
Journal of Geo-information Science >
A Cross-View Image Matching Method with Viewpoint Conversion
Received date: 2022-05-16
Revised date: 2022-06-29
Online published: 2023-04-19
Supported by
National Natural Science Foundation of China(41601507)
Foundation Strengthening Program Technology Field Fundation(2019-JCJQ-JJ-126)
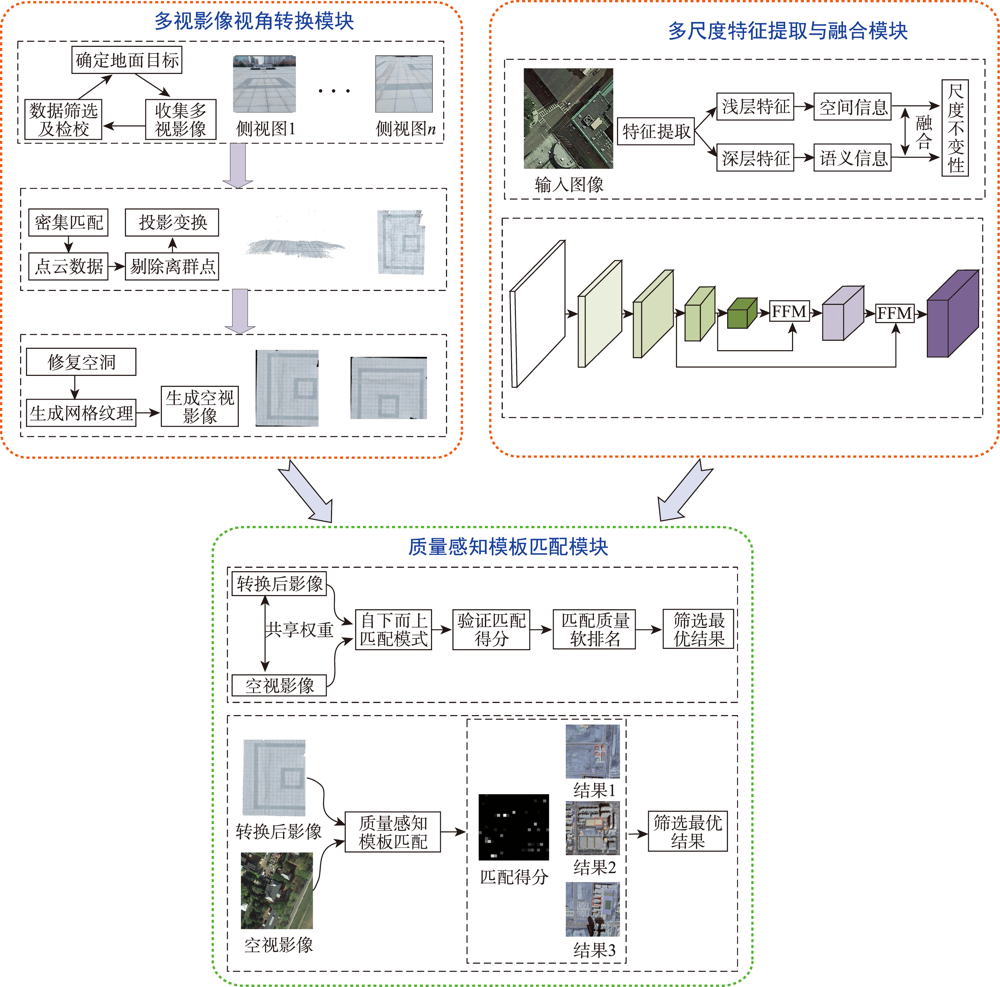
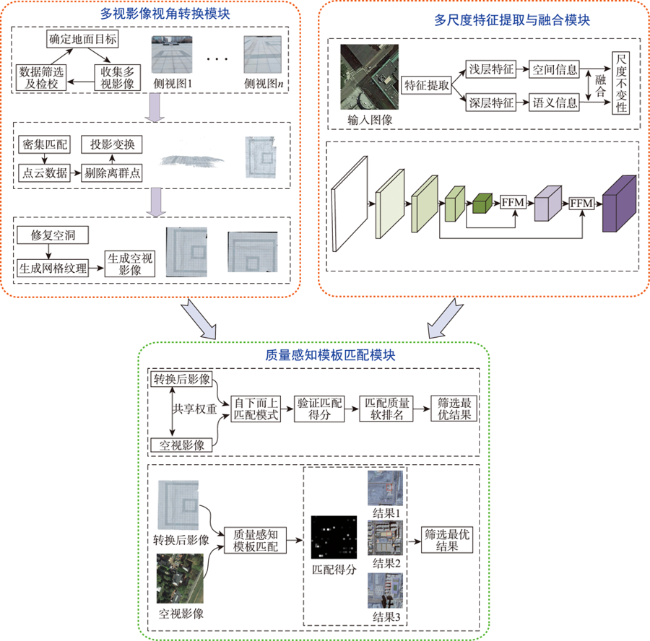
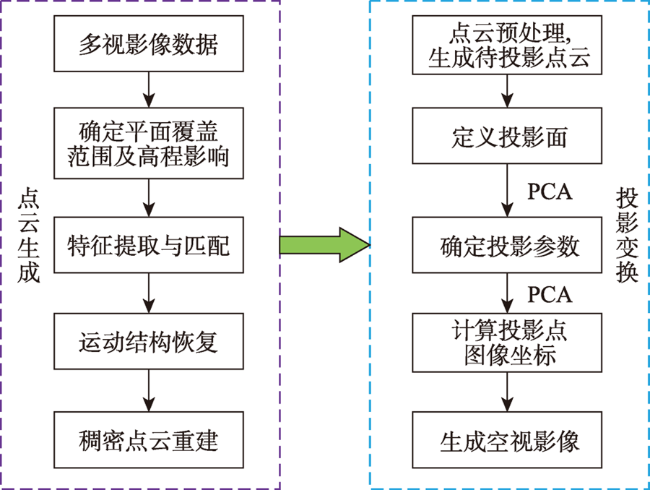
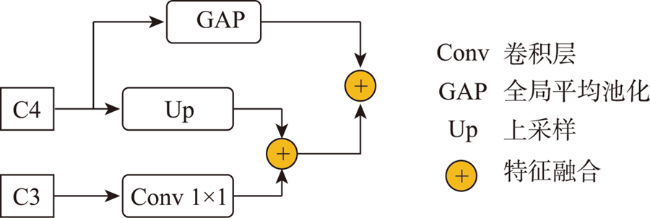
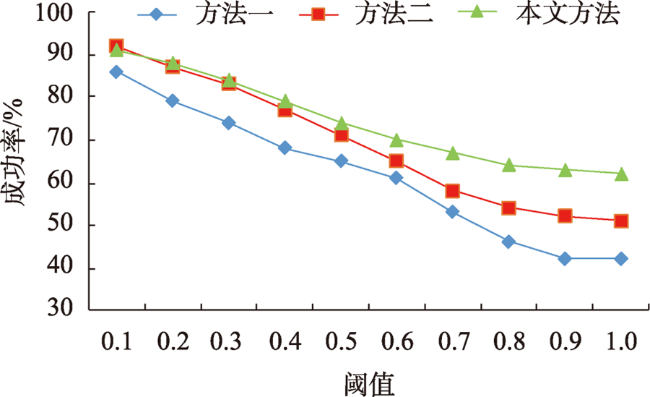
At present, the cross-view matching technology of remote sensing images cannot directly use large-scale satellite images for matching, which is difficult to meet the requirements of large-scale complex scene matching tasks and relies on large-scale datasets, thus lacking a good generalization ability. Aiming at the above problems, this paper proposes a cross-view remote sensing image matching method based on visual transformation using the quality-aware template matching method combined with the multi-scale feature fusion algorithm. In this method, the ground multi-view images are collected by using handheld photographic equipment. The portability and flexibility of the handheld photographic equipment can make it easier for us to collect multi-view images covering the target area. The acquired images are densely matched to generate point cloud data, and principal component analysis is used to fit the best ground plane and perform projection transformation to realize the conversion from the ground side view to the aerial view. Then, a feature fusion module is designed for the VGG19 network. The low, medium and high-level features extracted from remote sensing images are fused to obtain rich spatial and semantic information of remote sensing images. The