
Journal of Geo-information Science >
Multi-model Fusion Extraction Method for Chinese Text Implicative Meteorological Disasters Event Information
Received date: 2022-03-02
Revised date: 2022-05-08
Online published: 2023-02-25
Supported by
Strategic Priority Research Program of the Chinese Academy of Sciences(XDA23100103)
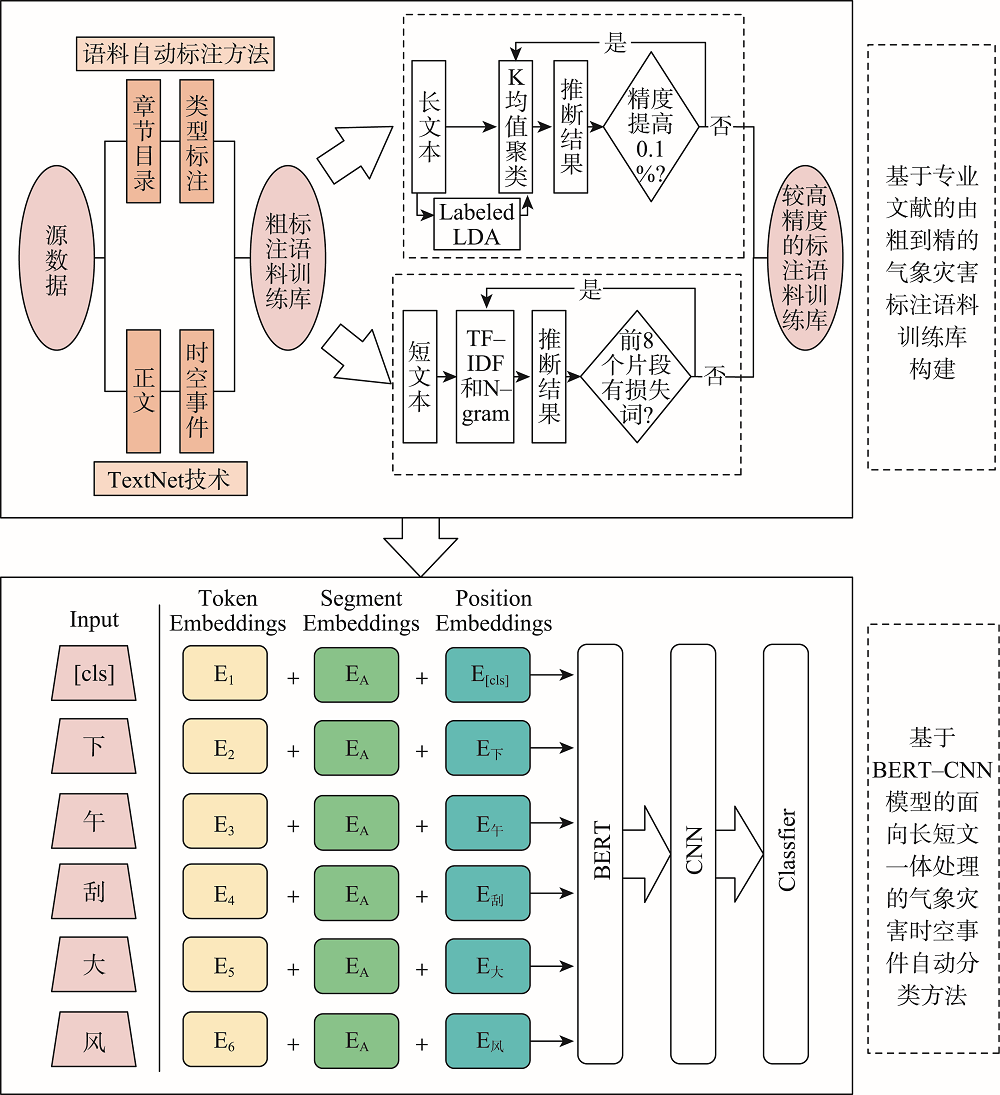
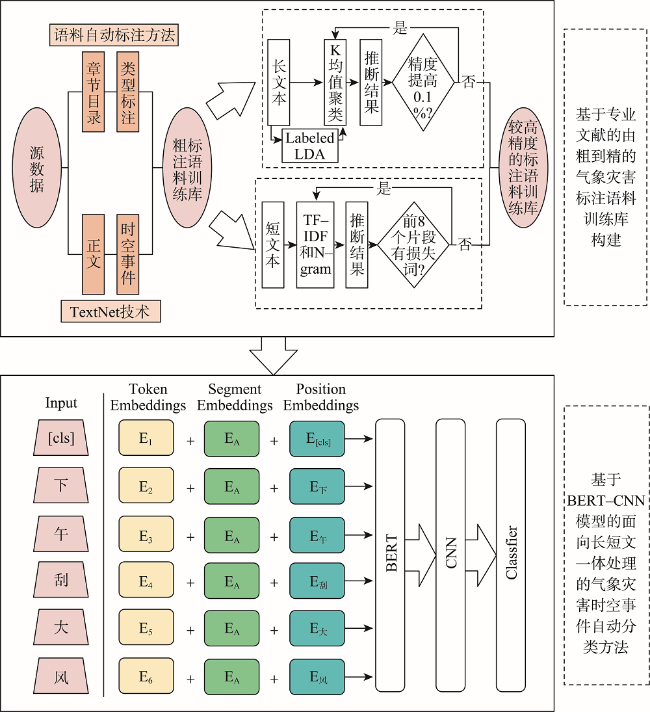
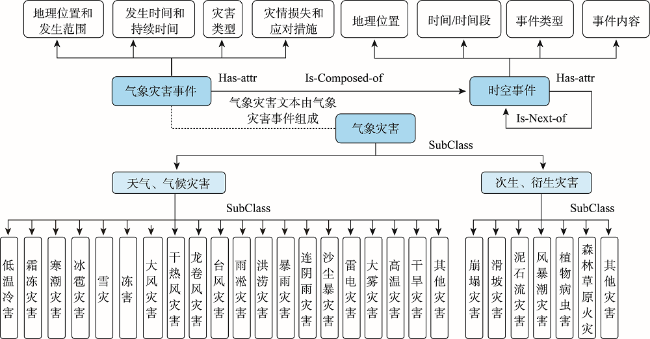
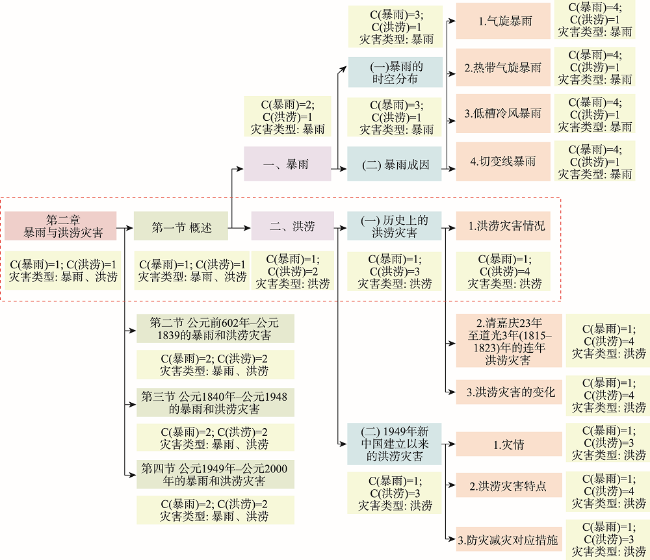
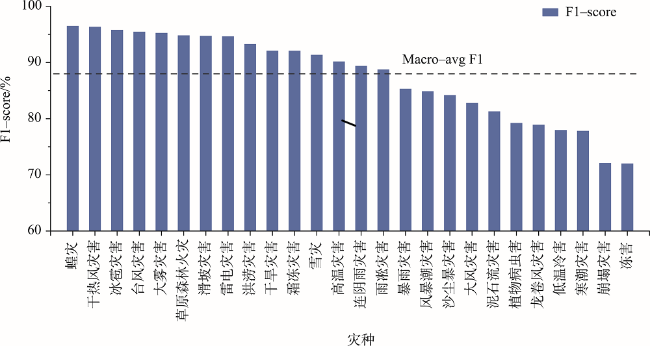
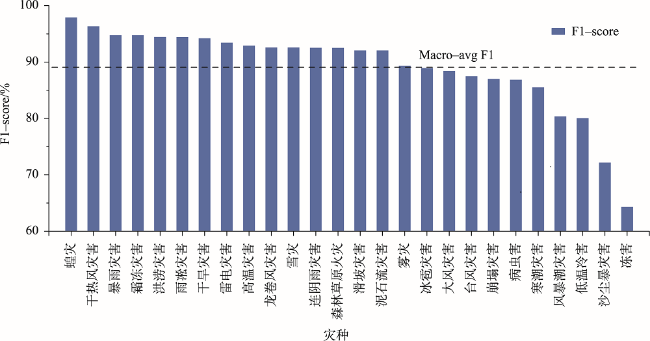
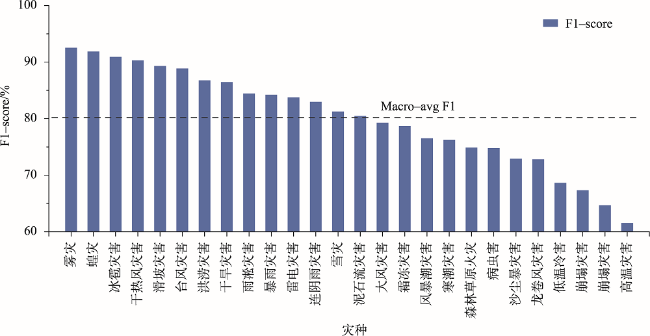
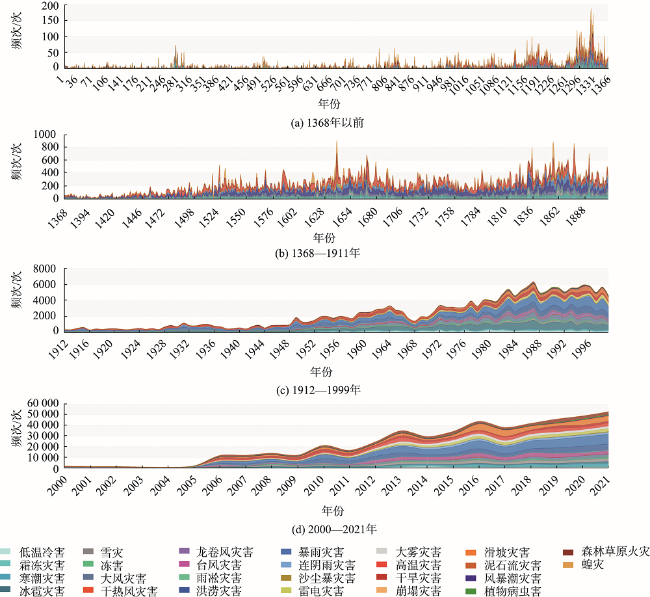
With global warming, the frequency of extreme weather events and major meteorological disasters is increasing globally. It is important to study the relationship between climate change and the frequency of meteorological disasters for disaster prevention and mitigation in the context of climate change. In this paper, a method is proposed for automatic extraction of spatial and temporal events of meteorological disasters based on natural language processing technology. Because there is a huge amount of spatial and temporal information of meteorological