
Journal of Geo-information Science >
Remote Sensing Mapping of Mountain Vegetation Via Uncertainty-based Iterative Optimization
Received date: 2021-09-29
Revised date: 2021-12-13
Online published: 2022-09-25
Supported by
National Natural Science Foundation of China(42071316)
National Natural Science Foundation of China(41631179)
National Key Research and Development Program of China(2017YFB0503600)
Chongqing agricultural industry digital map project(21C00346)
Major Science and Technology Project of Inner Mongolia Autonomous Region(2021SZD0036)
Key Research and Development Program of Shaanxi(2021NY-170)
Fundamental Research Funds for the Central Universities, Chang'an University(300102120201)
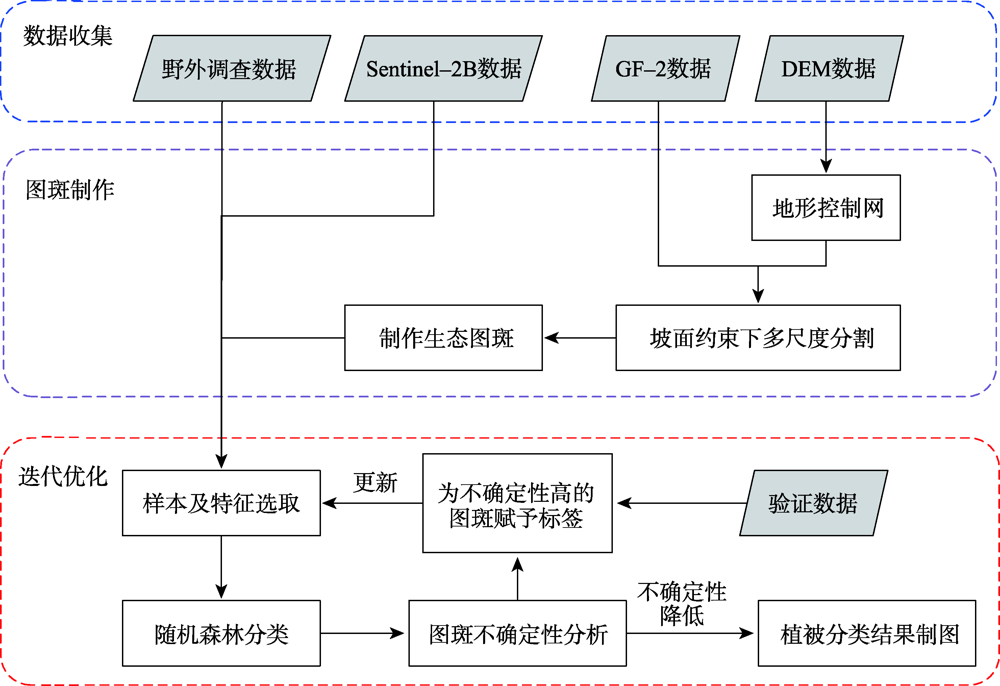
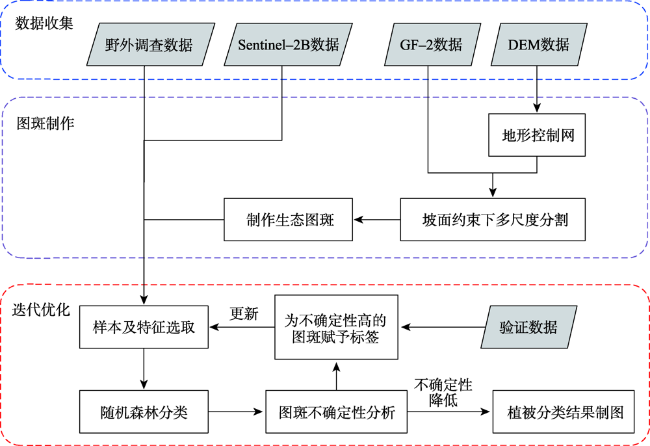
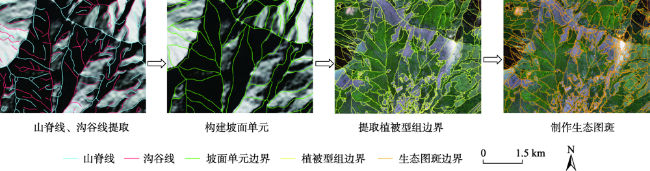
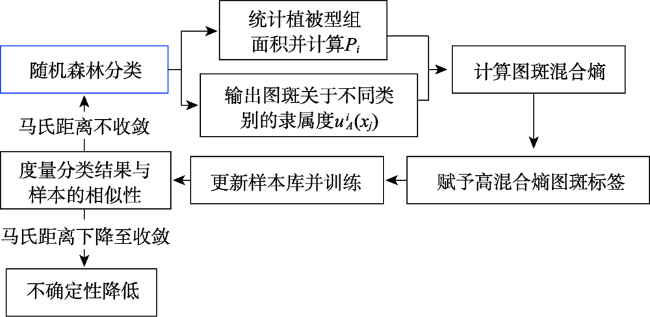
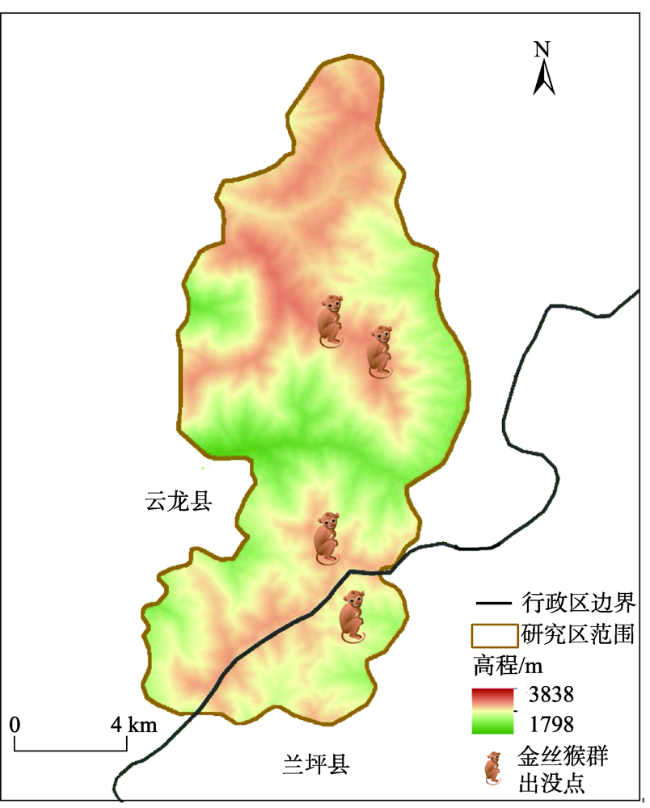
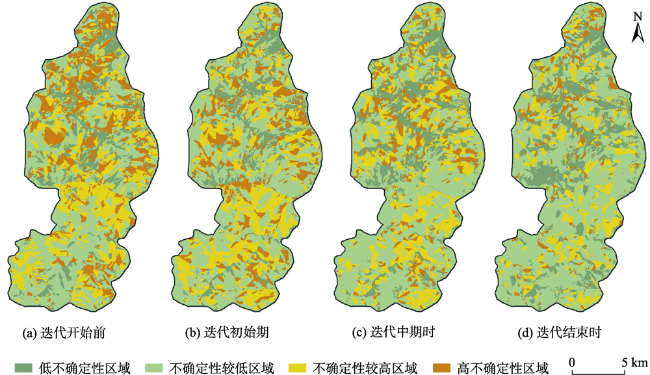
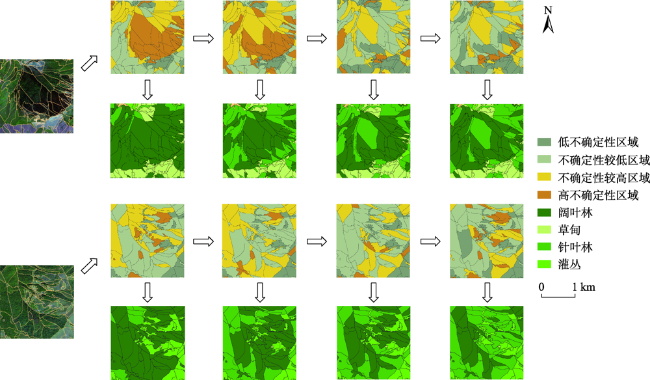
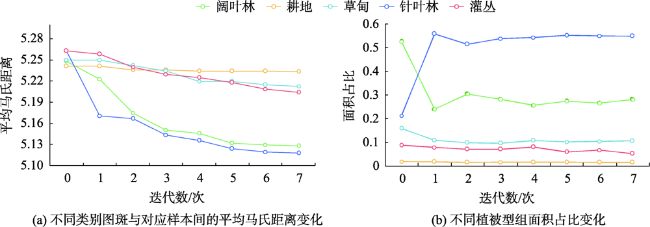
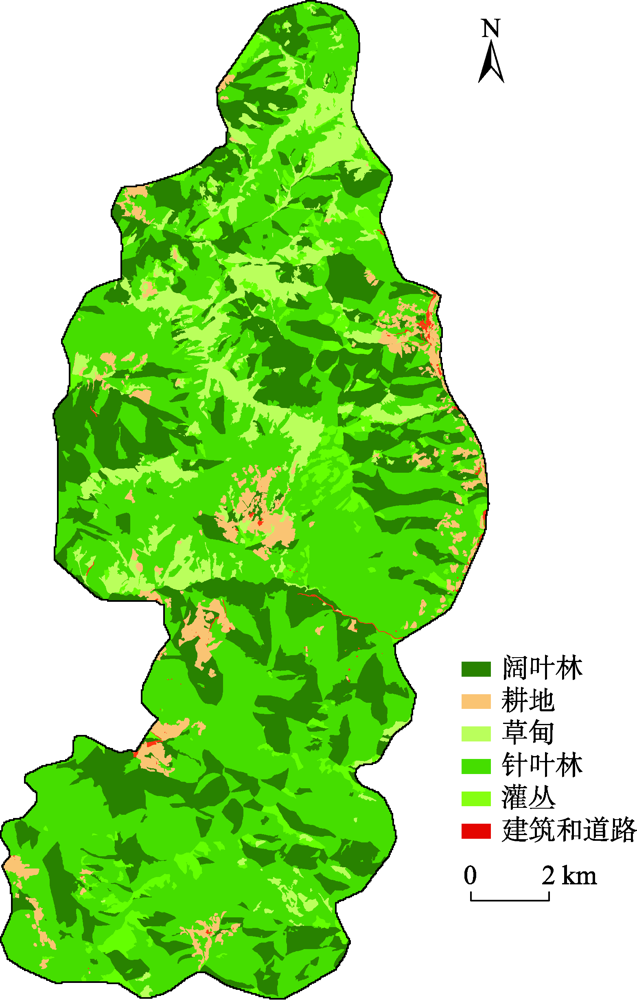
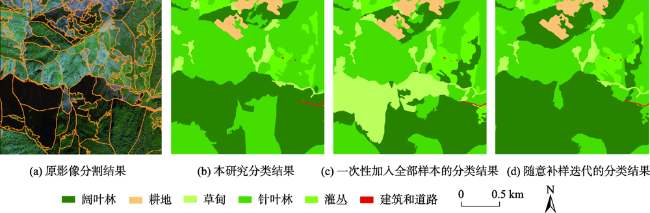
Mountain area is an important part of terrestrial ecosystem and contains valuable ecological values. Due to its high heterogeneity and special environmental characteristics, there are many problems and challenges in remote