
Journal of Geo-information Science >
Object Detection in Remote Sensing Images by Fusing Multi-neuron Sparse Features and Hierarchical Depth Features
Received date: 2022-09-20
Revised date: 2022-12-02
Online published: 2023-04-19
Supported by
National Natural Science Foundation of China(41871322)
National Natural Science Foundation of China(42130112)
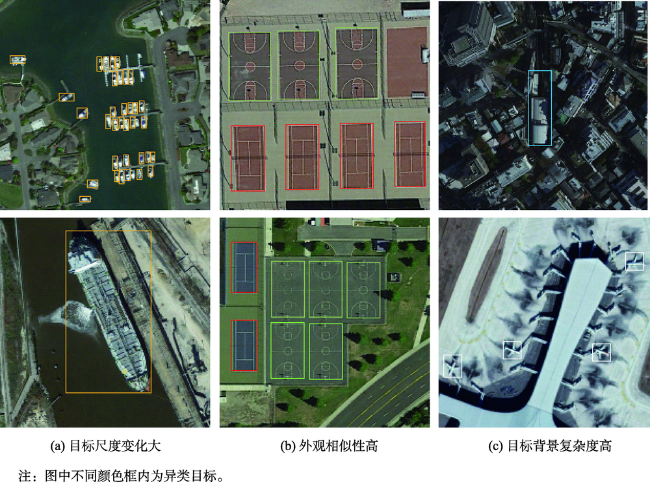
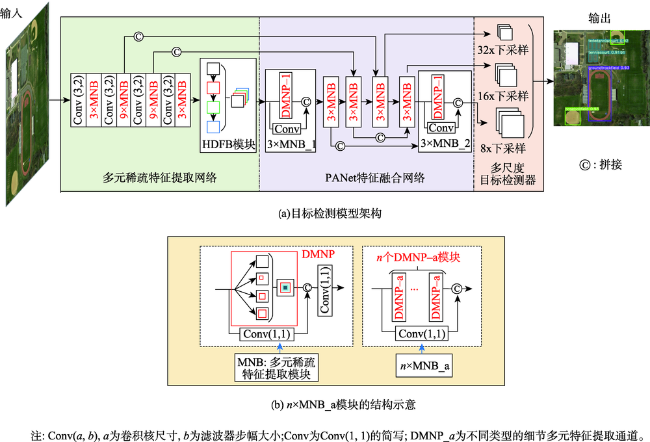
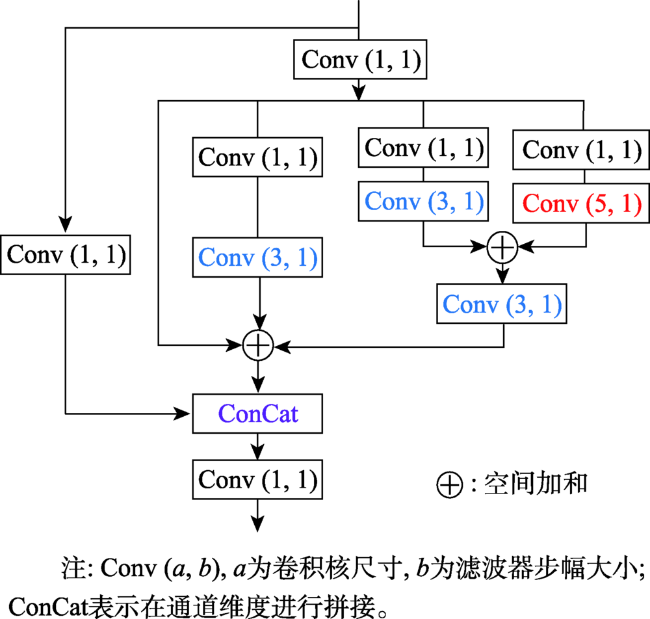
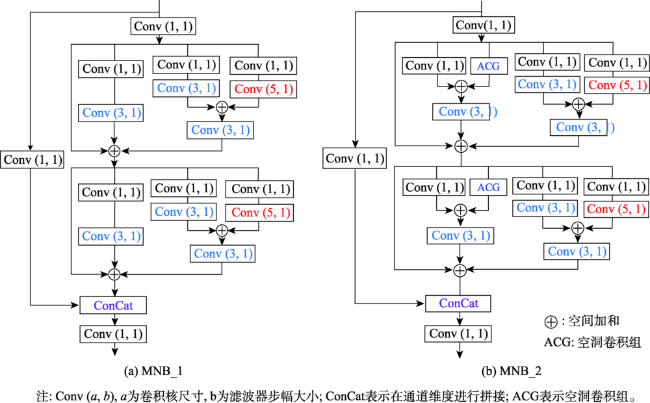
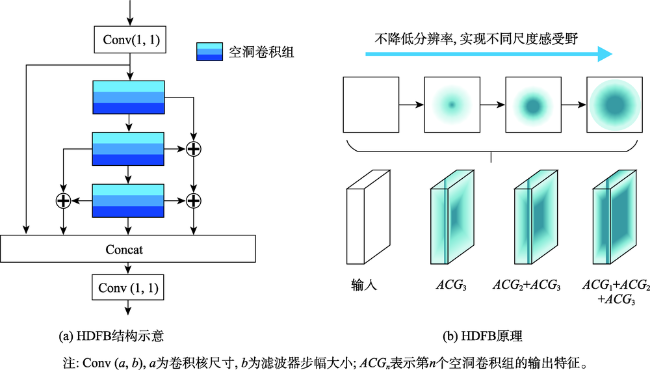
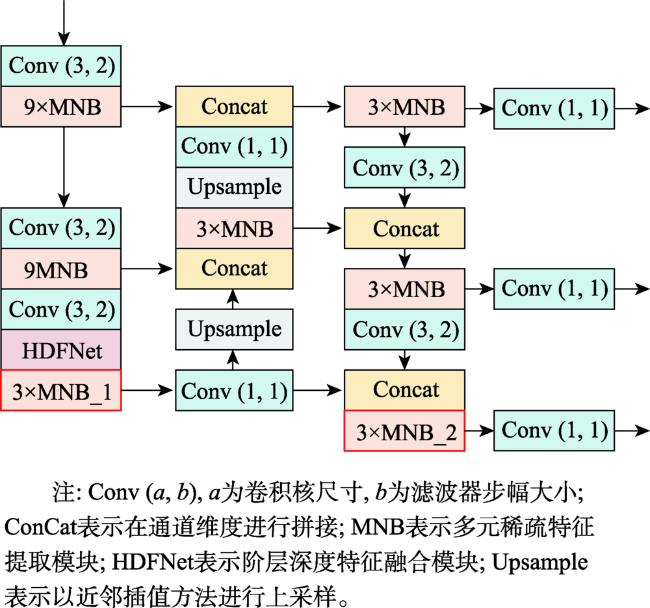
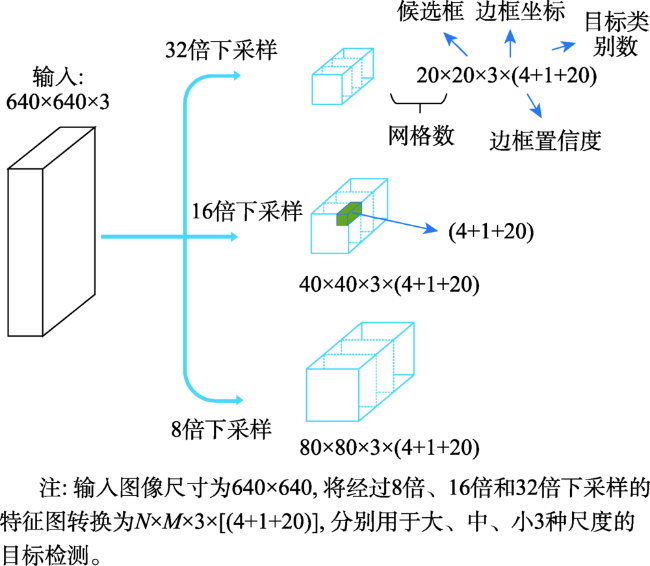
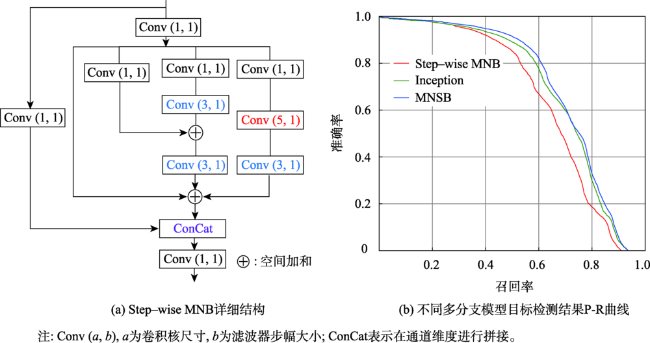
Object detection in remote sensing images is of great significance to urban planning, natural resource survey, land surveying, and other fields. The rapid development of deep learning has greatly improved the accuracy of object detection. However, object detection in remote sensing images faced many challenges such as multi-scale, appearance ambiguity, and complicated background. The remote sensing image datasets have a large range of object size variations, e.g., object resolutions range from a dozen to hundreds of pixels. high background complexity, remote sensing images are obtained with full time geographic information; high similarity in the appearance of different classes of targets; and diversity within classes. To address