disasters available in literature and web data. Specifically, (1) A coarse-to-fine method was proposed to build a training corpus of meteorological disaster annotations based on professional literature. Firstly, a unified meteorological disaster knowledge system oriented to textual events is constructed to address the problems of ambiguity and incompatibility of different literature materials. Then a coarse annotation method based on chapter structure was constructed, and a Labeled LDA model-based and a fine-grained annotated corpus screening method based on TF-IDF and N-gram models were developed for long texts (modern texts) and short texts (literary texts), respectively, solving the problem of rapid corpus construction; (2) A method for automatic classification of spatiotemporal events of meteorological disasters based on the BERT-CNN model, which integrates contextual semantic features and local semantic features at multiple granularities, was developed for the integrated processing of short and long texts; (3) Using this method, the spatiotemporal events of meteorological disasters were automatically extracted from the textual and web data, and their macro F1 values reached 89.09% and 80.06%, respectively. The spatiotemporal distributions of major events of meteorological disasters were highly correlated with professional statistics; (4) Based on the above results, the spatiotemporal evolution of disasters in various historical periods in China was also reconstructed. We found that the overall volume of disaster data in each period showed a gradual increasing trend, with heavy rainfall disasters, floods, and droughts being the main types of disasters in China. Our method enables both the automatic extraction of long text events from the web and the automatic detection of short text events from literatures, providing a new technique for application of text data to meteorological disaster research and monitoring.
HU Duanmu , YUAN Wu , NIU Fangqu , YUAN Wen , HAN Aiai . Multi-model Fusion Extraction Method for Chinese Text Implicative Meteorological Disasters Event Information[J]. Journal of Geo-information Science, 2022 , 24(12) : 2342 -2355 . DOI: 10.12082/dqxxkx.2022.220088
表1 数据来源Tab. 1 Data sources |
| 数据来源 | 时间范围 | 文字类型 | 用途 | |
|---|---|---|---|---|
| 《大典》 | 31卷地方卷 | 1804 BC—2000 AD | 文言文、现代文 | 训练集和测试集 |
| 《总集》 | 4卷丛书 | 1300 BC—1911 AD | 文言文 | 验证集 |
