
Journal of Geo-information Science >
A Multispectral LiDAR Point Cloud Classification Method based on Enhanced Features Kernel Point Convolutional Network
Received date: 2022-09-28
Revised date: 2022-12-14
Online published: 2023-04-27
Supported by
National Natural Science Foundation of China(41971414)
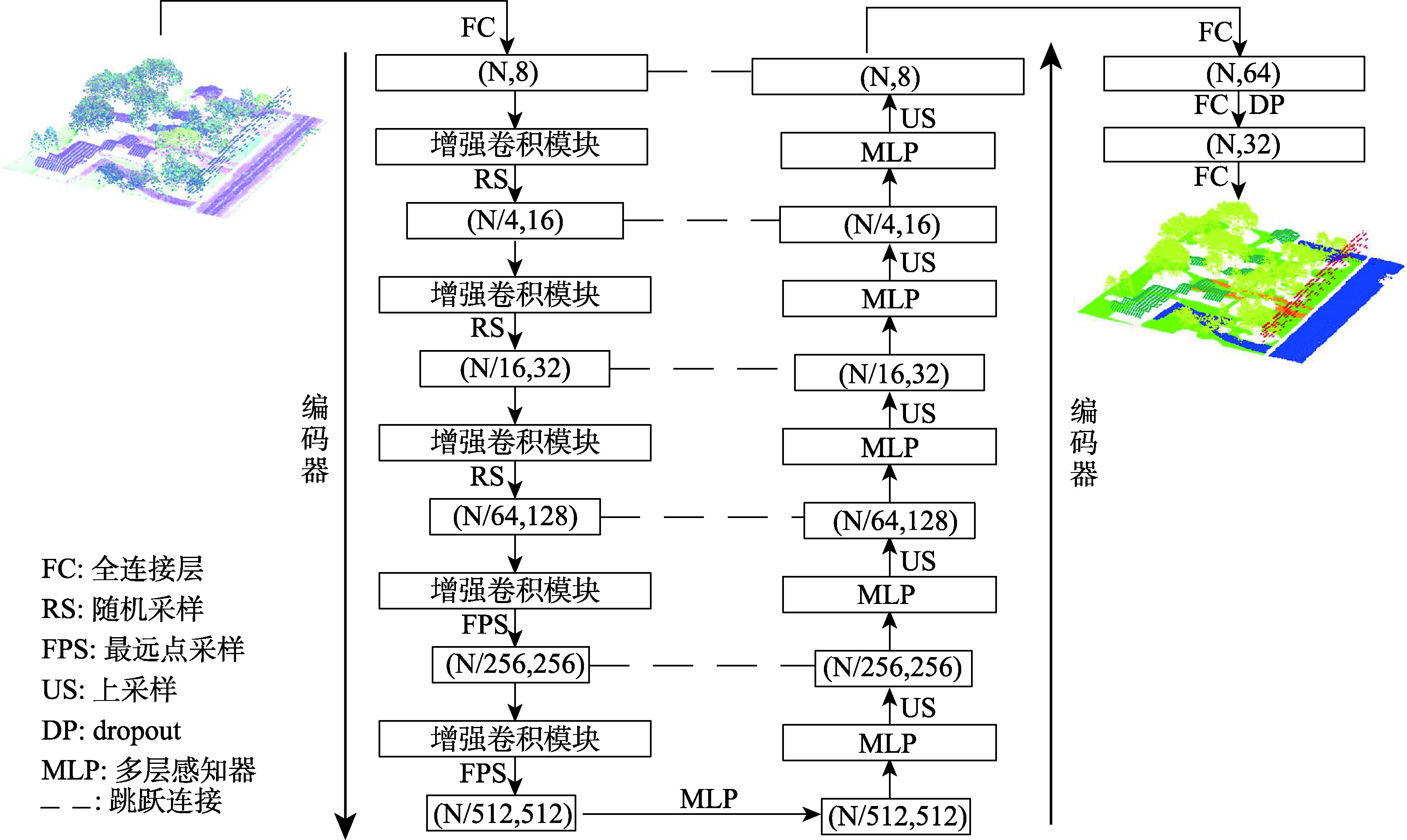
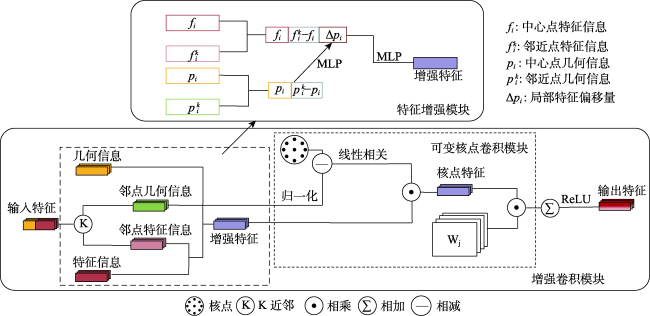
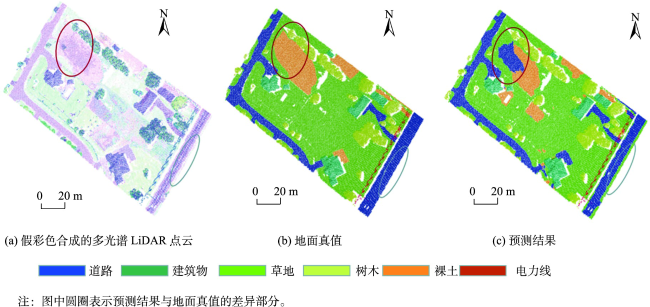
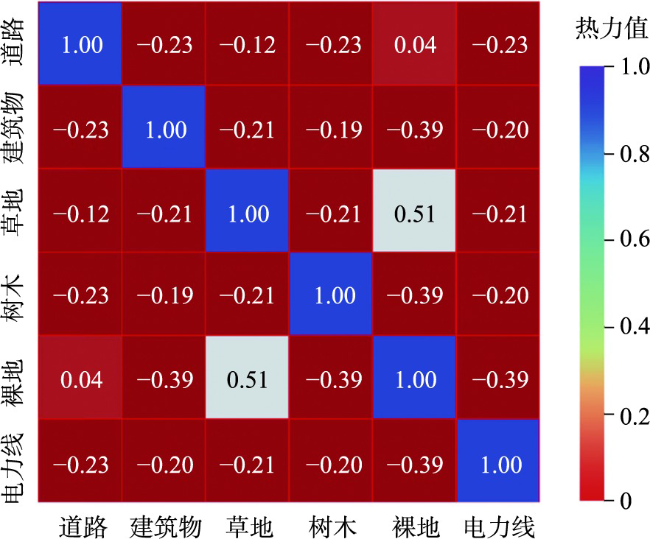
The multispectral LiDAR system can simultaneously provide the 3D space and spectral information of the target ground object, which is convenient for ground object recognition, land cover/use classification, and scene understanding. However, most multispectral LiDAR point cloud classification methods cannot fully mine the geometric information of point clouds and achieve poor performance in fine-scale classification. To overcome this limitation, this paper presents a continuous kernel point convolutional network which uses local point cloud geometric information to enhance features. Firstly, the network combines a random sampling with a farthest point sampling to quickly process large-scale multispectral LiDAR point clouds. Then, an enhanced convolution module based on continuous variable convolution is designed to improve the semantic information expression of multispectral LiDAR point cloud data. In order to address the problem that kernel point convolution simply using the distance relationship between the geometric space and feature space of neighboring points and centroids is insufficient to express the local information as a complementary feature of the kernel point convolution network, the local features given to the kernel points are enhanced by using the position relationship between neighboring points and centroids while aggregating the local features to provide richer semantic information for the multispectral LiDAR point cloud classification network. Finally, the weighted label smoothing loss and the Lovasz-Softmax loss are combined to further improve the classification performance. The results on the Titan multispectral LiDAR dataset show that the proposed network achieves an overall accuracy of 96.80%, a macro-F1 index of 88.51%, and a mIoU value of 83.42%, which is superior to the state-of-the-art (SOTA) multispectral LiDAR data networks. The proposed model uses the combination of grid sampling and KD-Tree to better preserve the geometric features of the original point cloud. In the case of a single batch of 65,536 points, the point cloud sampling time is reduced by 28 261.79 ms compared with similar multispectral LiDAR point cloud classification networks. This Study demonstrates the potential of enhanced feature kernel points convolutional network for multispectral LiDAR point cloud classification tasks.