sensing classification for mountainous areas. The traditional classification method based on vegetation index usually uses remote sensing data from a single source, which is effective in some scenarios, but severely limited in mountainous areas with fragmented landscape and complex topography. In order to achieve accurate mountain vegetation information, the mountainous areas in northwestern Yunnan were selected as research areas to carry out method experiments in this paper. This study used high resolution remote sensing image data and Digital Elevation Model(DEM), combined with the idea of zoning-stratified perception, and proposed a classification method for vegetation types in mountain areas based on uncertainty theory. Firstly, the images of the study area were segmented at multiple scales to make geo-patches under the constraints of the slope units, which were implemented by use of ridge lines and valley lines that were generated by hydrologic analysis based on DEM. Secondly, spectral, textural, and topographic features were selected for classification using random forest model. The experiment took the Mahalanobis distance as the similarity metric between the classification results and the samples of corresponding class as the optimization objective. Then the mixing entropy model was constructed to quantitatively calculate the uncertainty of speckle speculations caused by randomness and fuzziness, which depends on the membership degree of different vegetation types and the area proportion of different vegetation types. Finally, an automatic targeted sample supplement and iterative optimization of the model based on historical interpretation data, uncertainty theory, and similarity measurement were conducted. The model was updated accordingly every time the sample was supplemented. The iteration stopped when the Mahalanobis distance decreased to a convergence. This study also generated the variation trend of uncertainty in iteration and space. The overall classification accuracy of the experiment reached 90.8%, 29.4% higher than that before iteration, and the Kappa coefficient reached 0.875. In the high uncertainty region, the accuracy of this method was 17% and 13% higher than that of one-time and random sample supplement methods, respectively. The experimental results show that the method of iterative optimization, which integrates incremental information through human-computer interaction and imports high uncertainty and low confidence patches into the sample library, can effectively classify the vegetated mountain surface and has higher efficiency and lower uncertainty than the traditional sample selection methods.
