
Journal of Geo-information Science >
Crowd Density Estimation Method Considering Video Geographic Mapping
Received date: 2021-09-15
Revised date: 2021-11-19
Online published: 2022-08-25
Supported by
National Natural Science Foundation of China(41401436)
Natural Science Foundation of Henan Province(202300410345)
Nanhu Scholars Program for Young Scholars of XYNU
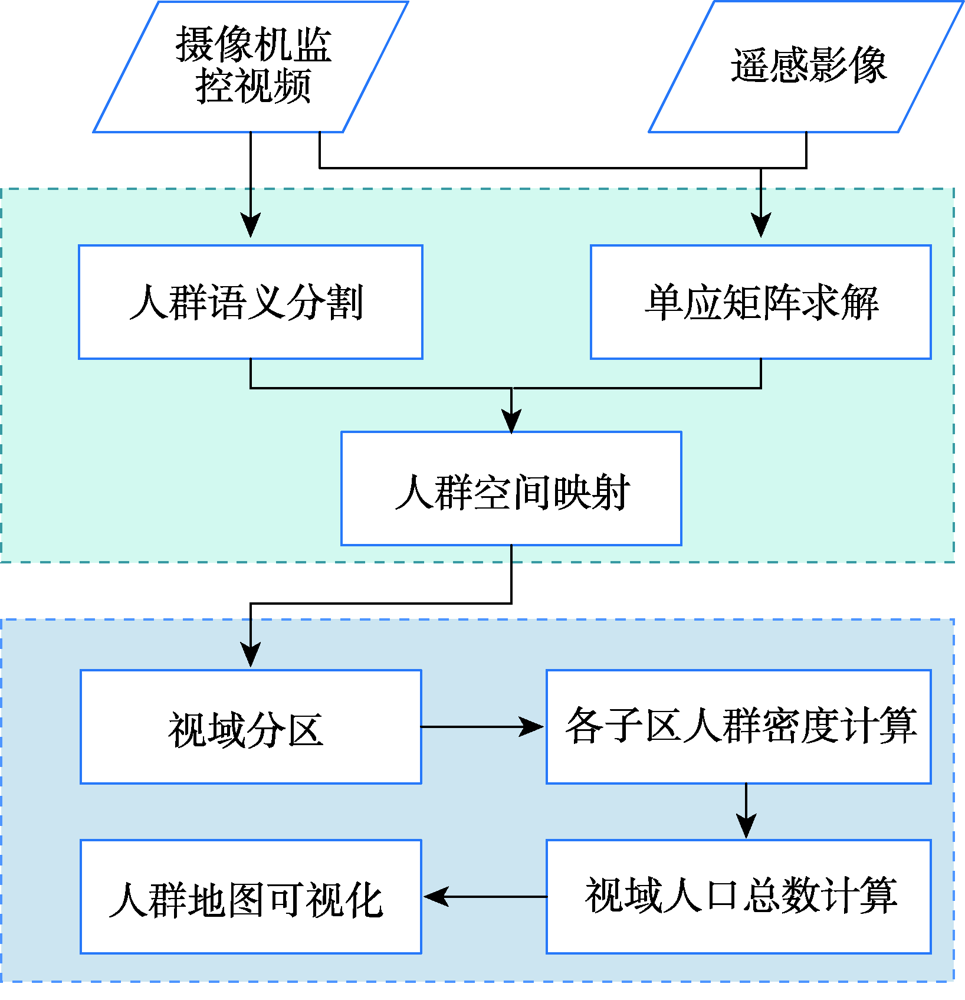
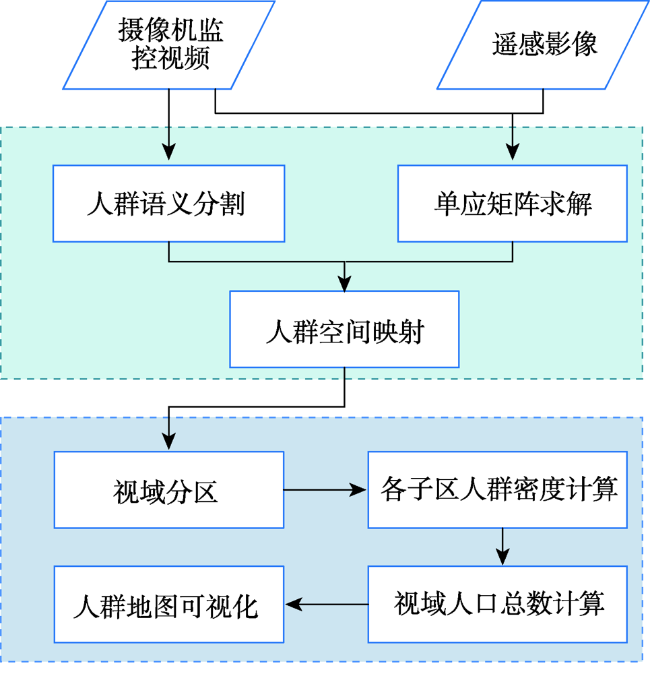
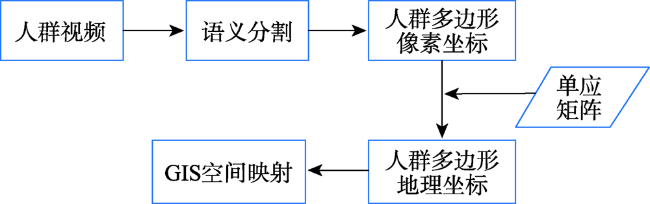
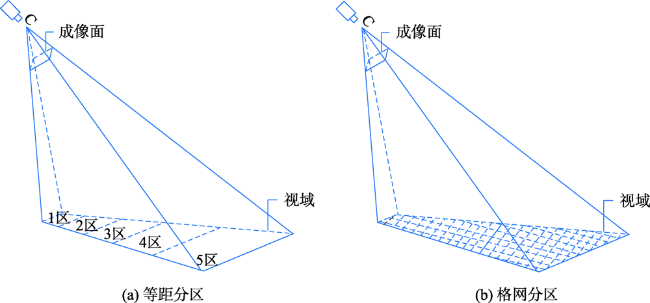
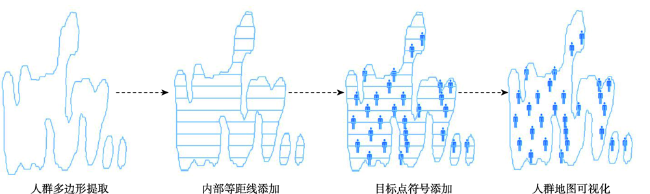
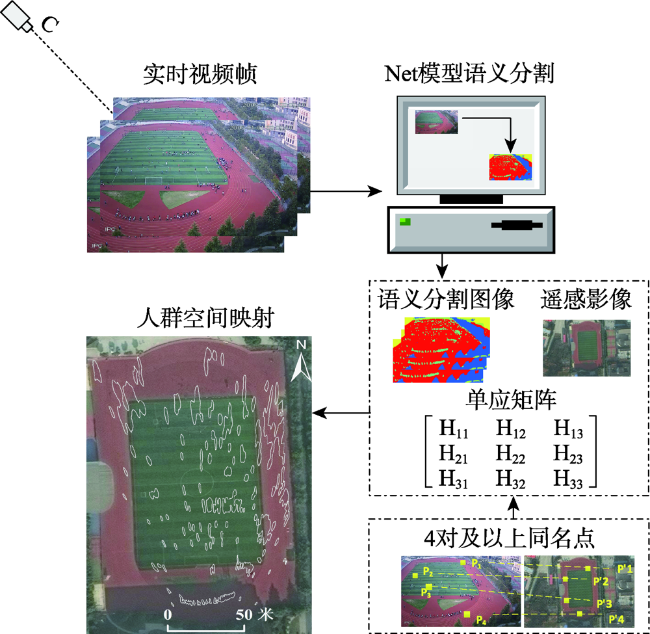
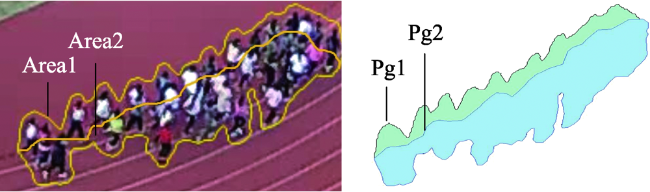
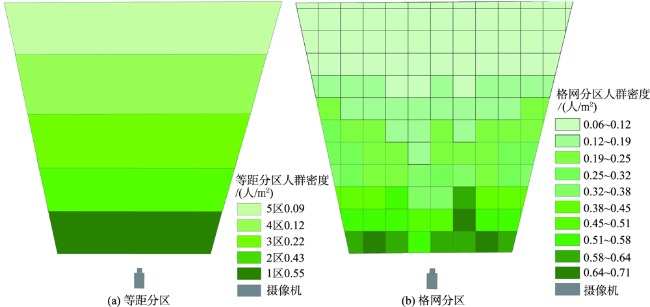
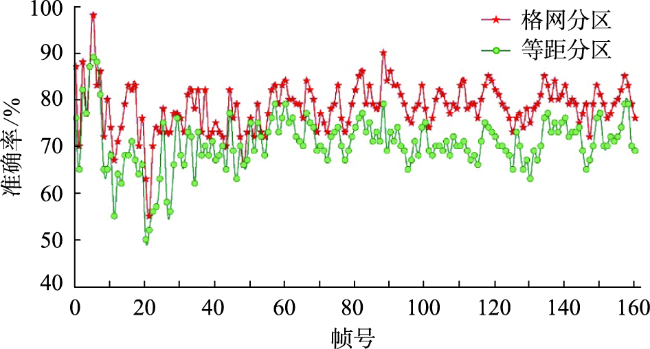
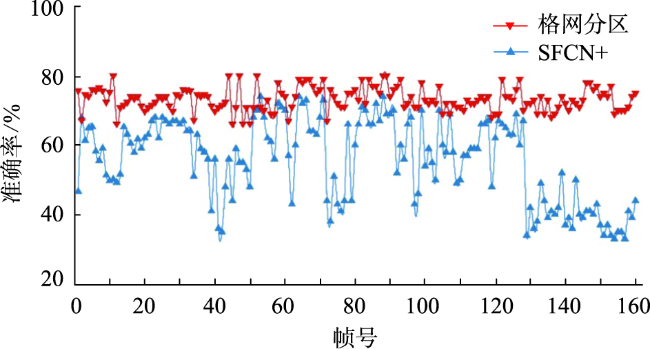
Aiming at the problem that the existing crowd counting methods cannot achieve accurate counting and map visualization of complex crowds, a crowd density estimation method considering video geographic mapping is proposed. Firstly, based on Deeplab V3+model, a crowd semantic segmentation model suitable for complex scenarios is constructed by transfer learning. Combining video with GIS, the high-precision homography matrix between video and crowd scene map is calculated according to four or more pixel coordinates between video frame and the corresponding geographic coordinates. Based on the crowd semantic segmentation model and the solved homography matrix, the crowd areas in videos are projected to the map. Secondly, to improve the accuracy of crowd number, two different