CHEN Ke , GUAN Haiyan , LEI Xiangda , CAO Shuang . A Multispectral LiDAR Point Cloud Classification Method based on Enhanced Features Kernel Point Convolutional Network[J]. Journal of Geo-information Science, 2023 , 25(5) : 1075 -1087 . DOI: 10.12082/dqxxkx.2023.220736
表1 实验数据场景面积和激光点数目Tab. 1 The size of experimental scenes and number of points |
| 训练场景 | 测试场景 | |
|---|---|---|
| 场景面积/ m2 | 1 491 035 | 491 808 |
| 激光点数目/个 | 5 969 982 | 2 262 429 |
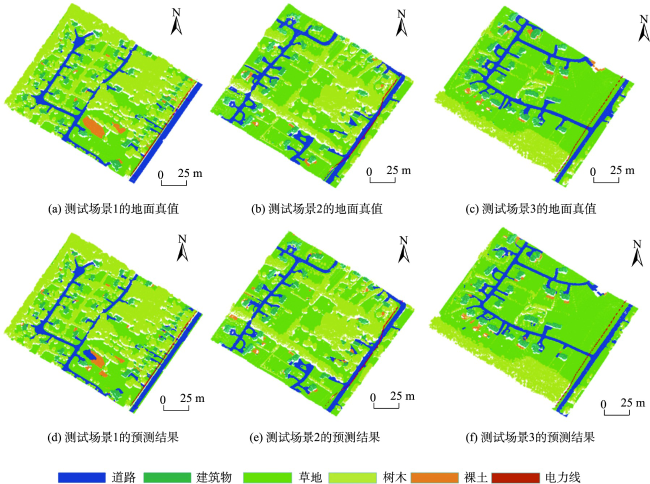
表3 点云分类结果定量分析Tab. 3 Statistical results obtained by the proposed method on the Optech multispectral LiDAR data |
| 类别 | F1-score/% | IoU/% |
|---|---|---|
| 道路 | 88.46 | 79.31 |
| 建筑物 | 99.44 | 98.89 |
| 草地 | 96.95 | 94.09 |
| 树木 | 99.72 | 99.45 |
| 裸地 | 48.32 | 32.27 |
| 电力线 | 98.19 | 96.50 |
| 均值 | 88.51 | 83.42 |
表4 对比网络对测试场景的分类结果Tab. 4 Classification results of test scenes by the compared networks (%) |
| 模型 | F1-score | OA | macro-F1 | mIoU | |||||
|---|---|---|---|---|---|---|---|---|---|
| 道路 | 建筑物 | 草地 | 树木 | 裸地 | 电力线 | ||||
| PointNet++[29] | 73.91 | 83.98 | 86.64 | 96.74 | 30.24 | 57.28 | 90.19 | 71.47 | 55.84 |
| SE-PointNet++[23] | 70.32 | 85.64 | 94.70 | 97.05 | 37.02 | 70.35 | 93.01 | 75.84 | 64.32 |
| DGCNN[30] | 70.43 | 90.25 | 93.62 | 97.93 | 21.97 | 55.24 | 91.36 | 71.57 | 52.04 |
| GACNet[31] | 64.51 | 84.21 | 93.41 | 96.66 | 22.77 | 33.83 | 89.91 | 67.65 | 55.14 |
| FR-GCNet[24] | 82.63 | 90.81 | 95.33 | 98.77 | 28.72 | 74.11 | 93.55 | 78.61 | 65.78 |
| RSCNN[32] | 71.18 | 89.00 | 91.42 | 95.63 | 26.43 | 70.03 | 92.44 | 73.90 | 56.10 |
| RandLA-Net[27] | 84.72 | 93.47 | 96.34 | 99.12 | 31.68 | 82.75 | 95.57 | 81.35 | 73.42 |
| 本文方法* | 86.66 | 99.13 | 96.36 | 99.31 | 39.89 | 91.31 | 95.91 | 85.44 | 79.93 |
| 本文方法 | 88.46 | 99.44 | 96.95 | 99.72 | 48.32 | 98.19 | 96.80 | 88.51 | 83.42 |
注:本文方法*表示使用FR-GCNet中的训练参数训练本文方法,即FPS-KNN样本采样,批次大小4、单批次输入点云数为4096,KNN算法中最邻近点个数设为32。 |