GUO Yifei , WU Tianjun , LUO Jiancheng , SHI Hanning , GAO Lijing . Remote Sensing Mapping of Mountain Vegetation Via Uncertainty-based Iterative Optimization[J]. Journal of Geo-information Science, 2022 , 24(7) : 1406 -1419 . DOI: 10.12082/dqxxkx.2022.210594
表1 植被型组分类体系Tab. 1 Classification system of vegetation type groups |
| 植被型组 | 优势种 |
|---|---|
| 针叶林 | 云南松、华山松、高山松、云南铁杉、丽江云杉、云冷杉 |
| 阔叶林 | 栎类、杨树、桤木、赤杨叶、桦树、杜鹃等 |
| 草甸 | 蕨类、金丝桃、滇川银莲花 |
| 灌丛 | 杜鹃、清香木、绣鳞木犀榄 |
| 耕地 | 核桃、作物 |
| 其他 | 建设用地、道路 |
表2 图斑特征列表Tab. 2 Feature list of geo-patches |
| 特征类别 | 特征名称 | 数量/个 |
|---|---|---|
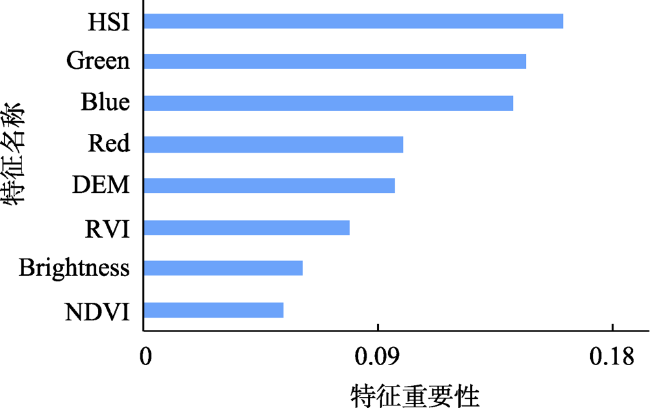
| 光谱信息 | R,G,B,NIR,NDVI,RVI, PVI,Brightness,HSI | 9 |
| 纹理信息 | Homogeneity,Contrast,Dissimilarity | 3 |
| 地形信息 | DEM,Aspect | 2 |
表3 迭代过程中不同类别图斑的平均混合熵Tab. 3 Average hybrid entropy of different types of geo-patches during iteration |
| 迭代轮次 | 类别 | 总体 | ||||
|---|---|---|---|---|---|---|
| 阔叶林 | 耕地 | 草甸 | 针叶林 | 灌丛 | ||
| 1 | 2.552 | 2.003 | 2.268 | 2.519 | 2.381 | 2.396 |
| 3 | 2.488 | 1.942 | 2.074 | 2.510 | 2.306 | 2.345 |
| 5 | 2.469 | 1.980 | 2.110 | 2.477 | 2.252 | 2.331 |
| 7 | 2.473 | 1.955 | 2.096 | 2.486 | 2.314 | 2.339 |
表4 植被分类精度评价Tab. 4 Accuracy evaluation of vegetation classification |
| 植被型组 | 针叶林 | 阔叶林 | 耕地 | 草甸 | 灌丛 | 总计 | 用户精度/% |
|---|---|---|---|---|---|---|---|
| 针叶林 | 89 | 5 | 0 | 0 | 1 | 95 | 93.7 |
| 阔叶林 | 10 | 58 | 0 | 1 | 0 | 69 | 84.1 |
| 耕地 | 0 | 0 | 23 | 0 | 0 | 23 | 100.0 |
| 草甸 | 1 | 1 | 0 | 29 | 1 | 32 | 90.6 |
| 灌丛 | 2 | 0 | 0 | 1 | 28 | 31 | 90.3 |
| 总计 | 102 | 64 | 23 | 31 | 30 | 250 | |
| 生产精度/% | 87.3 | 90.6 | 100.0 | 93.5 | 93.3 | ||
| 总分类精度/% | 90.8 | ||||||
| Kappa系数 | 0.875 | ||||||
表5 不同迭代轮次的总体分类精度对比Tab. 5 Comparison of overall classification accuracy in different iterations |
| 迭代次数 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 分类精度/% | 61.4 | 69.6 | 75.4 | 79.2 | 82.2 | 84.8 | 87.6 | 90.8 |
表6 不同采样方法在高不确定性区域的效果对比Tab. 6 Comparison of different sampling methods in high uncertainty region |
| 迭代前 | 一次性采样 | 随机补样 | 本研究结果 | |
|---|---|---|---|---|
| 分类精度 | 0.31 | 0.36 | 0.40 | 0.53 |
| 平均置信度 | 0.40 | 0.45 | 0.63 | 0.55 |
| [1] |
杨超, 邬国锋, 李清泉, 等. 植被遥感分类方法研究进展[J]. 地理与地理信息科学, 2018, 34(4):24-32.