these problems, a deep convolutional network architecture that fuses the Multi-Neuron Sparse feature extraction block (MNB) and Hierarchical Deep Feature Fusion Block (HDFB) is proposed in this paper. The MNB uses multiple convolutional branching structures to simulate multiple synaptic structures of neurons to extract sparsely distributed features, and improves the quality of captured multi-scale target features by acquiring sparse features in a larger receptive field range as the network layers are stacked. The HDFB extracts contextual features of different depths based on null convolution, and then extracts features through a unique multi-receptive field depth feature fusion network, thus realizing the fusion of local features with global features at the feature map level. Experiments are conducted on the large-scale public datasets (DIOR). The results show that: (1) the overall accuracy of the method reaches 72.5%, and the average detection time of a single remote sensing image is 3.8 milliseconds; Our method has better detection accuracy for multi-scale objects with high appearance similarity and complex background than other SOTA methods; (2) The object detection accuracy of multi-scale and appearance ambiguity targets is improved by using MNB. Compared with object detection results with Step-wise branches, the overall accuracy is improved by 5.8%, and the sum operation on the outputs of each branch help achieve better feature fusion; (3) The HDFB extracts the hierarchical features by the hierarchical depth feature fusion module, which provides a new idea to realize the fusion of local features and global features at the feature map level and improves the fusion capability of the network context information; (4) The reconstructed PANet feature fusion network fuses sparse features at different scales with multivariate sparse feature extraction module, which effectively improves the effectiveness of PANet structure in remote sensing image target detection tasks. Many factors influence the final performance of the algorithm. On the one hand, high quality data sets are the basis of higher accuracy, e.g., image quality, target occlusion, and large intra-class variability of targets profoundly affect the training effect of the detector; on the other hand, model parameters settings, such as clustering analysis of the dataset to obtain bounding boxes information to improve the best recall, and the perceptual field range of the class depth feature fusion module, are key to ensuring accuracy. We conclude that using a Multi-Neuron Sparse feature extraction Network can improve feature quality, while a Hierarchical Deep Feature Fusion Block can fuse contextual information and reduce the impact of complex background noise, resulting in better performance in object detection tasks in remote sensing images.