| 泛在网络数据 | 省市应急管理门户网站、政务微博、知网报刊、论坛 | 2000 AD—至今 | 现代文 | 验证集 |
表2 各灾种的特征词Tab. 2 Mapping table of disaster types based on feature words |
| 灾种 | 特征词 | 灾种 | 特征词 |
|---|---|---|---|
| 低温冷害 | 冷害、五月寒、寒露风、倒春寒、低温阴雨、低温冷害 | 连阴雨灾害 | 连阴雨、梅雨、秋棉雨、霪雨 |
| 霜冻灾害 | 霜、霜灾、霜害、霜冻 | 沙尘暴灾害 | 沙尘暴 |
| 寒潮灾害 | 寒潮、寒害 | 雷电灾害 | 雷电、雷暴、雷击 |
| 冰雹灾害 | 雹、冰雹、雹灾、雹害 | 大雾灾害 | 雾、大雾、雾灾、浓雾、海雾、雾害 |
| 雪灾 | 大雪、雪灾、雪、暴雪 | 高温灾害 | 高温、热害、高温酷暑、酷热 |
| 冻害 | 冻害、冻灾 | 干旱灾害 | 旱、干旱、旱灾 |
| 大风灾害 | 大风、风灾、海上强风 | 崩塌灾害 | 崩塌 |
| 干热风灾害 | 干热风、干旱风、高温逼熟 | 滑坡灾害 | 滑坡 |
| 龙卷风灾害 | 龙卷风、龙卷 | 泥石流灾害 | 泥石流 |
| 台风灾害 | 台风、飓风 | 风暴潮灾害 | 风暴潮、海潮 |
| 雨凇灾害 | 雨凇、冰凌、冻雨 | 植物病虫害 | 病虫害、病虫灾害、作物病虫害 |
| 洪涝灾害 | 洪涝、水灾、洪水、雨涝、涝 | 森林草原火灾 | 森林火灾、草原火灾、火灾 |
| 暴雨灾害 | 暴雨、黑雨、大雨 | 蝗灾* | 蝗、蝗灾、蝗虫 |
注:蝗灾*为古代多发灾害,具有重要的研究意义。因此本文将其从病虫害中单独列出。 |
表3 文言文特征词Tab. 3 Feature words of literary texts |
| 灾种 | Top1 | Top2 | Top3 | Top4 | Top5 | Top6 | Top7 | Top8 |
|---|---|---|---|---|---|---|---|---|
| 低温冷害 | 阴雨 | 冷害 | 春寒 | 寒露风 | 低温阴雨 | 寒雨 | 二月寒 | 倒春寒 |
| 霜冻灾害 | 陨霜 | 霜 | 杀禾 | 严霜 | 杀麦 | 黑霜 | 大霜 | 霜冻 |
| 寒潮灾害 | 大寒 | 严寒 | 大雪 | 寒 | 奇寒 | 冻 | 横寒 | 冻死 |
| 冰雹灾害 | 雨雹 | 大雨雹 | 雹 | 雹灾 | 大如鸡卵 | 风雹 | 大雹 | 降雹 |
| 雪灾 | 大雪 | 雨雪 | 雪 | 大雨雪 | 大风雪 | 冰雪 | 大寒 | 飞雪 |
| 冻害 | 冻死 | 冻 | 大寒 | 冰冻 | 大雪 | 寒 | 受冻 | 冻坏 |
| 大风灾害 | 大风 | 拔木 | 大风雨 | 风雨 | 烈风 | 黑风 | 风雹 | 大风雪 |
