘童心, 宗达, 等. 改进U-Net网络的遥感影像道路提取方法研究[J]. 计算机工程与应用, 2021, 57(14):209-216.
[
|
| [25] |
李君. 基于多尺度卷积神经网络的遥感图像道路提取研究[D]. 湘潭:湘潭大学, 2019.
[
|
| [26] |
罗咏潭. 基于深度学习的遥感图像道路提取与语义分割[D]. 厦门:厦门大学, 2019.
[
|
| [27] |
|
| [28] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}