GAO Pengfei , CAO Xuefeng , LI Ke , YOU Xiong . Object Detection in Remote Sensing Images by Fusing Multi-neuron Sparse Features and Hierarchical Depth Features[J]. Journal of Geo-information Science, 2023 , 25(3) : 638 -653 . DOI: 10.12082/dqxxkx.2023.220708
表1 DIOR数据集的目标类别索引Tab. 1 DIOR datasets object category index |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
|---|---|---|---|---|---|---|---|---|---|
| 飞机 | 机场 | 棒球场 | 篮球场 | 桥梁 | 烟囱 | 水坝 | 高速公路服务区 | 高速公路收费站 | 高尔夫球场 |
| C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 |
| 田径场 | 码头 | 立交桥 | 船舶 | 体育馆 | 储油罐 | 网球场 | 火车站 | 车辆 | 风车 |
表2 不同多分支模型测试结果对比Tab. 2 Comparison of test results of different multi-branch models |
| 不同的多 分支模型 | 准确率AP/% | mean AP | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | ||
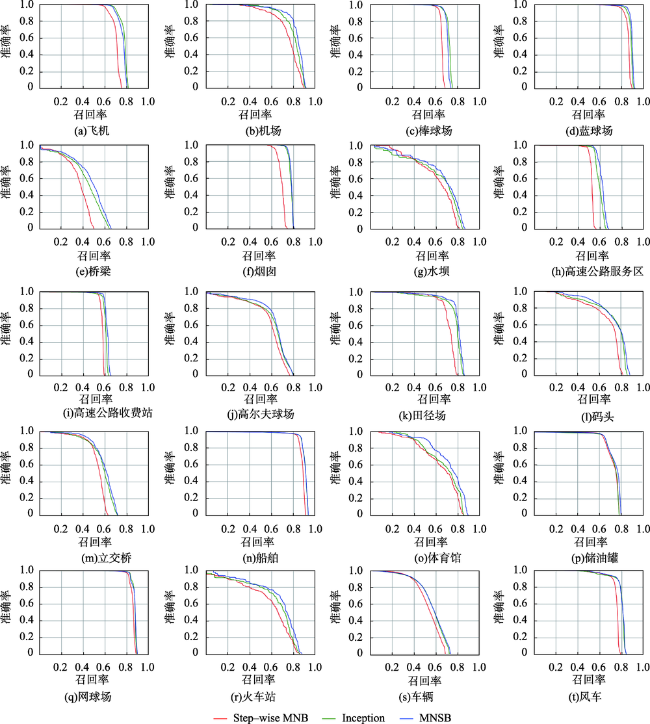
| Step-wise MNB | 69.7 | 74.9 | 65.3 | 85.3 | 35.4 | 68.8 | 59.9 | 51.9 | 57.1 | 70.9 | 66.7 | 57.8 | 52.7 | 87.1 | 63.9 | 72.5 | 85.1 | 58.3 | 53.1 | 79.2 | 65.5 |
| Inception[15] | 77.0 | 79.7 | 71.7 | 87.8 | 42.9 | 77.3 | 61.7 | 59.0 | 59.9 | 76.7 | 72.0 | 60.6 | 57.3 | 89.4 | 66.8 | 72.7 | 86.7 | 62.7 | 56.2 | 78.8 | 69.8 |
| MNSB | 75.7 | 82.1 | 70.5 | 88.8 | 46.0 | 77.8 | 64.7 | 61.6 | 61.7 | 78.8 | 73.9 | 62.3 | 59.2 | 89.4 | 71.4 | 73.9 | 86.9 | 66.4 | 56.6 | 79.3 | 71.3 |
注:粗体表示最佳精度。 |
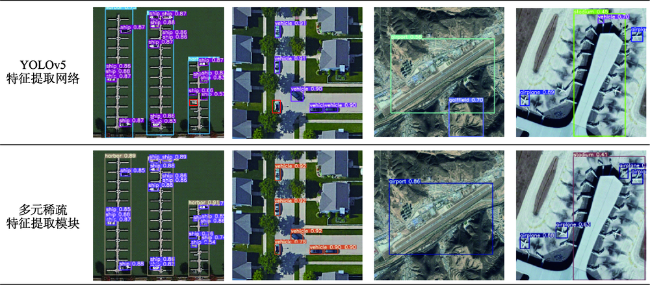
图9 YOLOv5与多元稀疏特征提取模块检测结果可视化对比Fig. 9 Visual comparison of YOLOv5 and multivariate sparse feature extraction block detection results |
表3 不同的ACG模型(空洞卷积组)测试结果对比Tab. 3 Comparison of different ACG models for atrous convolution group |
| 实验名称 | 准确率AP/% | mean AP | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | ||
| SPP+ACG | 71.2 | 57.6 | 69.7 | 79.8 | 44.0 | 75.4 | 58.0 | 53.6 | 55.2 | 61.8 | 58.7 | 48.4 | 55.3 | 88.4 | 49.7 | 70.7 | 83.7 | 35.0 | 53.9 | 74.0 | 60.9 |
| Three-ACG | 76.4 | 79.1 | 72.2 | 88.3 | 44.1 | 78.2 | 63.6 | 59.8 | 58.6 | 78.0 | 73.4 | 61.1 | 58.2 | 88.6 | 68.0 | 74.0 | 86.6 | 63.2 | 55.9 | 77.7 | 70.2 |
| SPP | 76.6 | 78.5 | 71.7 | 88.4 | 44.4 | 78.2 | 60.4 | 61.6 | 61.5 | 75.5 | 74.1 | 59.9 | 59.6 | 89.7 | 69.2 | 73.8 | 86.5 | 61.1 | 56.3 | 79.0 | 70.3 |