[
|
| [2] |
杨颖频, 吴志峰, 骆剑承, 等. 时空协同的地块尺度作物分布遥感提取[J]. 农业工程学报, 2021, 37(7):166-174.
[
|
| [3] |
|
| [4] |
任冲, 鞠洪波, 张怀清, 等. 多源数据林地类型的精细分类方法[J]. 林业科学, 2016, 52(6):54-65.
[
|
| [5] |
|
| [6] |
黄恩兴. 遥感影像分类结果的不确定性研究[J]. 中国农学通报, 2010, 26(5):322-325.
[
|
| [7] |
承继成, 郭华东, 史文中, 等. 遥感数据的不确定性问题[M]. 北京: 科学出版社, 2004.
[
|
| [8] |
刘艳芳, 兰泽英, 刘洋, 等. 基于混合熵模型的遥感分类不确定性的多尺度评价方法研究[J]. 测绘学报, 2009, 38(1):82-87.
[
|
| [9] |
徐慧. 遥感影像不确定性对分类结果可靠性影响模式研究[D]. 武汉: 武汉大学, 2020.
[
|
| [10] |
柏延臣, 王劲峰. 遥感数据专题分类不确定性评价研究:进展、问题与展望[J]. 地球科学进展, 2005(11):66-73.
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
张俊瑶, 姚永慧, 索南东主, 等. 基于垂直带谱的太白山区山地植被遥感信息提取[J]. 地球信息科学学报, 2019, 21(8):1284-1294.
[
|
| [19] |
张磊. 不确定性指导下的自适应数字土壤制图补样方法[D]. 南京: 南京师范大学, 2018.
[
|
| [20] |
|
| [21] |
骆剑承, 吴田军, 吴志峰, 等. 遥感大数据智能计算[M]. 北京: 科学出版社, 2020.
[
|
| [22] |
|
| [23] |
陈春雷, 武刚. 面向对象的遥感影像最优分割尺度评价[J]. 遥感技术与应用, 2011, 26(1):96-102.
[
|
| [24] |
| [25] |
|
| [26] |
张雷, 王琳琳, 张旭东, 等. 随机森林算法基本思想及其在生态学中的应用——以云南松分布模拟为例[J]. 生态学报, 2014, 34(3):650-659.
[
|
| [27] |
|
| [28] |
|
| [29] |
吴尚蓉, 刘佳, 杨鹏. 基于参数型指数混合熵模型的农业遥感分类不确定性评价[J]. 农业工程学报, 2013, 29(6):177-184+296.
[
|
| [30] |
刘冰, 李瑞麟, 封举富. 深度度量学习综述[J]. 智能系统学报, 2019, 14(6):1064-1072.
[
|
| [31] |
|
| [32] |
梅江元. 基于马氏距离的度量学习算法研究及应用[D]. 哈尔滨: 哈尔滨工业大学, 2016.
[
|
| [33] |
薛达元, 武建勇. 长江中上游生物多样性与保护研究——以滇西北为例[J]. 环境保护, 2016, 44(15):31-35.
[
|
| [34] |
彭彦柱, 高海江. 对森林资源一类清查和二类调查的比较分析[J]. 林业勘查设计, 2005(1):26.
[
|
| [35] |
柴勇, 马建忠, 方向京, 等. 滇西北天然林生态分区研究[J]. 西部林业科学, 2020, 49(6):16-20,27.
[
|
| [36] |
李亮, 舒宁, 王凯, 等. 融合多特征的遥感影像变化检测方法[J]. 测绘学报, 2014, 43(9):945-953+959.
[
|
| [37] |
郭铌. 植被指数及其研究进展[J]. 干旱气象, 2003(04):71-75.
[
|
| [38] |
徐丹丹, 李文龙, 王迅, 等. 垂直植被指数的计算和精度分析[J]. 兰州大学学报(自然科学版), 2010, 46(5):102-106.
[
|
| [39] |
杨盼盼. 基于高分辨率遥感影像纹理特征的面向对象植被分类方法研究[D]. 昆明: 云南师范大学, 2017.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}