| 干热风灾害 | 干热风 | 列风 | 热风 | 旱风 | 连日烈风 | 火风 | 风如火 | 风热如火 |
| 龙卷风灾害 | 龙卷 | 龙起 | 有龙 | 龙见 | 龙降 | 旋风 | 蛟 | 龙现 |
| 台风灾害 | 飓风 | 飓 | 台风 | 大飓 | 飓作 | 飓风拔木 | 飓风大作 | 飓发 |
| 雨凇灾害 | 雨木冰 | 木冰 | 冰凌 | 雨凇 | 冬木冰 | 木有冰 | 凌光 | 树凝 |
| 洪涝灾害 | 大水 | 水 | 水灾 | 漂没 | 淹没 | 溢 | 决 | 涝 |
| 暴雨灾害 | 大雨 | 雨雹 | 大雨雹 | 暴雨 | 风雨 | 雷雨 | 雨雪 | 骤雨 |
| 连阴雨灾害 | 霪雨 | 淫雨 | 霖雨 | 阴雨 | 久雨 | 连雨 | 雨连绵 | 恒雨 |
| 沙尘暴灾害 | 昼晦 | 风霾 | 黑风 | 黄风 | 雨土 | 雨沙 | 雨黄沙 | 雨黄土 |
| 雷电灾害 | 雷电 | 雷雨 | 雷 | 雷雹 | 雷震 | 雷击 | 大雷 | 震雷 |
| 大雾灾害 | 大雾 | 黄雾 | 雾 | 黑雾 | 昏雾 | 雨雾 | 阴雾 | 昼雾 |
| 高温灾害 | 暍 | 酷热 | 大热 | 酷热 | 炎热 | 高温 | 大暑 | 燠 |
| 干旱灾害 | 大旱 | 旱 | 夏旱 | 旱灾 | 旱蝗 | 赤地千里 | 水旱 | 亢旱 |
| 崩塌灾害 | 圮 | 山崩 | 崩 | 崩裂 | 崩塌 | 山裂 | 石崩 | 岩崩 |
| 滑坡灾害 | 滑坡 | 山催 | 崖摧 | 走山 | 地陷 | 土溜 | 地滑 | 跨山 |
| 泥石流灾害 | 泥石 | 泥石流 | 冲压 | 泥沙 | 蛟患 | 奔沙 | 木石随下 | 石决 |
| 风暴潮灾害 | 海溢 | 海潮 | 潮 | 风潮 | 海侵 | 大海潮 | 潮溢 | 潮涌 |
| 植物病虫害 | 虫 | 虫灾 | 虫害 | 有虫 | 虫食 | 黑虫 | 青虫 | 病 |
| 草原森林火灾 | 大火 | 火 | 火光 | 延烧 | 雷火 | 有火 | 起火 | 烧 |
| 蝗灾 | 蝗 | 飞蝗 | 旱蝗 | 蝗蝻 | 蝗蔽天 | 大蝗 | 夏蝗 | 蝗灾 |
| [1] |
Intergovernmental Panel on Climate Change. Climate Change 2013 The Physical Science Basis Working Group I Contribution to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change[M]. Cambridge: Cambridge University Press, 2014.