| HDFB | 76.8 | 80.0 | 72.6 | 88.7 | 42.5 | 78.7 | 63.6 | 57.9 | 60.7 | 79.6 | 73.0 | 60.8 | 57.7 | 88.6 | 70.4 | 76.9 | 86.4 | 65.1 | 54.7 | 76.3 | 70.6 |
注:粗体表示最佳精度。 |
表4 各方法在DIOR数据集的结果对比,粗体表示最佳精度Tab. 4 The comparison results of each method in the DIOR datasets, bold indicates best accuracy |
| 对比算法 | 准确率AP/% | mean AP | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | ||
| Faster R-CNN[4] | 54.0 | 74.5 | 63.6 | 80.7 | 44.8 | 72.5 | 60.0 | 75.6 | 62.3 | 76.0 | 76.8 | 46.4 | 57.2 | 71.8 | 68.3 | 53.8 | 81.1 | 59.5 | 43.1 | 81.2 | 65.1 |
| Mask R-CNN[24] | 53.9 | 76.6 | 63.2 | 80.9 | 40.2 | 72.5 | 60.4 | 76.3 | 62.5 | 76.0 | 75.9 | 46.5 | 57.4 | 71.8 | 68.3 | 53.7 | 81.0 | 62.3 | 43.0 | 81.0 | 65.2 |
| Retina-Net[25] | 53.3 | 77.0 | 69.3 | 85.0 | 44.1 | 73.2 | 62.4 | 78.6 | 62.8 | 78.6 | 76.6 | 49.9 | 59.6 | 71.1 | 68.4 | 45.8 | 81.3 | 55.2 | 44.4 | 85.8 | 66.1 |
| PANet[21] | 60.2 | 72.0 | 70.6 | 80.5 | 43.6 | 72.3 | 61.4 | 72.1 | 66.7 | 72.0 | 73.4 | 45.3 | 56.9 | 71.7 | 70.4 | 62.0 | 80.9 | 57.0 | 47.2 | 84.5 | 66.1 |
| YOLOv3[8] | 72.2 | 29.2 | 74.0 | 78.6 | 31.2 | 69.7 | 26.9 | 48.6 | 54.4 | 31.1 | 61.1 | 44.9 | 49.7 | 87.4 | 70.6 | 68.7 | 87.3 | 29.4 | 48.3 | 78.7 | 57.1 |
| Corner-Net[26] | 58.8 | 84.2 | 72.0 | 80.8 | 46.4 | 75.3 | 64.3 | 81.6 | 76.3 | 79.5 | 79.5 | 26.1 | 60.6 | 37.6 | 70.7 | 45.2 | 84.0 | 57.1 | 43.0 | 75.9 | 64.9 |
| YOLOv5 | 76.6 | 78.5 | 71.7 | 88.4 | 44.4 | 78.2 | 60.4 | 61.6 | 61.5 | 75.5 | 74.1 | 59.9 | 59.6 | 89.7 | 69.2 | 73.8 | 86.5 | 61.1 | 56.3 | 79.0 | 70.3 |
| 本文算法 | 78.1 | 83.9 | 73.0 | 89.0 | 48.2 | 79.4 | 65.6 | 63.9 | 61.9 | 80.6 | 76.6 | 63.5 | 61.6 | 89.6 | 68.7 | 76.4 | 87.0 | 66.4 | 57.0 | 78.7 | 72.5 |
注:粗体表示最佳精度。 |
| [1] |
周培诚, 程塨, 姚西文, 等. 高分辨率遥感影像解译中的机器学习范式[J]. 遥感学报, 2021, 25(1):182-197.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
陈丁, 万刚, 李科. 多层特征与上下文信息相结合的光学遥感影像目标检测[J]. 测绘学报, 2019, 48(10):1275-1284.
[
|
| [15] |
|
| [16] |
|
| [17] |
黄洁, 姜志国, 张浩鹏, 等. 基于卷积神经网络的遥感图像舰船目标检测[J]. 北京航空航天大学学报, 2017, 43(9):1841-1848.
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}