表5 消融实验结果Table 5 Ablation experiment results |
| 模型 | 特征增强模块 | 增强卷积模块 | FPS 采样 | 可变卷积核 | OA/% | mIoU/% | |||
|---|---|---|---|---|---|---|---|---|---|
| A | - | √ | √ | √ | 96.51 | 82.23 | |||
| B | √ | √ | - | √ | 96.25 | 81.39 | |||
| C | √ | √ | √ | - | 95.77 | 78.16 | |||
| D | √ | - | √ | √ | 81.62 | 46.65 | |||
| 本文方法 | √ | √ | √ | √ | 96.80 | 83.42 | |||
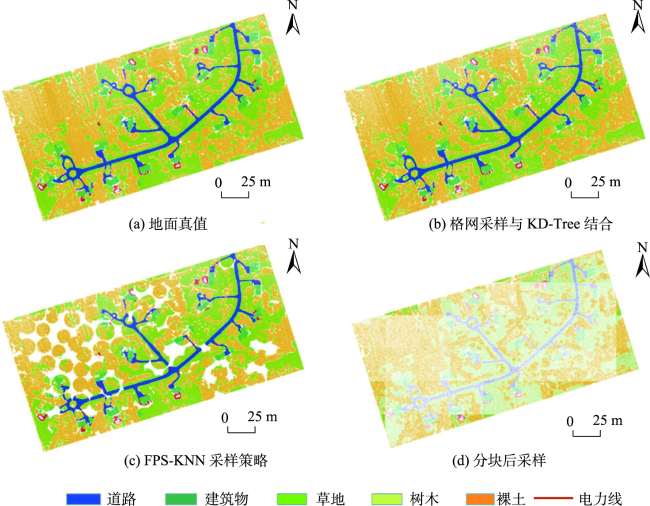
图7 训练场景1的3种采样方法结果与地面真值Fig. 7 Comparison between three sampling methods and ground truth on Train1 |
表6 使用3种采样方法的特征增强核点卷积网络的分类精度Tab. 6 EFConv. of different sampling strategy for classification accuracies |
| OA/% | mIoU/% | |
|---|---|---|
| 分块后采样 | 94.92 | 80.29 |
| FPS-KNN 采样策略 | 96.11 | 81.89 |
| 格网采样与KD-Tree结合 | 96.80 | 83.42 |
表7 单批次下采样时间Tab. 7 Downsampling time of a batch (ms) |
| 最远点采样 | 随机采样 | |
|---|---|---|
| 1st | 26 088.04 | 5.29 |
| 2nd | 1896.42 | 4.47 |
| 3rd | 291.06 | 3.97 |
| 4th | 33.02 | 3.89 |
| 5th | 13.00 | 3.72 |
表8 不同下采样方法的特征增强核点卷积网络的分类精度Tab. 8 EFConv. of different downsampling strategy for classification accuracies |
| OA/% | MIoU/% | |
|---|---|---|
| 5次随机采样 | 96.13 | 82.20 |
| 4次随机采样结合1次最远点采样 | 96.29 | 82.62 |
| 3次随机采样结合2次最远点采样 | 96.80 | 83.42 |
表9 特征增强核点卷积网络采用不同损失函数的分类精度Tab. 9 Classification accuracies from EFConv with varying loss functions |
| 损失函数 | 精度 | |||||
|---|---|---|---|---|---|---|
| 交叉熵损失 | 权重交叉熵损失 | 标签平滑损失 | Lovasz-Softmax 损失 | OA/% | mIoU/% | |
| 实验1 | √ | - | - | - | 95.26 | 78.16 |
| 实验2 | - | √ | - | - | 95.66 | 81.43 |
| 实验3 | - | - | √ | - | 95.71 | 81.38 |
| 实验4 | - | - | - | √ | 95.69 | 81.55 |
| 实验5 | - | √ | √ | - | 96.39 | 82.48 |
| 实验6 | - | - | √ | √ | 96.52 | 82.96 |
| 本文方法 | - | √ | √ | √ | 96.80 | 83.42 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
史硕, 龚威, 祝波, 等. 新型对地观测多光谱激光雷达及其控制实现[J]. 武汉大学学报(信息科学版), 2013, 38(11):1294-1297.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}