|
| [2] |
WMO. The atlas of mortality and economic losses from weather, Climate and Water Extremes (1970-2019)[ED/OL]. 2021. https://reliefweb.int/report/world/atlas-mortality-and-economic-losses-weather-climate-and-water-extremes-1970-2019.
|
| [3] |
韩雪华, 王卷乐, 卜坤, 等. 基于Web文本的灾害事件信息获取进展[J]. 地球信息科学学报, 2018, 20(8):1037-1046.
[
|
| [4] |
白华, 林勋国. 基于中文短文本分类的社交媒体灾害事件检测系统研究[J]. 灾害学, 2016, 31(2):19-23.
[
|
| [5] |
杨腾飞, 解吉波, 李振宇, 等. 微博中蕴含台风灾害损失信息识别和分类方法[J]. 地球信息科学学报, 2018, 20(7):906-917.
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
朱立平, 张紫玄, 邓三鸿, 等. 多层次文本分类法的模型构建及实验分析——以进出口商品归类问题为例[J]. 情报科学, 2021, 39(10):178-184.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
温克刚. 中国气象灾害大典[M]. 北京: 气象出版社, 2008.
[
|
| [18] |
张德二. 中国三千年气象记录总集[M]. 南京: 江苏教育出版社, 2013.
[
|
| [19] |
黄全义, 钟少波, 张超, 等. 灾害性气象事件影响预评估理论与方法[M]. 北京: 科学出版社, 2017.
[
|
| [20] |
张宝军, 马玉玲, 李仪. 我国自然灾害分类的标准化[J]. 自然灾害学报, 2013, 22(5):8-12.
[
|
| [21] |
郭进修, 李泽椿. 我国气象灾害的分类与防灾减灾对策[J]. 灾害学, 2005, 20(4):106-110.
[
|
| [22] |
北京理工大学计算机学院.袁武[EB/OL]. 2021. https://cs.bit.edu.cn/szdw/jsml/fjs/cyf_20181010083235900491/index.htm.
[School of Computer Science, Beijing University of Technology, Yuan Wu[EB/OL]. 2021. https://cs.bit.edu.cn/szdw/jsml/fjs/cyf_20181010083235900491/index.htm. ]
|
| [23] |
袁武, 袁文. 一种基于迭代的三步式无监督中文分词方法: CN108062305B[P]. 2021-12-17.
[
|
| [24] |
|
| [25] |
|
| [26] |
李萌, 袁文, 袁武, 等. 基于新闻大数据的北极地区地缘关系研究[J]. 地理学报, 2021, 76(5):1090-1104.
[
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
张向萍, 叶瑜, 王辉. 从1849年长江中下游地区洪涝灾害记录谈整编方志资料的使用[J]. 古地理学报, 2011, 13(2):229-235.
[
|
| [32] |
张琨佳, 杨帅, 苏筠. 明清时期我国水、旱灾害时空演变特点的对比分析[J]. 地球环境学报, 2014, 5(6):385-391.
[
|
| [33] |
张龙, 游银伟. 中国特色蝗灾治理技术体系及应用成效[J]. 植物保护学报, 2022, 49(1):118-124.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}