fusion features of semantic information and spatial information can resist large-scale differences. Finally, the quality-aware template matching method is used. The features extracted from the ground images are matched with the fusion features of the remote sensing images. The matching soft ranking results are obtained, and the non-maximum suppression algorithm is used to select high-quality matching results. The experimental results show that the method proposed in this paper has a high accuracy and strong generalization ability without the need of large-scale datasets. The average matching success rate is 64.6%, and the average center point offset is 5.9 pixels. The matching results are accurate and complete, which provide a new solution for the task of cross-view image matching in large scenes.
RAO Ziyu , LU Jun , GUO Haitao , YU Donghang , HOU Qingfeng . A Cross-View Image Matching Method with Viewpoint Conversion[J]. Journal of Geo-information Science, 2023 , 25(2) : 368 -379 . DOI: 10.12082/dqxxkx.2023.220312
表3 消融实验结果Tab.3 Ablation experiment results |
| conv3-4 | conv4-4 | conv5-4 | 匹配成功率 /% | 中心点偏移量/像素 | ||
|---|---|---|---|---|---|---|
| 视角转换影像 | 未视角转换影像 | 瑕疵影像 | ||||
| √ | × | × | 44.6 | - | 40.1 | 10.8 |
| × | √ | × | 41.7 | - | 34.9 | 13.6 |
| × | × | √ | 57.4 | - | 51.9 | 8.8 |
| √ | × | √ | 61.3 | - | 56.1 | 7.6 |
| × | √ | √ | 56.8 | - | 53.7 | 8.4 |
| √ | √ | √ | 64.6 | - | 61.2 | 5.9 |
注:加粗字体为每列最优值,-表示方法失效。 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
闫利, 费亮, 陈长海, 等. 利用网络图进行高分辨率航空多视影像密集匹配[J]. 测绘学报, 2016, 45(10):1171-1181.
[
|
| [21] |
郭复胜, 高伟. 基于辅助信息的无人机图像批处理三维重建方法[J]. 自动化学报, 2013, 39(6):834-845.
[
|
| [22] |
郭复胜, 高伟, 胡占义. 无人机图像全自动生成大比例尺真正射影像方法[J]. 中国科学:信息科学, 2013, 43(11):1383-1397.
[
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}