partition schemes: equidistant and grid partition, are designed to divide the camera Field of View (FOV). According to the semantic segmentation result, the crowd density of each sub-region using different partition schemes is counted. Based on the crowd density and area of each sub-region, the total number in the camera FOV is calculated. Thirdly, based on the solved homography matrix, the semantic segmentation result of the crowd in the real-time video can be projected to the 2D map and the crowd number can be counted through the crowd density. In order to obtain accurate crowd density, we took a playground as the experimental area and collected multiple crowd surveillance videos at different times and under different crowd conditions. The experimental results show that: (1) the crowd semantic segmentation model constructed in this paper can achieve high-precision crowd segmentation in large scenes, with an accuracy of 94.11%; (2) Combining video with GIS, the polygon area of the crowd was filled through the point symbol of person style, the crowd mapping and visual expression were realized, and the goal of crowd localization, measurement, and spatial analysis was achieved; (3) Accurate counting of surveillance video crowd was realized, and the camera FOV was divided into many sub-areas, which is conducive to improving the crowd counting accuracy. Compared to the crowd density estimation method based on density map, the method proposed in this paper is suitable for large scenes with high altitude and high density, especially in the areas where the texture of people's head isn't clear and crowd characteristics are obscured. Our method can effectively improve the accuracy of crowd counting and map visualization and can be used for crowd supervision in large-scale events, stations, shopping malls, and sports venues.
SUN Yinping , ZHANG Xingguo , SHI Xinyu , LI Qize . Crowd Density Estimation Method Considering Video Geographic Mapping[J]. Journal of Geo-information Science, 2022 , 24(6) : 1130 -1138 . DOI: 10.12082/dqxxkx.2022.210555
| [1] |
方志祥. 人群动态的观测理论及其未来发展思考[J]. 地球信息科学学报, 2021, 23(9):1527-1536.
[
|
| [2] |
张兴国. 地理场景协同的多摄像机目标跟踪研究[D]. 南京: 南京师范大学, 2014.
[
|
| [3] |
|
| [4] |
张兴国, 刘学军, 王思宁, 等. 监控视频与2D地理空间数据互映射[J]. 武汉大学学报·信息科学版, 2015, 40(8):1130-1136.
[
|
| [5] |
王美珍, 刘学军, 孙开新, 等. 最优视频子集与视频时空检索[J]. 计算机学报, 2019, 42(9):2004-2023.
[
|
| [6] |
宋宏权, 刘学军, 闾国年, 等. 区域人群状态的实时感知监控[J]. 地球信息科学学报, 2012, 14(6):686-692,697.
[
|
| [7] |
蒋妮, 周海洋, 余飞鸿. 基于计算机视觉的目标计数方法综述[J]. 激光与光电子学进展, 2021, 58(14):43-59.
[
|
| [8] |
余鹰, 朱慧琳, 钱进, 等. 基于深度学习的人群计数研究综述[J]. 计算机研究与发展, 2021, 58(12):2724-2747.
[
|
| [9] |
屈晶晶, 辛云宏. 连续帧间差分与背景差分相融合的运动目标检测方法[J]. 光子学报, 2014, 43(7):219-226.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
宋宏权, 刘学军, 闾国年, 等. 一种可跨摄像机的人群密度估计模型[J]. 中国安全科学学报, 2013, 23(12):139-145.
[
|
| [16] |
邓仕虎, 张兴国, 王小勇, 等. 视频和GIS协同的人群状态感知模型[J]. 信阳师范学院学报(自然科学版), 2018, 31(1):59-63.
[
|
| [17] |
宋宏权, 王丰, 刘学军, 等. 地理环境下的群体运动分析与异常行为检测[J]. 地理与地理信息科学, 2015, 31(4):1-5,11,133.
[
|
| [18] |
|
| [19] |
Chen,
|
| [20] |
|
| [21] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}